开源分布式文件存储 2018年一定要收藏的20款免费预测分析软件!(3)
电脑杂谈 发布时间:2018-02-14 11:25:11 来源:网络整理
▲
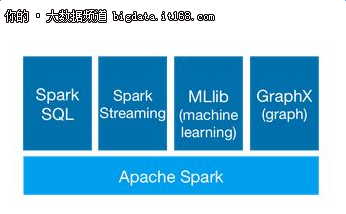
16.Apache Spark
Apache Spark是用于数据处理的快速且通用的引擎。Spark需要一个集群管理器和一个分布式存储系统。对于集群管理,Spark支持独立(本地Spark集群),Hadoop YARN或Apache Mesos。对于分布式存储,Spark能与各种各样的,包括Hadoop分布式文件系统(HDFS),MAPRA文件系统(FS-MAPRA),Cassandra,OpenStack Swift,亚马逊S3,Kudu,或自定义解决方案实现对接。
17.Octave
Octave是数字计算的高级解释语言。它提供了数据可视化和操纵的线性,非线性问题和图形的解决方案。有许多可用于公共数值线性代数解决问题的工具,寻找非线性方程的根,集成普通功能,操纵多项式,及整合的普通微分和代数微分方程。
▲
18.Tanagra
Tanagra是一个用于学术和研究目的的免费数据挖掘软件,它具有探索性数据分析,统计学习,机器学习和等多种数据挖掘方法的功能。支持标准的数据挖掘任务,如:可视化,描述性统计,实例选择,特征选择,功能建设,回归,影响因子分析,聚类,分类和关联规则的学习。
19.PredictionIO
PredictionIO是一款开源的机器学习服务器,可以让软件开发人员创建个性化,推荐和内容发现等预测功能。通过PredictionIO,预测这种特点的用户行为,提供个性化的视频,新闻,交易,广告,职位,事件,文件,应用程序,餐馆和匹配服务。
20.Apache Mahout
Apache Mahout提供可扩展的机器学习算法,主要集中在协作过滤,聚类和分类。许多实现使用Apache Hadoop平台,包括成熟的Hadoop MapReduce算法,Scala,Spark和H2O算法。协同过滤:基于用户的协同过滤,基于项目的协同过滤,矩阵分解与ALS,矩阵分解与隐式反馈和加权矩阵分解,SVD + ALS。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-77267-3.html
-

-
苟陇辉
沃尔玛呢
-
柳露
鼓励那些国家和中国对着干
 管理信息系统规划书 邵阳节能报告评估√宁夏
管理信息系统规划书 邵阳节能报告评估√宁夏 高性能计算技术是什么 在云计算的另一面,HPC+正在带来新的联想
高性能计算技术是什么 在云计算的另一面,HPC+正在带来新的联想 java中常见的死锁以及解决方法代码
java中常见的死锁以及解决方法代码 c语言程序设计课件下载ppt
c语言程序设计课件下载ppt
芝麻糊还有肉末