计算机的性能分类 机器学习笔记一
电脑杂谈 发布时间:2018-02-11 23:44:30 来源:网络整理
机器学习是研究如何通过计算的手段,通过经验来改善系统自身的性能。计算机的性能分类在计算机系统中,“经验”往往以“数据”的形式存在。
因此,机器学习研究的主要内容是在计算机上从数据产生“模型”的算法,即“学习算法”。将经验数据提供给算法,从而产生出“模型”,再次遇到新的数据时,“模型”能够给我们提供相应的判断结果。
数据集:要进行训练的数据的集合
示例/样本:数据集中的一条记录,描述了一个事件或者对象
属性/特征:事件或对象,在某方面的表现或性质,如西瓜的属性有 [颜色, 形状, 敲声, …]
属性值:属性对应的值
属性空间/样本空间/输入空间:将属性作为坐标轴,张开一个n维空间,每一个点都对应着一个坐标向量
特征向量:每个示例样本在样本空间里,也被称为特征向量
维数:属性的个数
学习/训练:从数据中学的模型的过程。这个过程通过执行学习算法来完成
训练数据/训练集:训练过程中使用的数据
训练样本:训练数据中的每个样本
假设:模型对应着的关于数据的某种潜在规律
真实/真相:潜在规律本身
学习器:模型的另一种叫法
预测:建立“预测”模型,需要训练样本的“结果”信息
标记:训练样本的“结果”信息,如((颜色:青绿,形状:圆形,敲声:浊响),好瓜)
样例:拥有标记的样本
分类:预测离散值,如“好瓜”,“坏瓜”
二分类:只涉及两个类别的分类,通常一个为正类,一个为反类

多分类:涉及多个分类
回归:预测连续值,如西瓜成熟度“0.95”“0.84”
聚类:将西瓜分为若干组,每一组称为“簇”
簇:对应着潜在的概念划分,有助于了解数据内在规律
监督学习:训练数据有标记,如分类和回归
无监督学习:训练数据没有标记,如聚类
泛化:学得的模型适用于新样本的能力
机器学习的目标是为了使学得的模型适用于新样本,而不是在训练样本上做的好
归纳和演绎是科学推理的两大手段
归纳:是从特殊到一般的泛化过程,从具体事实归结出一般规律
演绎:从一般到特殊的特化过程,从基础原理推演出具体状况
归纳学习:即从样例中学习,是归纳的过程
广义:从样例中学习
狭义:从训练数据中学得概念
假设空间:学习过程可以看做是一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到所有与训练集匹配的假设,假设的表示一旦确定,假设空间及其规模大小也将确定。如西瓜的假设空间由“(色泽=?)∧(形状=?)∧(敲声=?)”的可能取值所形成的假设组成
版本空间:可能有多个假设与训练集一致。这个与训练集一致的假设集合(假设空间的一部分),即是版本空间
归纳偏好:机器学习算法在学习的过程中对某种类型假设的偏好
错误率:分类错误样本数占样本总数的比例,即m个样本中有a个样本分类错误,错误率E=a/m
精度:1-a/m
误差:即实际预测输出与样本的真实输出之间的差异

训练误差/经验误差:模型在训练集上的误差
泛化误差:模型在新样本上的误差
过拟合:模型将训练样本学的太好,把训练样本自有的特点作为一般性质,导致泛化性能下降,它是机器学习的关键障碍,只能尽量缓解
欠拟合:模型对训练样本的一般性质没有学好
评估方法:
留出法:将数据集D划分为两个互斥的集合,其中一个作为训练集S,另一个作为测试集T,用S训练出模型,用T来评估测试误差,作为泛化误差的统计
交叉验证法:将数据集D划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的作为测试集,这样可以获得k组训练集/测试集,从而可以做k次训练和测试,最终返回k次测试的均值
留一法:若数据集D中包含m个样本,令k=m,每个子集只包含一个样本。留一法的评估结果往往比较准确,缺点是数据集较大时,计算的开销可能难以忍受
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-72634-1.html
-

-
杜欣悦
这谢作诗教授肯定喝醉了
-
陈鑫
而今迈步从头越
-
 【在鸟类频繁出没的地方,人们经常发现鸟类随时随地排泄粪便
【在鸟类频繁出没的地方,人们经常发现鸟类随时随地排泄粪便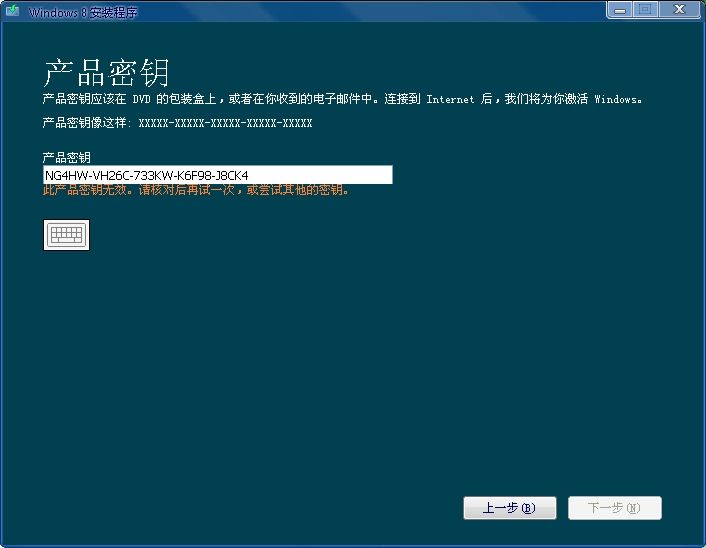 将Windows 8.1普通版无缝升级到版
将Windows 8.1普通版无缝升级到版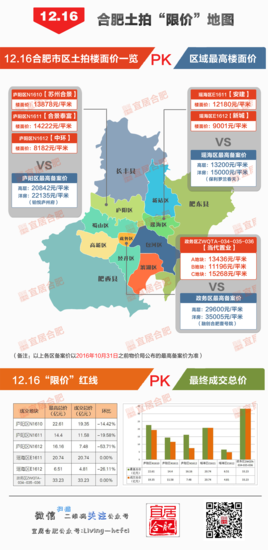 合肥只需要被祝福!高科技底价6K磁盘终于出现在5家知名房屋公司的发展中
合肥只需要被祝福!高科技底价6K磁盘终于出现在5家知名房屋公司的发展中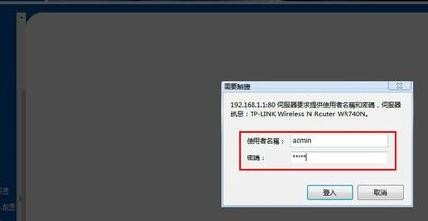 win7管理员用户权限选择更改用户帐户名的解决方法
win7管理员用户权限选择更改用户帐户名的解决方法
房价不降