网络爬虫是什么_网络爬虫原理_c#网络爬虫原理(2)
电脑杂谈 发布时间:2017-02-07 09:59:52 来源:网络整理基于内容的推荐(content-based filtering, 例如根据用户观看过的电影推荐其他与之相似的电影);
基于协同过滤的推荐(collaborative filtering,例如查看排行榜,或者找到和自己兴趣相似的用户,看看他们最近看什么电影)。
所以,可以用于构建推荐系统的信息也分为三类:好友、历史兴趣、注册信息。
推荐系统就是可以关联用户和物品的一种自动化工具。除了这些信息之外,时间、地点等信息均可加入到推荐系统的构建中来。现在,推荐系统已经广泛地应用于新闻推荐、图书推荐、音乐推荐、电影推荐、朋友推荐等领域,作为人工智能的一种形式,极大地方便了人们的生活和交往。
推荐系统算法的基础就是要构造相似性矩阵
这种相似性矩阵可以是物与物的相似性,例如书籍之间的相似性、音乐之间的相似性。以下以基于物品的协同过滤算法(item-based collaborative filtering, ItemCF)为例。基于物品的协同过滤算法可以利用用户的历史行为,因而可以使得推荐结果具有很强解释性。网络爬虫原理比如,可以给喜欢读足球新闻的用户推荐其它相似的新闻。基于物品的协同过滤算法主要分为两步:
STEP 1:计算物品之间的相似度。
STEP 2: 根据用户的历史行为生成用户的推荐列表。
假设有四个用户:
用户1在今日头条的浏览记录是[a、b、d],
用户2的浏览记录是[b、c],
用户3的浏览记录是[c、d],
用户4的浏览记录是[b、c、d];
可将这四个人的浏览行为表达为以下四个物品矩阵:
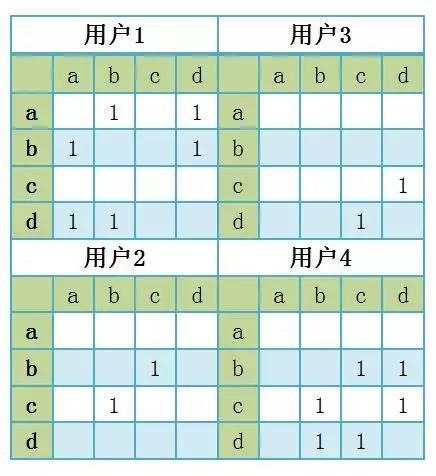
将个体用户的物品矩阵相加,可以汇总为所有的新闻矩阵M,M[i][j]表示新闻i和新闻j被多个人同时阅读的次数。如下所示:
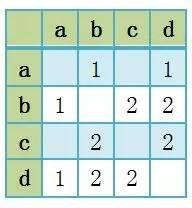
矩阵逻辑
如果两个新闻被多个人同时浏览,那么可以说它们之间的相似度更高。
将以上矩阵归一化就可以对矩阵进行操作并计算新闻之间的相似度,比如相关相似度或者余弦相似度。
基于物品间的相似性度,如果有一个新用户进入系统,并且他阅读了新闻c,那么ItemCF算法可以很快给出与新闻c相似度最高的新闻(b和d),并推荐给这个新用户。
在推荐过程中,推荐系统可以根据用户的行为不断优化相似矩阵,使得推荐越来越准确。
或者,如果用户可以手动对每个新闻的兴趣(如喜欢或讨厌)标出,就可以使得推荐更准确。
本质上来说,上面两个图是热点新闻、以及个人定制新闻的基础原理。它分为两步完成:
STEP 1:先找出新闻之间的热点与相似度
STEP 2:将热点与相似度高的新闻推送给用户。
举个栗子——
假设在抗战胜利70周年当天,有4个人同时浏览今日头条的新闻,
A是女读者,她点击了秋季糖水法、育儿应注意的五个事项、阅兵式、新型武器等新闻,
B是中年上班族,他点击了阅兵式、中国最新兵器谱等新闻,
C是一位年长者,他点击了养生、阅兵式、新型武器等新闻,
D是一位刚毕业的男大学生,他点击了英雄联盟攻略、好莱坞旅行攻略、阅兵式、新型武器等新闻。
热点和相似度的产生过程:
STEP 1:这四个人同时点击阅兵式和新型武器,系统算法就会通过点击和停留的时间计算出阅兵式和新型武器是当天的热点。
STEP 2:阅兵式和新型武器同时被点击,代表他们之间具有相似性。
STEP 3:当新进用户点击新闻时,今日头条会以最快速度分析他点击的内容,并在已经排查出的热点新闻当中寻找他所感兴趣的相关内容匹配给他,引导他阅读热点。
这一系列的行为都由计算机自动完成。
机制的缺陷
上面的例子说明了定制新闻以泛热点新闻为基础数据来完成的事实,这就出现一个问题,即当一个人关注的新闻不是热点时,系统得不到相关的热点,就会在该新闻当中寻找其他信息进行再匹配,这样匹配出的新闻在现有信息的基础上最大程度吻合了用户的兴趣,但未必会推送当天最热点的新闻。要想达到这种长尾理论所设想的定制服务,关键是对新闻的细分。只有将不同主题细分成各主题,再细分下设内容,才能达到真正的私人定制。要做到这一点,实际已经脱离了机械,而在于人对于事物性质的认知与把握。正如法国社会学家福柯在《知识考古学》当中的观点,分类,是一事物区别于其他事物的根本。而分类,归根结底是人的主观能动性的体现;当系统中累计的用户行为越 多,这种分类越准确,自动化的私人定制也会越贴近用户需求。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-31049-2.html
-

-
邵小飞
说得好
 太极熊猫源码_游戏编程_暗黑战神吧
太极熊猫源码_游戏编程_暗黑战神吧![[大力庆祝国庆节] c / c ++实现单个链接列表的创建,插入,删除,倒置和合并](http://images.cnitblog.com/blog/497634/201402/231248185524615.jpg) [大力庆祝国庆节] c / c ++实现单个链接列表的创建,插入,删除,倒置和合并
[大力庆祝国庆节] c / c ++实现单个链接列表的创建,插入,删除,倒置和合并 ug编程培训_江苏ug集训_苏州ug培训班
ug编程培训_江苏ug集训_苏州ug培训班 深圳市招财牛广告策划执行
深圳市招财牛广告策划执行
>我自愿为国家尊严而战