order 内存_开源内存_sqlite(3)
电脑杂谈 发布时间:2017-02-03 21:13:36 来源:网络整理4)分布式事务
切分架构带来分布式事务问题,对一些事务要求较高的场景,这颇具挑战。Ameoba 目前还在解决中。Ameoba + H2组合面临同样的挑战。
目前一种比较一致意见和做法就是冷处理——尽量不用事务。开源内存 一致性问题根据业务的特点,采用数据订正来解决;个别业务使用补偿事务。因为目前大部分应用,即便是核心业务,对事务的要求也不高。
9. 进一步思考
1) 多种数据切分模式
在一个大型互联网站,不同的应用和数据需要做不同的处理。开源内存在总体垂直切分模式基础上,选择数据量大的功能进行水平切分,例如:供求、订单、交易记录。
2)数据缓存(Data Cache)
虽然内存层(MDB)能更高效支撑交易型,特别是应对结构化应用及复杂查询服务,但对高频度的查询(Query)和实体查找(Find),Key-Value缓存仍然是一项必要的设计。Cache能提供更高的查询速度,并减少对MDB的访问压力,特别是读写密集的高并发场景。因为这个架构中,内存仍然作为一种存储Store,而不是Cache。
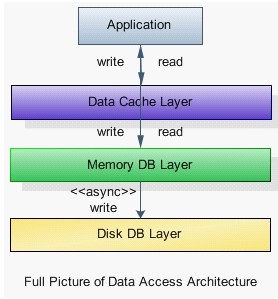
图7
上图展示了,MDB层之上还需要DCL层来提供高性能缓存服务。
10. 总结
本文提出了一种通过引入内存层,并建立两层,多分区的分布式架构。此方案用于解决海量高并发系统的高性能数据存储和访问问题,尤其是电子商务类等业务复杂的互联网站。其核心思想是:
1)高性能:是通过内存提供高性能关系存取服务,这是此架构的最主要目标;
2)持久化:通过两级及异步写完成持久化;
3)海量数据支撑:通过垂直和水平分区实现海量数据的支撑;
4)高可用性:在Ameoba基础上,通过主备节点进一步实现MDB的高可用性;二级磁盘可以实现数据的快速恢复。
【参考资料】
1. 阿里巴巴 Ameoba分布式设计和实践
2. 岳旭强, 《淘宝网架构师岳旭强的年度展望》,
3. 广东移动BOSS2.0分布式架构方案,计费系统设计和实践.
4. Cassandra,
5. Oracle, Timesten 官方文档,
6. Fenng,《Oracle 内存-TimesTen》,
7. 张澄,包文菖,《内存在BSS账务处理中的应用》,《计费&OSS世界》,
8. Titan,《常用内存介绍》,
9. Ricky Ho, 《NoSQL的模式》,程序员2010-1;《NoSQL 的查询处理》,程序员2010-2
问题:
这个模型是有很多可用场景的,楼主关于电子商务网站与SNS博客等网站的分析是很合理的,NOSQL在很多电子商务的场景下应用有局限,我们在搞国际交易的时候确实也遇到,特别是很多运营类的活动场景中,业务逻辑纠结的很。
以下有几个的疑问探讨下:
1)高性能:是通过内存提供高性能关系存取服务,这是此架构的最主要目标;
~~~~RMDB的工作让Ameoba 这个分布式代理在处理了。我认为最终的瓶颈会是AMEOBA,AMEOBA就是一个中心,扩展性怎么样,维护成本怎么样?为了实现切分和路由,很多数据还是依赖DB类的设备吧?
2)持久化:通过两级及异步写完成持久化;
~~~~~两级的数据一致性怎么保证?是最终一致性吗?同一个数据会复制几片?数据冗余策略可调吗?不同的应用场景对CPA的需求是不同,有些场景对数据一致性要求严一些,比如交易过程。
3)海量数据支撑:通过垂直和水平分区实现海量数据的支撑;
~~~~~如果需要通过拆分来实现数据扩展,那么海量的级别还是有很多约束的;加一台机器是不是要停机?重新分配拆分策略时所有机器的数据是不是要REOLAD?
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-30367-3.html
 为什么用C#编写richtextbox字体样式和字体大小随下
为什么用C#编写richtextbox字体样式和字体大小随下 auto病毒专杀工具?autoplay病毒?电脑无法重装cad2012?U盘病毒专杀工具 移动存储卫士
auto病毒专杀工具?autoplay病毒?电脑无法重装cad2012?U盘病毒专杀工具 移动存储卫士 C数据结构的通用树结构和二进制排序树的基本操作
C数据结构的通用树结构和二进制排序树的基本操作 计算机的起源和发展
计算机的起源和发展
如果没有蛆