order 内存_开源内存_sqlite
电脑杂谈 发布时间:2017-02-03 21:13:36 来源:网络整理
【摘要】 本文提出了一种通过引入内存层,建立两层多分区分布式架构。此方案用于解决海量高并发系统的数据存储和访问问题,尤其适用于电子商务等数据模型复杂且业务复杂的互联网站。
这些年互联网站发展迅猛,为应对海量数据下的高并发访问,产生了各种分布式架构设计思想,例如Key-Value引擎,数据分区等。而对于电子商务类网站,海量数据问题还有一个重要特点,就是数据结构化及数据之间的关联,淘宝如此,阿里巴巴也是如此,这是与社区、视频、博客等互联网站的显著差异。
1. NoSQL 是灵丹妙药吗?
NoSQL、Key-Value引擎如BigTable、Cassendra等在很多大型网站被采用,很好的解决了海量数据存储和访问问题。而对于电子商务类网站,Key-Value和NoSQL并不是解决此问题的灵丹妙药。最多它们仅能用于一些数据模型较为简单的应用。
原因有两个方面:
1)数据模型复杂
淘宝和阿里巴巴的会员、宝贝、供求、订单等核心实体数据模型复杂,属性个数几十到上百个。例如:会员(Member)就包含基本信息、联系、工商、账户等多个域的信息;另外,核心实体之间,实体与核心实体之间还存在复杂的关联。
2)业务复杂:
模型的复杂源于业务和逻辑的复杂。电子商务网站大量查询场景是结构化查询,例如:
在淘宝上查询“卖家在江浙沪,价格在50-200元的男士T恤”,
在阿里巴巴上“列出某个会员所有待发货的订单”
这类查询(当然,阿里巴)主要针对多个非主键字段, 即便对于BigTable、Cassandra 这样的基于Column的Key-Value,其简单的Query API还无法胜任此类需求。 因此在阿里巴巴和淘宝,Oracle、MySQL 等关系将仍然扮演重要角色。
2. MySQL 集群
引入K-V引擎等非关系无非是要解决海量数据在高并发环境下的高效读写问题,最大程度在可靠的持久化(Durable)与高访问性能 (Performance) 之间选择一个平衡点。在高度结构化系统中,同样的考虑驱使我们需要考虑另外的解决方案。
目前一种通行的做法是 MySQL 读写分离式集群,1个或少数Master写,多数Slave读,Master与Slave进行变更数据的同步。首先,这种方案经过大量的实践,可靠且可行。
然而,直接向DB执行写操作,仍然比较耗时(参见表1,表2),数据复制,也可能存在不一致延时的情形。是否还有更快的方案?
3. 内存型关系
可靠的持久化指数据存储到磁盘等设备上。图1展示了传统磁盘的基本访问模式。
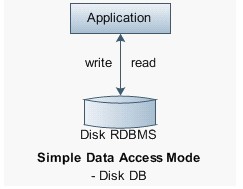
图1
抛开持久化的可靠性,即数据可以先不存储到磁盘上(Disk),内存存储的性能远高于磁盘存储。下表展示了针对Oracle和Altibase所做的性能对比,后者在插入和查询上性能是Oracle的5-7倍。
表1. Oracle、Altibase性能对比 -插入5万条 【7】
表2 Oracle、Altibase性能对比 –关联查询10万条【7】
由此可见:Pm >>> Pd
(Pm - 内存读写性能, Pd - 磁盘读写性能)
结合前面分析的模型复杂性和业务复杂性原因,关系(RDBMS)必须采用。因此,这两点考虑可以推导出另一个解决思路:内存型关系。
表3. DB选型对比分析
这个方案里,我们可以将内存先看做一种“磁盘”,读写操作都针对内存进行,不再直接与磁盘交互,这较好的避免了单纯MySQL 读写分离架构存在的时间延迟和一致性问题。如下图所示:
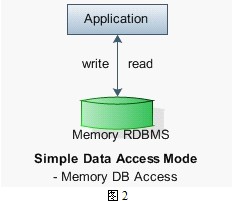
图2
4. 内存的持久化
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-30367-1.html
-

-
李振霞
四倍音速的鹰击导弹也部署南海
 电脑病毒黑客 互联网安全报告发布 二维码成网络诈骗“新武器”
电脑病毒黑客 互联网安全报告发布 二维码成网络诈骗“新武器” 合并资产负债表
合并资产负债表 台式电脑蓝屏如何开机从U盘启动设置兼容模式
台式电脑蓝屏如何开机从U盘启动设置兼容模式
 bat延迟命令大街网求职交流中心校园招聘讨论区内容——来自B
bat延迟命令大街网求职交流中心校园招聘讨论区内容——来自B
美国可以肆意践踏