分布式计算纯理论_分布式计算网络_分布式计算原理(6)
电脑杂谈 发布时间:2017-01-30 08:03:19 来源:网络整理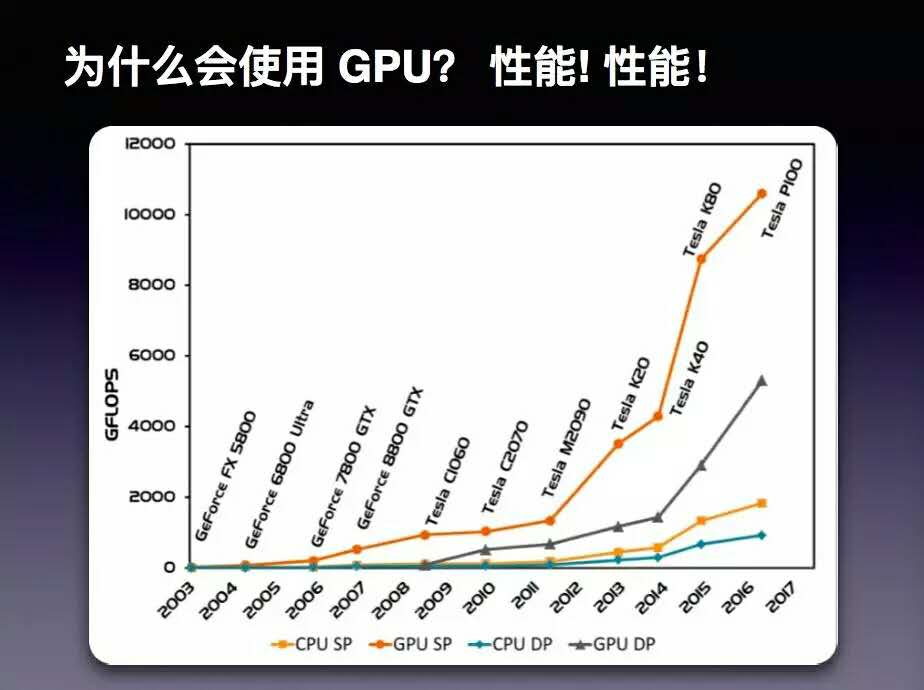
GPU并不是完全完美的方案!对于程序员来讲,我们也应该了解到它天生的不足。相比CPU,它仍然存在许多的局限。
首先,比如:这种技术需要绑定特定的硬件、对编程语言的有一定的限制。简单来说,开发的灵活性不如CPU。我们习惯的CPU已经帮助我们屏蔽掉处理了许多的硬件上细节问题,而GPU则需要我们直接面对这些底层的处理资源进行编程。
第二,在GPU领域不同厂商提供了不兼容的框架。应用的算法需要针对特定的硬件进行开发、完善。这也意味着采用了不同框架的应用对于计算环境的依赖。
第三,目前GPU是通过PCIe外部配件的方式和计算机集成在一起。众所周知,PCIe连接的频宽是很大的瓶颈,PCIe 3.0 频宽不过7.877 Gbit/s。考虑到计算需求较大的时,我们会使用显卡构成GPU的集群(SLI),这个频宽的瓶颈对于性能而言就是一个很大的制约。
最后,就是有限的内存容量的限制。现在Intel新推出的E7处理器的内存可以达到2TB。但是对于GPU而言,即使是Nvidia 的P100提供有16GB的内存,将四块显卡构成SLI(Scalable Link Intece)也只有64GB的显存容量。
如果你的模型需要较大的内存,恐怕就需要做更好的优化才可以满足处理的需要。这些都是GPU目前的缺陷和不足。我们在着手使用GPU这种技术和资源的时候一定要意识到这一点。
GPU除了硬件上具备了一定的优势以外,Nvidia还为程序员提供了一个非常好的开发框架-CUDA。利用这个编程框架,我们通过简单的程序语句就可以访问GPUs中的指令集和并行计算的内存。
对于这个框架下的并行计算内存,CUDA提供了统一管理内存的能力。这让我们可以忽略GPU的差异性。目前的编成接口是C语言的扩展,绝大多数主流编程语言都可以使用这个框架,例如C/C++、Java、Python以及.NET 等等。
今年的中秋节假期,我为自己DIY了一台深度学习工作站。起因是我买了一块GeForce GTX 1070显卡,准备做一些深度学习领域的尝试。因为我的老的电脑上PCIe 2.0 的插槽无法为新的显卡供电。不得已之下,只好更新了全部设备,于是就组装了一台我自己的深度学习工作站。
这个过程是充满挑战的,这并不仅仅是需要熟悉各个部件的装配。最重要的是要考虑很多细节的的搭配的问题。比如说供电的问题,要计算出每个单元的能耗功率。这里面又一个重要的指标就是TDP( Thermal Design Power)。Intel6850K的TDP值是140W,1070显卡的值是150W。
于是,系统搭配的电源就选择了650W的主动电源。其次,如果我们用多块显卡(SLI),就必须考虑到系统频宽的问题。普通的CPU和主板在这方面有很大局限。就我的最基本的需求而言我需要的最大的PCI Expres Lanes是40。这样算下来,Inteli7-6850K就是我能找到最便宜而且可以达到要求的CPU了。
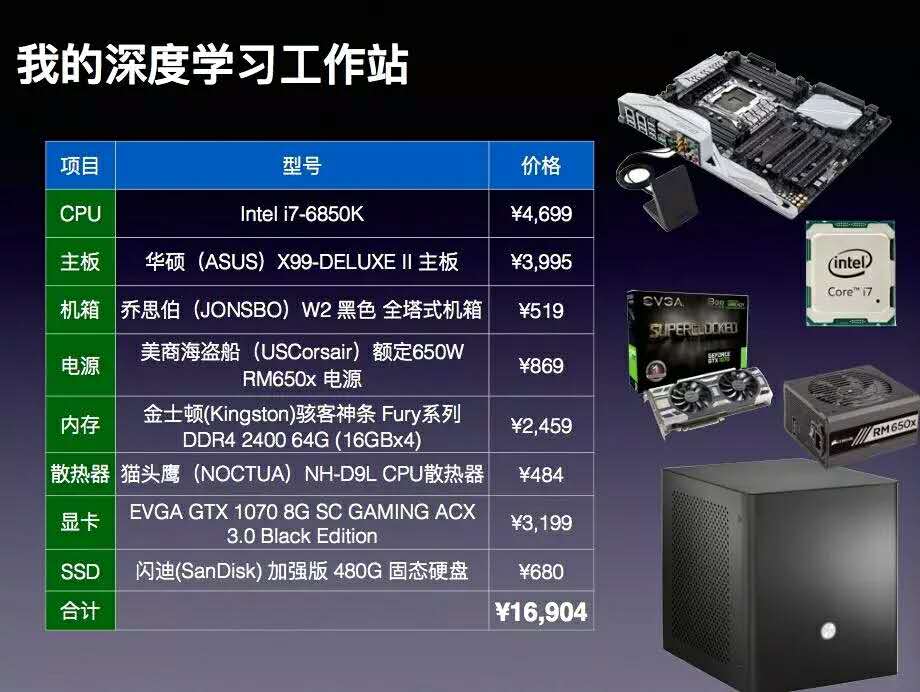
我在这两天的时间里,走了很多弯路,所以就想跟大家分享一下我的经验。
第一,Linux在显卡驱动的兼容性方面有很多问题。大多数Linux 分发版本提供的Nvidia显卡驱动是一个叫做Nouveau的开源版本的驱动。这个版本是通过逆向工程而开发的,对于新的Nvidia 的技术支持的很不好,所以一定要屏蔽这个驱动。
第二,Nvida的驱动以及CUDA合cuDnn 的配置上也有很多搭配的问题。官方的版本只提供了针对特定Linux 分发版本的支持。相比较而言,Ubuntu 16.04 在这方面表现的更出色一些。再有就是CuDNN需要在Nvidia 官网注册以后才可以下载。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-29530-6.html
-

-
田乡成
更不要学他
 发表论文需要审稿费吗 提交(多通葆)发表论文审核周期是多长时间
发表论文需要审稿费吗 提交(多通葆)发表论文审核周期是多长时间 您认为吃水果可以减轻体重吗?这5种高热量水果,吃后发胖!
您认为吃水果可以减轻体重吗?这5种高热量水果,吃后发胖! c语言简单图书管理系统_c语言图书管理系统简单_c语言图书管理系统程序设计
c语言简单图书管理系统_c语言图书管理系统简单_c语言图书管理系统程序设计 计算机病毒如何感染计算机?我们如何防止黑客入侵?
计算机病毒如何感染计算机?我们如何防止黑客入侵?
高喊着防杀伤性武器入侵伊拉克