揭示Java Web搜寻器程序的原理
电脑杂谈 发布时间:2020-07-31 23:04:53 来源:网络整理
随着Internet +时代的到来,越来越多的Internet公司层出不穷,涉及游戏,视频,新闻,社交网络,电子商务,房地产,旅游业和许多其他行业. 如今,互联网已成为海量信息的载体,如何有效地从中提取有价值的信息并加以利用已成为一个巨大的挑战
自从搜索引擎公司(如百度和谷歌)诞生以来,爬虫就一直存在. 如今,爬虫在移动互联网时代更加猖ramp. 每个网站似乎都曾经被它访问过,但是您不能,但是您可以放心,它不会做坏事. 您可以快速找到在Internet上找到的信息. 应该是它的功劳. 它每天都会在Internet上收集丰富的信息,以供大家查询和共享. 作为Internet开发的主流语言,Java被广泛用于Internet领域. 本课程使用Java技术来说明如何编写搜寻器以在Internet上搜寻有价值的数据信息.
知识点1.搜寻器简介
当我们访问某个网页时,在地址栏中输入URLjava爬虫原理,然后按Enter键. 网站的服务器将向我们返回一个HTML文件,浏览器将解析返回的数据并将其显示在UI上. 同样,搜寻器程序也模仿人的操作,向网站发送请求,网站将HTML文件返回给搜寻器程序,然后搜寻器程序将对返回的数据进行爬网和分析

爬虫简介
1.1爬行者简介

Web爬网程序(Web爬网程序),也称为Web spide自动检索工具(自动索引器),是“自动浏览Internet”的程序,或一种Web机器人.
搜寻器广泛用于Internet搜索引擎或其他类似网站中,以获取或更新这些网站的内容和检索方法. 他们可以自动收集他们可以访问的所有页面的内容,以供搜索引擎进行进一步处理(对下载的页面进行排序和排序),以便用户可以更快地检索所需的信息.
用外行人的术语来说,这意味着您可以手动打开窗口,输入数据等程序. 使用该程序获取您想要的信息,这是一个网络爬虫
1.2搜寻器应用程序1.2.1搜索引擎
搜寻器程序可以搜寻搜索引擎系统的网络资源,用户可以通过搜索引擎搜索网络上所需的所有资源. 搜索引擎是非常庞大且复杂的算法系统. 搜索的准确性和效率对搜索系统有很高的要求.

搜索引擎的原理

1.2.2数据挖掘

大数据分析
除了搜索外,爬虫还可以做很多工作. 可以说,爬虫现在已广泛用于Internet项目.
Internet项目主要通过爬取相关数据以获得价值数据来进行数据分析. 然后,搜寻器可以专门进行该分析,这是一个简单的理解:
应用下载分析1.3爬虫的原理1.3.1爬虫的目的
通常来说,我们需要抓取的是某个网站或某个应用程序的内容,提取有用的价值并进行数据分析.
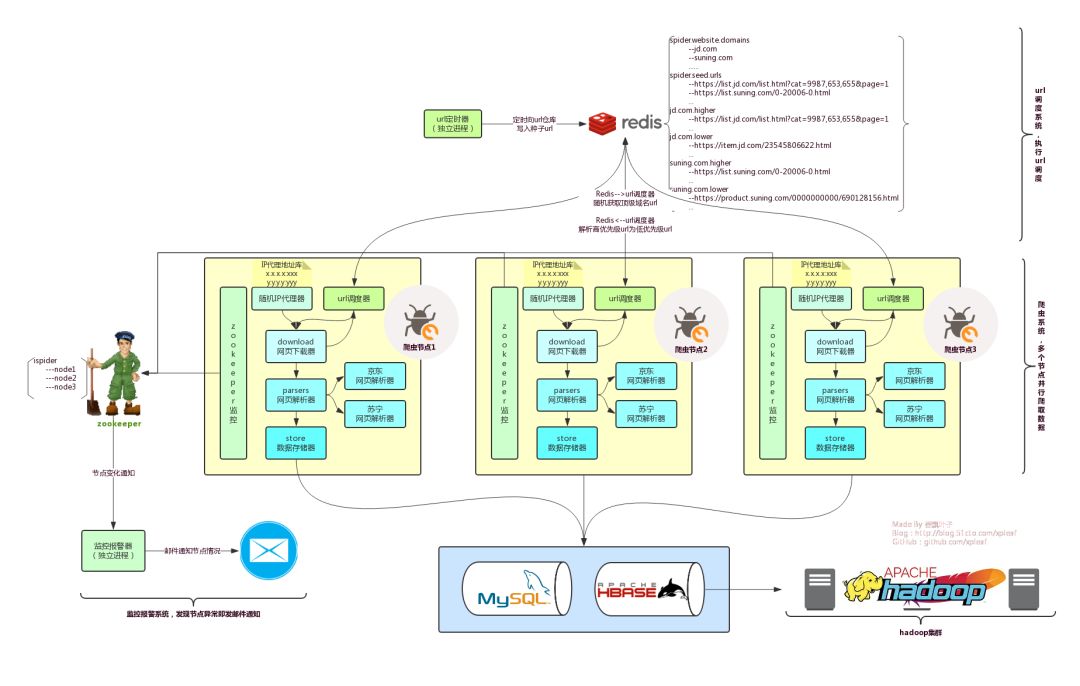
1.3.2履带式车架设计
为方便开发,您还可以使用搜寻器框架在项目中开发搜寻器;通用网络爬虫的框架如图所示:

Web crawler framework.png
网络搜寻器的基本工作流程如下:
首先选择一部分精心选择的URL,然后将这些URL放入要抓取的URL队列中. 从要爬网的URL队列中取出要爬网的URL,解析DNS,获取主机的IP,并获取与该网页对应的URL,将其下载并存储在下载的网页库中. 另外,将这些URL放入爬网URL队列中以分析爬网URL队列中的URL,分析其中的其他URL,然后将URL放入要爬网的URL队列中,从而进入下一个周期2. Java爬网程序框架2.1纳什
Nutch是分布式爬虫,该爬虫使用分布式爬虫,主要解决两个问题: 1)URL管理; 2)互联网速度. 如果您想成为搜索引擎,Nutch1.x是一个很好的选择. Nutch1.x可与solr或es一起使用以形成功能非常强大的搜索引擎,否则请不要选择Nutch作为搜寻器. 使用Nutch进行爬虫的二次开发时,准备和调试爬虫所需的时间通常是独立爬虫所需时间的十倍以上.

2.2 Heritrix
Heritrix是“ Archival Crawler”-获取网站内容的完整,准确,深层副本. 这包括获取图像和其他非文本内容. 抓取并存储相关内容. 没有内容被拒绝,也没有对页面进行任何内容修改. 重新抓取不会替换同一URL的前一个. 搜寻器主要通过Web用户界面启动,监视和调整,从而可以灵活地定义URL.
2.3 crawler4j
crawler4j是用Java实现的开源Web搜寻器. 提供一个简单易用的界面,您可以在几分钟内创建一个多线程Web搜寻器.
2.4 WebCollector
WebCollector使用Nutch的爬网逻辑(分层的遍历遍历),Crawler4j的用户界面(覆盖访问方法,定义用户操作)以及一组自己的插件机制来设计爬虫内核.
2.5 WebMagic
WebMagic项目代码分为两部分: 核心和扩展. 核心部分(webmagic-core)是简化的模块化爬网程序实现,而扩展部分包括一些便捷实用的功能. WebMagic的架构设计指的是Scrapyjava爬虫原理,目标是尽可能地模块化,并反映爬虫的功能特征.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-289526-1.html
-

-
张治宇
越南就是这种人
-
汪宏玲
人家做生意上来先给你个大金戒指
 win10怎么换成xp系统U盘启动盘制作工具
win10怎么换成xp系统U盘启动盘制作工具 发表论文需要审稿费吗 植物分类学SCI期刊有哪些
发表论文需要审稿费吗 植物分类学SCI期刊有哪些 OGNL表达研究笔记
OGNL表达研究笔记 1、计算机的软件基本上由哪五大部分组成
1、计算机的软件基本上由哪五大部分组成
可怜的伊叙人民