哈希一致性算法哈希环_redis一致性哈希算法_redis一致性哈希
电脑杂谈 发布时间:2017-01-26 05:02:09 来源:网络整理
像Memcache以及其它一些内存K/V一样,Redis本身不提供分布式支持,所以在部署多台Redis服务器时,就需要解决如何把数据分散到各个服务器的问题,并且在服务器数量变化时,能做到最大程度的不令数据重新分布。
通常使用的分布式方法是根据所要存储数据的键的hash与服务器数量N,按 hash % N 取模的算法来将数据分布到各个服务器。该算法的优点是足够简单,而且数据分布均匀。但是一旦服务器数量N发生变化的时候,缓存命中率会瞬间跌入谷底,因为绝大多数的数据需要重新分布。而且对于大型网站来说,此时会有巨大的压力涌向后端服务,可能会导致性能故障和服务故障,甚至宕机。
本文介绍什么是一致性哈希,为什么要使用以及如何使用一致性哈希算法实现Redis分布式部署,并且引入了虚拟节点以提高数据均匀分布的平衡性。最后还提供了一个故障转移策略,保证在部分服务器故障的时候能迅速恢复命中率,提高Redis服务的可用性和稳定性。
一致性哈希
由于hash算法结果一般为unsigned int型,因此对于hash函数的结果应该均匀分布在[0,2^32-1]区间,如果我们把一个圆环用2^32 个点来进行均匀切割,首先按照hash(key)函数算出服务器(节点)的哈希, 并将其分布到0~2^32的圆环上。
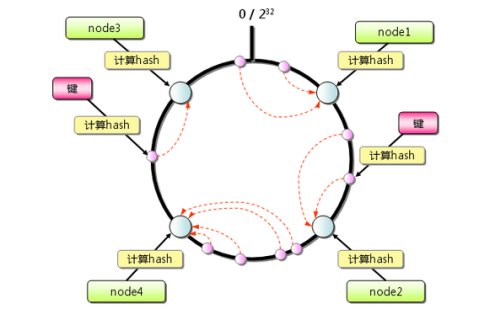
用同样的hash(key)函数求出需要存储数据的键的哈希,并映射到圆环上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器(节点)上。如图所示:
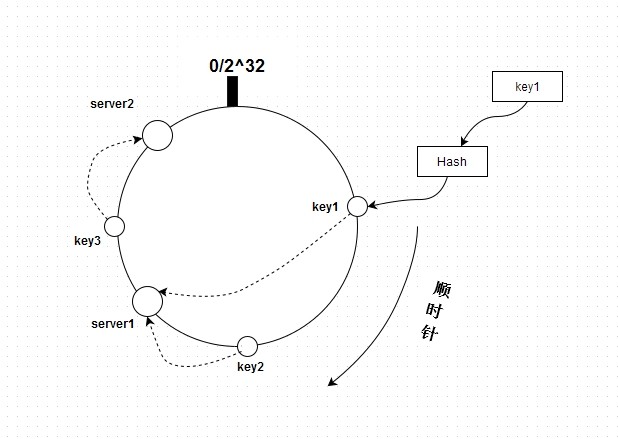
key1、key2、key3和server1、server2通过hash都能在这个圆环上找到自己的位置,并且通过顺时针的方式来将key定位到 server。按上图来说,key1和key2存储到server1,而key3存储到server2。如果新增一台server,hash后在key1 和key2之间,则只会影响key1(key1将会存储在新增的server上),其它则不变。redis一致性哈希算法
虚拟节点
在上图中,很容易看出一个问题,沿顺时针方向看,server2到server1之间的区间跨度大,而server1到server2的区间跨度小,这就会导致一个问题:数据分布不均匀。大部分数据都分配到server1了,只有小部分数据分布在server2。在服务器数据很少的时候,数据不均匀会表现的非常明显。
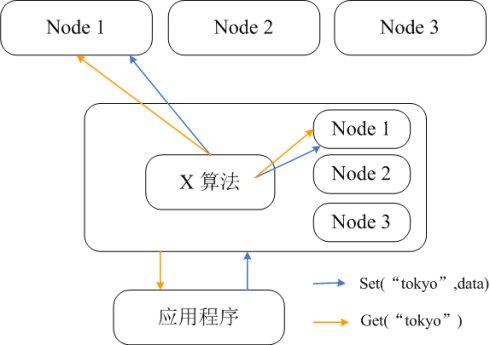
解决这个问题的方法是使用虚拟节点,一个真实服务器对应多个虚拟节点,所有虚拟节点按hash分布在一致性哈希圆环上。具体实现方法可以这样做,为真实服务器设置副本数量,然后根据各真实服务器的IP和端口号再加上一个递增的索引数计算hash。
class RedisCache {
public $servers = array(); //真实服务器
private $_servers = array(); //虚拟节点
const SERVER_REPLICAS = 10000; //服务器副本数量,提高一致性哈希算法的数据分布均匀程度
public function __construct( $servers ){
$this->servers = $servers;
//Redis虚拟节点哈希表
foreach ($this->servers as $k => $server) {
for ($i = 0; $i < self::SERVER_REPLICAS; $i++) {
$hash = crc32($server[host] . # .$server[port] . #. $i);
$this->_servers[$hash] = $k;
}
}
ksort($this->_servers);
// something else...
}
}
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-28756-1.html
-

-
尤晶晶
广东没蛆
 本地和嵌套类
本地和嵌套类 oltp和olap之间的区别
oltp和olap之间的区别 【平安二号·百日攻坚】win7自动关机怎么设置电脑图解
【平安二号·百日攻坚】win7自动关机怎么设置电脑图解 2018教师非师范 无锡市锡山区教育系统2018年招聘91名教师
2018教师非师范 无锡市锡山区教育系统2018年招聘91名教师
高喊着防杀伤性武器入侵伊拉克