黑马堂高手论坛手机网_2015黑马net基础就业班_黑马论坛基础分(4)
电脑杂谈 发布时间:2017-01-23 18:32:33 来源:网络整理(3)统计每日的独立的ip
hive> create table hmbbs_ip as
> select count(distinct iplog) as ip
> from hmbbs_table;(4)统计每日的独立的跳出率
hive> CREATE TABLE hmbbs_jumper AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(iplog) AS times FROM hmbbs_table GROUP BY iplog HING times=1) e ;到此获得了各个参数的结果:
hive> show tables;
OK
hmbbs_ip
hmbbs_jumper
hmbbs_pv
hmbbs_register
hmbbs_table
Time taken: 0.081 seconds
hive> select * from hmbbs_ip;
OK
10411
Time taken: 0.111 seconds
hive> select * from hmbbs_jumper;
OK
3749
Time taken: 0.107 seconds
hive> select * from hmbbs_pv;
OK
169857
Time taken: 0.108 seconds
hive> select * from hmbbs_register;
OK
28
Time taken: 0.107 seconds4、将hive分析的结果使用sqoop导出到mysql中
[root@hadoop11 mydata]# sqoop export --connect jdbc:mysql://hadoop11:3306/mydata --table hmresult --username root --password admin --export-dir /hmbbs_dir/ --fields-terminated-by '\t' -m 1 接下来我们在mysql中查看数据:
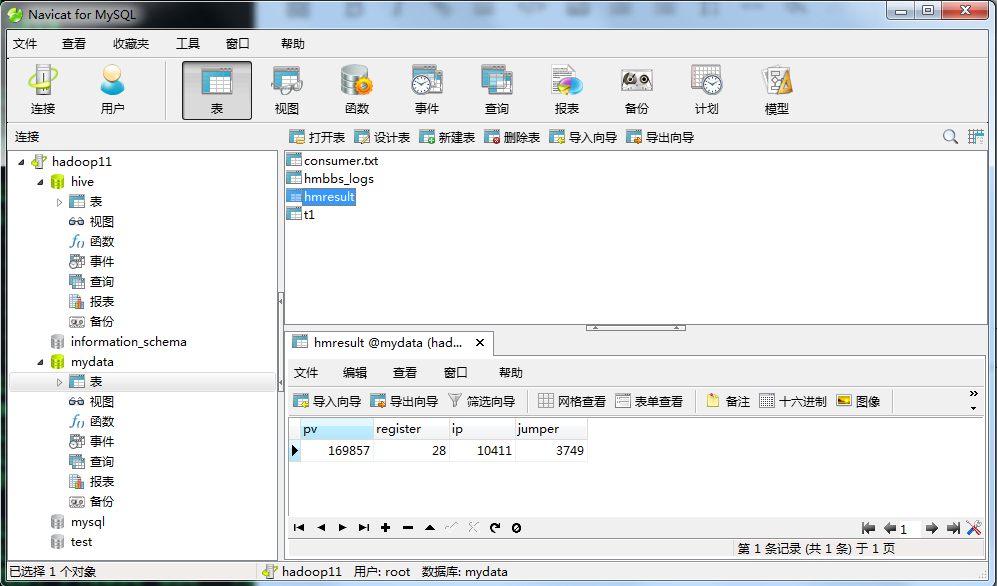
到此,基于Hadoop的黑马论坛日志就大致介绍完了,当然在项目的过程中还涉及到shell脚本编程,hbase应用,hadoop优化等部分,在这里不再详述。黑马论坛基础分
如有问题,欢迎留言!
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-28332-4.html
相关阅读
发表评论 请自觉遵守互联网相关的政策法规,严禁发布、暴力、反动的言论
-

-
杨宇航
看看英国多聪明
-
刘彤彤
TaobabyPanda
每日福利
 没有怎么怎么重装xp系统光驱记得光驱以前是双盘位
没有怎么怎么重装xp系统光驱记得光驱以前是双盘位 “ R语言数据挖掘”读书笔记: 六,高级聚类算法
“ R语言数据挖掘”读书笔记: 六,高级聚类算法 Win10美丽的焦点锁定屏幕壁纸下载列表(持续更新)
Win10美丽的焦点锁定屏幕壁纸下载列表(持续更新) win8 / 8.1网卡驱动程序通用脱机版本32位/ 64位
win8 / 8.1网卡驱动程序通用脱机版本32位/ 64位热点图片
大写的P