james_lbj(2)
电脑杂谈 发布时间:2020-06-21 14:04:25 来源:网络整理2>总结: 在64位编译器环境中,short占用2个字节(16位),int占据4个字节(32位),long占据8个字节(64位). 因此,如果使用的整数不是很大,则可以使用short代替int,这样可以节省内存开销.
3>世界上有很多编译器. 在不同的编译器环境中,int,short和long的值范围和长度是不同的. 例如,在16位编译器环境中,long仅占用4个字节. 幸运的是,ANSI \ ISO建立了以下规则:
4>可以连续使用两个long,即long long. 通常,long long的范围不少于long. 例如,在32位编译器环境中,long long占用8个字节,long占用4个字节. 但是,在64位编译器环境中,long long与long相同,并且占用8个字节.
5>还有一点要明确: short int等同于short,long int等同于long,long long int等同于long long
Long和int可以存储整数常量. 为了区分long和int,通常在整数常量(例如100l)之后添加小写字母l,该整数表示long类型常量. 如果是long long类型,则添加2 l,例如100ll. 如果不添加任何内容,则它是int类型的常量. 因此,100是int类型的常量,100l是long类型的常量,100ll是long long类型的常量.

1 int main()
2 {
3 int a = 100;
4
5 long b = 100l;
6
7 long long c = 100ll;
8
9 return 0;
10 }
除了占用的字节不同之外,变量a,b和c的最终存储值均为100. 变量a使用4个字节存储100,变量b和c使用8个字节存储100.

实际上,您可以直接将100分配给long类型的变量. 可以照常使用它. 因为100是int类型的常量,所以只要有4个字节就可以存储它,而long类型的变量b有8个字节,那么您可以肯定安装100.
1 int main()
2 {
3 long b = 100;
4
5 return 0;
6 }
1 #include <stdio.h>
2
3 int main()
4 {
5 long a = 100000000000l;
6
7 printf("%d\n", a);
8 return 0;
9 }
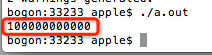
在第5行上定义了长型变量a,并尝试在第7行上输出a的值. 请注意,此处使用%d表示十进制整数格式的输出. %d将输出一个int类型. 它认为a为4个字节. 由于a是一个长类型,占用8个字节,但是当输出a时,仅会占用4个字节的内容用于输出,因此输出结果为:

再次获得传奇的垃圾数据
那么我们如何才能完全输出long类型?应该使用格式字符%ld
1 #include <stdio.h>
2
3 int main()
4 {
5 long a = 100000000000l;
6
7 printf("%ld\n", a);
8 return 0;
9 }
请注意,在第7行上,双引号是%ld,这表示将输出长型整数,此时的输出结果是:
如果是long long类型,则应使用%lld
1 #include <stdio.h>
2
3 int main()
4 {
5 long long a = 100000000000ll;
6
7 printf("%lld\n", a);
8 return 0;
9 }
1>首先要清楚的是: signed int等同于signed,unsigned int等同于unsigned
2>有符号和无符号之间的区别在于,是否应将其最高位用作符号位,并且不会改变数据长度(如short和long),即占用的字节数.
只知道有这样的事情.
1 unsigned char c1 = 10; 2 signed char c2 = -10; 3 4 long double d1 = 12.0;

让我们看一下以下操作之一
1 #include <stdio.h>
2
3 int main()
4 {
5 int a = 10;
6
7 double d = a + 9.5;
8
9 printf("%f \n", d);
10
11 return 0;
12 }
1>在第5行上定义了一个int类型的变量a,并分配了一个整数10.
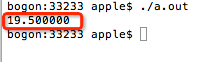
2>然后,将第7行的值10加上9.5的浮点数. 在这里,我们进行“加法”并将“ and”分配给d. 因此d的值应为19.5.

3>在第9行上使用格式字符%f输出浮点变量d. 默认情况下,保留6个小数位. 输出为:
4>这个看似简单的操作实际上包含一些语法细节. 严格来说,可以对相同数据类型的值进行运算(例如加法),而运算结果仍然是相同数据类型. 第7行的情况是: 变量a的值10是int类型(4个字节),而9.5是double类型(8个字节). 显然,10和9.5不是相同的数据类型. 可以说不允许添加10和9.5. 但是,系统将对占用较少内存的类型自动执行“自动类型升级”操作,这会将10提升为双精度类型. 也就是说,使用4个字节存储10,但是现在使用8个字节存储10. 因此,现在将10和9.5存储在8个字节中,它们都是double类型,然后可以执行该操作. 并将运算结果分配给double类型的变量d.
5>应当注意,在代码的第七行之后c语言字母对应ascii码,变量a始终为int类型,并且未变为double. 当定义变量时,什么类型是变量,那么它总是什么类型. “自动类型升级”仅在操作过程中进行.
1 int main()
2 {
3 float a = 10 + 3.45f;// int 提升为 float
4
5 int b = 'A' + 32; // char 提升为 int
6
7 double c = 10.3f + 5.7; // float 提升为 double
8
9 return 0;
10 }
1>注意,在第5行,系统会将字符“ A”提升为int类型数据,即将其转换为ASCII值“ A”,然后将其添加到32. ASCII值“” A'为65,因此变量b的值为65 + 32 = 97.
2>这种自动类型提升,只知道有这种事情,不需要记住此规则,因为系统会自动执行此操作.
让我们看一下下面的代码
1 #include <stdio.h>
2
3 int main()
4 {
5 int i = 10.7;
6
7 printf("%d \n", i);
8 return 0;
9 }
1>请注意,在第5行中,我们为仅具有4个字节存储空间的整数变量i分配了一个8字节浮点数10.7. 可以想象将8个字节填充为4个字节肯定会失去精度. 在第7行上输出变量i的值,输出为:
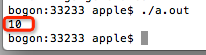
输出值为10,这是不可避免的.
2>还有一些语法细节. 实际上,第5行执行“强制类型转换”操作: 因为左侧是int类型的变量i,所以它将被迫将double类型的10.7转换为int类型. 10,并将转换后的值分配给整数变量i. 由于C语言没有严格的语法限制,因此系统将自动强制进行转换. 如果将其替换为另一种具有严格语法的语言,例如Java,则第五行代码已报告错误.
3>如果写得更严格,显然是“强制类型转换”,则应这样写:
1 #include <stdio.h>
2
3 int main()
4 {
5 int i = (int) 10.7;
6
7 printf("%d \n", i);
8 return 0;
9 }
请注意,在第5行上,在(10.7)前面添加了(int),这意味着它将转换为int类型数据. 这样,就不会有语法问题. 简而言之,将浮点数据转换为整数数据,将会丢失小数部分的值.
1 int main()
2 {
3 int a = 198l; // long 转换为 int
4
5 char b = 65; // int 转换为 char
6
7 int c = 19.5f; // float 转换为 int
8
9 return 0;
10 }
这种强制类型转换,只知道有这样的事情,不需要记住此规则,因为很多时候系统会自动执行此操作.
先前看到的强制似乎从“大字体”变为“小字体”. 实际上,这是不同的. 也可以将其从“小型”更改为“大型”
1 int main()
2 {
3 int a = 10;
4
5 double b = (double)a + 9.6;
6
7 return 0;
8 }
请注意第5行,将a的值强制转换为double类型后,再将其与9.6相加. 在这种情况下,系统不需要执行“自动类型升级”操作. 实际上,您不必强制执行此操作,因为系统将执行“自动类型提升”操作以将变量a的值提升为两倍. 您只需要知道这种用法,将来就会在某些地方使用它.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-253381-2.html
-
 丸山隼
丸山隼
 raspberry pi 当树莓派遇上NEC,物联网时代的显示器长什么样?
raspberry pi 当树莓派遇上NEC,物联网时代的显示器长什么样? 金山毒霸冲击波蠕虫特杀工具v1.1绿色版
金山毒霸冲击波蠕虫特杀工具v1.1绿色版 使用winrar自解压功能制作安装包
使用winrar自解压功能制作安装包 我的OUTLOOK2003,只能接受邮件不能发送.一群发就让输入网络密码.
我的OUTLOOK2003,只能接受邮件不能发送.一群发就让输入网络密码.