james_lbj
电脑杂谈 发布时间:2020-06-21 14:04:25 来源:网络整理
本文目录
C语言具有丰富的数据类型,因此它非常适合编写,例如DB2,Oracle等大型都是用C语言编写的. 其中,提供了四种最常用的基本数据类型: char,int,float,double,使用这些数据类型,我们可以定义相应的变量来存储数据. 在这种情况下,让我们深入研究有关基本数据类型的用法.
我们已经知道不同数据类型占用的存储空间是不同的. 例如,在64位编译器环境中,char类型占用1个字节,而int类型占用4个字节. 如果字节长度不同,则包含的二进制数字也不同,并且可以表示的数据范围也不同. 因此,int类型可以表示的数据范围肯定大于char类型. 以下是在64位编译器环境中int类型的值范围的简单计算.
int类型占用4个字节,因此总共为32位,则从逻辑上讲,值范围应为: 0000 0000 0000 0000 0000 0000 0000 0000 0000〜1111 1111 1111 1111 1111 1111 1111 1111,十进制为0〜232 -1. 但是int类型具有正负点c语言字母对应ascii码,包括正负数,那么如何表示负数呢?最高位用作符号位,最高位为0时为正数,最高位为1时为负数. 即: 1000 0000 1001 1011 1000 0000 1001 1011是负数,0000 1001 0000 1101 0000 1001 0000 1101是正数. 由于最高有效位是0代表正数,因此最大正数是0111 1111 1111 1111 1111 1111 1111 1111,即231-1. 最小的负数是1000 0000 0000 0000 0000 0000 0000 0000,这是-231(为什么是这个值?您可以根据上一章中提到的负数的二进制形式进行转换,请参阅1000 0000 0000 0000 0000 0000 0000 0000不是-231,您不必弄清楚,也不必担心,它不会影响代码编写,因此int类型的值范围为-231〜231-1.
注意: 该计算过程不是必须掌握的,您只需要知道该过程,就不必记住此结论,只需了解范围即可.
已经计算出了int类型的值范围,然后可以类推得出其他数据类型的值范围.

(注意: 由于float和double是十进制,因此它们的存储方法特别不同,因此它们的值范围的算法也非常不同. 我在这里不再介绍它们,也不需要掌握它们. 表示乘以10. 对于38的幂,e-38表示减去38的幂乘以10. )
上面的列表仅适用于64位编译器环境. 如果您的编译器是16位或32位,则这些数据类型的值范围肯定不同. 例如,在16位编译器环境中,int类型占用2个字节,总共16bit,因此int类型的值范围是-215〜215-1.
如我们先前所见,每种数据类型都有其自己的值范围. 如果为变量分配的值超出该值范围,则后果将难以忍受.

1 #include <stdio.h>
2
3 int main()
4 {
5 int c = 1024 * 1024 * 1024 * 4;
6
7 printf("%d\n", c);
8 return 0;
9 }
我们都知道int类型可以容纳的最大值是231-1. 在第5行: int类型的变量c中分配一个大于231-1的值: 232(1024为210)
首先查看终端中的输出:
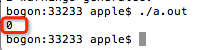
,您可以看到输出值为0.
我们可以简单地分析为什么将232分配给变量c且输出为0. 232的二进制形式为: 1 00000000000000000000000000000000000000,总共33个二进制数. 变量c占用4个字节,并且只能保存32位二进制数,并且内存寻址从大到小. 因此,变量c在内存中的存储形式为0000 0000000000000000000000000000,即0,第一个1不属于变量c.

可以发现,如果超出变量的值范围,则准确性将丢失,并且将获得“垃圾数据”(“垃圾数据”是指我们不想要的数据). 但是,有时我们确实需要存储一个非常大的整数,该整数大于231-1,我们该怎么办?这需要使用类型说明符,这将在本讲座的后面进行讨论.
char是C语言中一种更灵活的数据类型,称为“字符类型”. 由于它被称为“字符”,因此必须用于存储字符,因此我们可以将字符常量分配给字符变量.
1 #include <stdio.h>
2
3 int main()
4 {
5 char c = 'A';
6
7 printf("%c\n", c);
8 return 0;
9 }
第5行,定义了一个char变量c,并将字符常量'A'分配给c. 在第7行,字符变量c输出到屏幕,%c表示以字符格式输出.
输出结果:

1>以下措辞有误:
1 int main()
2 {
3 char c = A;
4 return 0;
5 }
编译器将直接在第3行报告错误. 错误的原因是: 找不到标识符A. 您直接写一个大写的A,编译器会认为A是一个变量. 因此,在代码的第三行前面编写“ A”或定义名为char的类型为char的变量是正确的.
2>以下内容也是错误的:

1 int main()
2 {
3 char c = "A";
4 return 0;
5 }
第3行中的“ A”不是字符常量,而是字符串常量. 将字符串“ A”分配给字符变量c是错误的. 字符串和字符的存储机制不同,因此“ A”和“ A”本质上是不同的.
字符变量占用1个字节,共8位,所以取值范围是-27〜27-1. 在此范围内,可以将字符变量用作整数变量.
1 #include <stdio.h>
2
3 int main()
4 {
5 char c1 = -10;
6
7 char c2 = 120;
8
9 printf("c1=%d c2=%d \n", c1, c2);
10 return 0;
11 }
因为在第9行中使用了%d,这意味着以十进制整数格式输出,并且输出结果为:
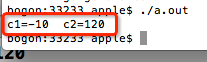
. 因此,如果使用的整数不是很大,则可以使用char代替int,这样可以节省内存开销.
实际上有两种类型的字符: 单字节字符和双字节字符.
一个字符变量仅占用1个字节,因此一个字符变量只能存储1个单字节字符.
以下措辞有误:
1 #include <stdio.h>
2
3 int main()
4 {
5 char c = 'ABCD';
6
7 printf("%c\n", c);
8 return 0;
9 }
编译器将对以上代码发出警告,并且不会报告错误,因此程序仍可以运行. 由于变量c只能存储1个单字节字符,因此最终变量c仅将'D'存储在'ABCD'中.
输出结果:

在内存中,需要将1个汉字存储2个字节,并且1个字符变量仅占用1个字节的存储空间,因此该字符变量不能用于存储汉字.
以下措辞有误:
1 int main()
2 {
3 char c = '男';
4 return 0;
5 }
编译器将直接在第3行报告错误. 请记住一个原则: 单引号必须是单字节字符.
在字符方面,您必须提及ASCII的概念
1> ASCII是基于拉丁字母的计算机编码系统. 它是当今最常见的单字节编码系统. 全名是“美国信息交换标准代码”. 编码系统似乎非常先进,但是它实际上是一个字符集---字符集.
2> ASCII字符集包括: 所有大写和小写英文字母,数字0到9,标点符号以及一些特殊的控制字符: 例如,退格,删除,制表,回车,总共128个字符,全部是“单字节字符”.
3>计算机中的任何数据都以二进制形式存储,因此每个ASCII字符都以二进制形式存储在内存中,并且仅占用1个字节,该二进制数的值称为ASCII字符的ASCII值. 例如,内存中大写字母A的二进制形式为: 0100 0001,则其ASCII值为65.
4>以下是ASCII码字符表,ASCII码值的范围为0〜127
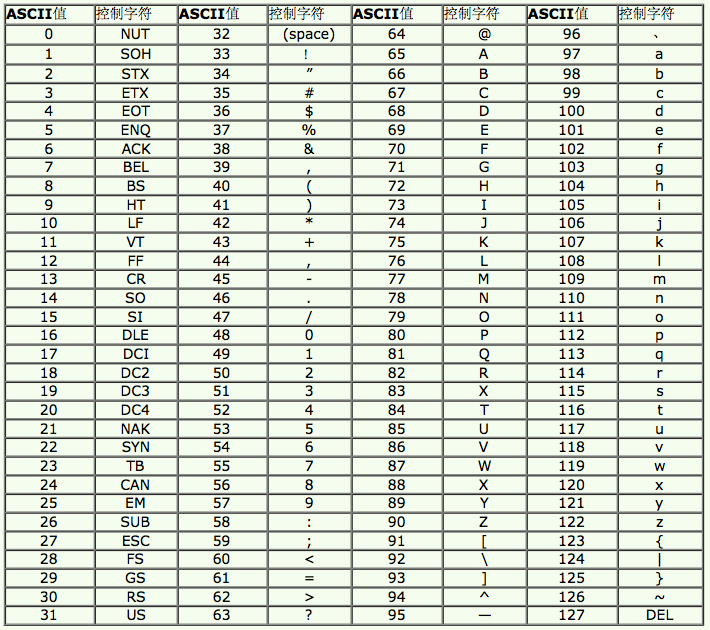
5>我们都知道char类型变量仅占用1个字节的存储空间,并且所有ASCII字符都是单字节字符,因此char类型变量可以存储任何ASCII字符. 使用char类型变量存储ASCII字符时,可以直接使用ASCII字符,也可以使用ASCII值.
1 #include <stdio.h>
2
3 int main()
4 {
5 char c1 = 65;
6
7 char c2 = 'A';
8
9 printf("c1=%c c2=%c \n", c1, c2);
10 return 0;
11 }
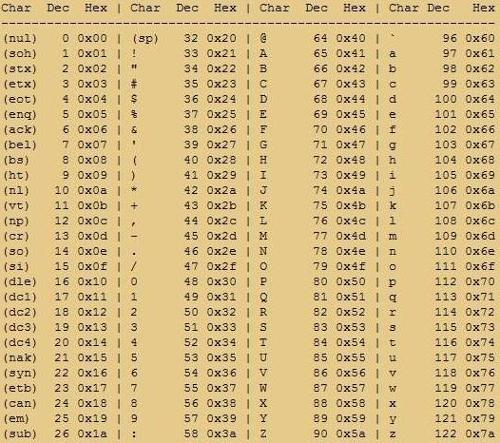
字符变量c1和c2分别在第5行和第7行中定义. 显然,变量c2存储ACII字符'A';变量c1存储65,并且与ASCII值65对应的ASCII字符为'A',因此变量c1也存储'A'.
由于第9行使用%c,这意味着以字符格式输出,因此输出结果:

5>在上面的示例之后,您应该知道6和'6'之间的区别
1 #include <stdio.h>
2
3 int main()
4 {
5 char c1 = 6;
6
7 char c2 = '6';
8
9 printf("c1=%d c2=%d \n", c1, c2);
10 return 0;
11 }
第5行将整数6分配给变量c1,第7行将字符'6'分配给变量c2,ASCII值'6'为54.
因为在第9行中使用了%d,这意味着以十进制整数格式输出,并且输出结果为:

1>我们已经知道在64位编译器环境中,一个int变量的值范围为-231〜231-1,最大值为231-1. 有时,我们要使用的整数可能大于231-1,例如整数234. 如果您坚持使用int类型变量来存储此值,则将失去精度并获取垃圾数据. 为了解决这个问题,C语言允许我们向int类型的变量添加一些说明符. 一些说明符可以增加int类型变量的长度. 在这种情况下,可以由int类型的变量存储的数据范围会变大.
2> C语言提供了以下4个说明符,其中4个是关键字:
根据用法分类,短和长是一种类型,有符号和无符号是一种类型.
这些说明符通常用于修改int类型,因此您可以在使用int时省略int
1 // 下面两种写法是等价的 2 short int s1 = 1; 3 short s2 = 1; 4 5 // 下面两种写法是等价的 6 long int l1 = 2; 7 long l2 = 2; 8 9 // 可以连续使用2个long 10 long long ll = 10; 11 12 // 下面两种写法是等价的 13 signed int si1 = 3; 14 signed si2 = 3; 15 16 // 下面两种写法是等价的 17 unsigned int us1 = 4; 18 unsigned us2 = 4; 19 20 // 也可以同时使用2种修饰符 21 signed short int ss = 5; 22 unsigned long int ul = 5;
1>第2行的short int和第3行的short等效.
2>看第10行,可以连续使用两个多头. long的作用将在后面说明.
3>注意,在第21和22行上,可以同时使用两个不同的说明符. 但是,不能同时使用相同类型的修饰符,这意味着不能同时使用short和long或不能同时使用有符号和无符号.
1> short和long可以提供不同长度的整数,即可以更改整数的范围. 在64位编译器环境中,int占用4个字节(32位),值范围为-231〜231-1; short占用2个字节(16bit),取值范围为-215〜215-1; long占用8个字节(64位),取值范围-263〜263-1
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-253381-1.html
-

-
周杰
喜欢外景这组有点胶片复古的感觉没有雪梨略不开心
-
 山东不同地区的公积金跨区域转移,山东从山东其他地方购买资金的政策
山东不同地区的公积金跨区域转移,山东从山东其他地方购买资金的政策 c语言入门自学_c语言入门经典怎么样_c语言入门经典 第5版
c语言入门自学_c语言入门经典怎么样_c语言入门经典 第5版 使用IBM中间件实施SaaS解决方案,第1部分
使用IBM中间件实施SaaS解决方案,第1部分 Teradata CTO宝立明:运用预测引擎推动机器学习和深度学习
Teradata CTO宝立明:运用预测引擎推动机器学习和深度学习
活着还有什么意思