干货: 了解网络爬虫的原理和技术的文章(值得收藏)
电脑杂谈 发布时间:2020-06-07 21:28:09 来源:网络整理
01
网络抓取工具实施原理的详细说明
不同类型的Web爬网程序具有不同的实现原理,但是这些实现原理存在许多共性. 在这里,我们将以两个典型的Web爬网程序为例(即一般的Web爬网程序和聚焦的Web爬网程序)分别说明Web爬网程序的实现原理.
1. 通用网络抓取工具
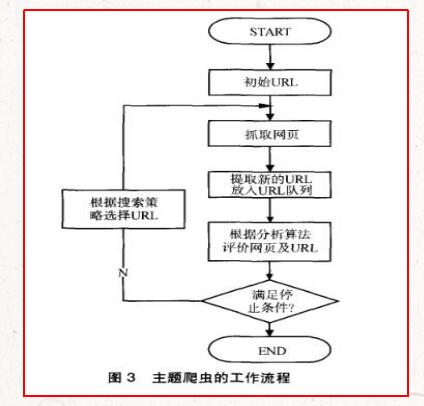
首先,让我们看一下常规Web搜寻器的实现原理. 通用Web爬虫的实现原理和过程可以概括如下(见图3-1).
▲图3-1 Universal Web Crawler的实现原理和过程
获取初始URL. 初始URL地址可以由用户手动指定,也可以由用户指定的一个或几个初始爬网网页确定.
根据初始URL,对页面进行爬网并获得新的URL. 获取初始URL地址后,首先需要在相应的URL地址中对网页进行爬网. 在使用相应的URL地址对网页进行爬网之后,该网页将存储在原始中,而在对网页进行爬网时,将找到一个新的URL地址,同时将爬网的URL地址存储在URL列表中,用于重复数据删除和判断爬网过程.
将新的URL放入URL队列中. 在第2步中,获取下一个新的URL地址后,新的URL地址将被放置在URL队列中.
从URL队列中读取新URL,根据新URL对网页进行爬网,同时从新网页中获取新URL,然后重复上述爬网过程.
满足搜寻器系统设置的停止条件后,停止搜寻. 编写搜寻器时,通常会设置相应的停止条件. 如果未设置停止条件,则搜寻器将继续搜寻,直到无法获取新的URL地址为止. 如果设置了停止条件,则在满足停止条件时,爬虫将停止爬网.
以上是一般Web搜寻器的实现过程和基本原理. 接下来,我们将为每个人分析Web爬网程序的基本原理和实现过程.
2. 专注于网络爬虫
关注网络爬虫. 由于需要有目的地对它们进行爬网,因此对于一般的Web爬网程序而言,有必要增加目标的定义和过滤机制. 具体而言,此时,它的执行原理和过程需要更加通用. Web搜寻器还有三个步骤网络爬虫的工作原理,即目标的定义,不相关链接的过滤以及下一步要搜寻的URL地址的选择,如图3-2所示.
▲图3-2着重介绍Web爬虫的基本原理和实现过程
02
爬行策略
在网络爬网程序的爬网过程中,可能要爬网的URL列表中可能有很多URL地址,那么该爬网程序应首先爬网哪些URL地址,然后再爬网哪些爬网?
在一般的Web爬网程序中,尽管爬网的顺序并不那么重要,但是在许多其他爬网程序(例如聚焦的Web爬网程序)中,爬网的顺序非常重要,并且爬网的顺序通常由爬网策略确定. 我们将介绍一些常见的抓取策略.
爬网策略主要包括深度优先爬网策略,广度优先爬网策略,大站点优先级策略,反链策略和其他爬网策略. 下面我们将分别介绍它们.
如图3-3所示,假设有一个网站,ABCDEFG是该网站下方的网页,图中的箭头表示该网页的层次结构.
▲图3-3网站的网页层次结构
如果此时ABCDEFG网页处于抓取队列中,则抓取顺序会根据不同的抓取策略而有所不同.
例如,如果按照深度优先的爬网策略进行爬网,则将首先对网页进行爬网,然后对该网页的下部链接进行深度爬网,然后返回到上一层进行爬网.
因此,根据深度优先爬行策略,图3-3中的爬行顺序可以是: A→D→E→B→C→F→G.
如果按照广度优先爬网策略进行爬网,则将首先对同一级别的网页进行爬网. 对同一级别的所有网页进行爬网后,选择下一个要爬网的网页,例如,在上述网站中,如果按照广度优先的爬网策略进行爬网,则爬网的顺序可以为: A→B→C→ D→E→F→G.
除了以上两种爬网策略外,我们还可以使用大站点爬网策略. 我们可以对相应网页所属的网站进行分类. 如果网站上有大量网页,则我们将其称为大型网站. 根据此策略,网页数越大,网站越大. 然后,先爬网. 大型网站中网页的URL地址.
网页的反向链接数是指该网页被其他网页指向的次数. 该次数表示该网页被其他网页推荐的次数. 因此,如果按照反链策略进行爬网,则该网页上的反链数量越多,该网页将首先被爬网.
但是,在实际情况中,如果仅通过反链策略确定网页的优先级,则可能会发生大量欺诈行为. 例如,创建一些垃圾站并将这些站点彼此链接. 如果是这样,每个站点都会获得更高的反链,从而达到作弊的目的.
作为爬虫项目,我们当然不希望被这种作弊打扰,因此,如果我们使用反向链接策略进行爬虫,则通常会考虑可靠的反链条的数量.
除了上述爬网策略外,实践中还有许多其他爬网策略,例如OPIC策略和Partial PageRank策略.
03
网页更新策略
网站页面经常被更新. 作为搜寻器,在更新页面后,我们需要重新搜寻这些页面,那么什么时候才适合搜寻?如果网站更新太慢,并且爬网程序爬网太频繁,它将不可避免地增加爬网程序和Web服务器的压力. 如果网站更新速度较快,但是爬网程序的爬网时间间隔较长,则我们爬网的内容版本将太旧,不利于爬网新内容.
很明显,网站的更新频率越接近爬虫对网站的访问频率,效果就越好. 当然,当爬虫服务器资源有限时,爬虫还需要根据相应的策略使不同的网页具有不同的更新优先级. 级别高的优先级网页更新将获得更快的爬网响应.
具体来说,主要有三种网页更新策略: 用户体验策略,历史数据策略,聚类分析策略等,我们将在下面分别进行解释.
当搜索引擎查询关键字时,将显示排名结果. 在排名结果中,通常会有大量的网页. 但是,大多数用户只会关注排名靠前的网页. 当搜寻器服务器的资源有限时,搜寻器将优先更新排名最高的网页.
此更新策略,我们称为用户体验策略,因此在此策略中,搜寻器何时爬网这些排名最高的页面?此时,将在爬网过程中保留相应网页的多个历史版本,并且将根据内容更新,搜索质量影响,用户体验以及这些多个历史版本的其他信息,执行相应的分析以确定这些网页的爬网周期.
此外,我们还可以使用历史数据策略来确定爬网网页更新的周期. 例如,我们可以通过泊松过程建模等方法,基于某个网页的历史更新数据,来预测该网页的下一个更新时间,从而确定该网页的下一个爬行时间,即更新周期.
以上两种策略都需要历史数据作为基础. 有时,如果网页是新网页,将没有相应的历史数据,并且如果您要基于历史数据进行分析,则需要保存相应网页的历史版本信息,这无疑会带到搜寻器服务器. 更多压力和负担.
如果要解决这些问题,则需要采用新的更新策略. 更加常用的是聚类分析策略. 那么什么是聚类分析策略?
在生活中,我相信每个人都对分类非常熟悉. 例如,当我们去商场时,商场中的产品通常被分类,方便顾客购买相应的产品. 目前,商品分类的类别已固定.
但是,如果产品数量巨大并且无法提前对其进行分类,或者如果您不知道将拥有哪些产品类别,那么我们应该如何解决产品分类问题?
这时,我们可以使用聚类解决问题. 根据产品之间的共性,进行相应的分析,将相似度更高的产品归为一类. 此时,产品类别的数量不必相同. 但是可以保证的是,聚集在一起的商品之间必须有一定的共通性,即基于``事物聚在一起''的思想来实现它.
类似地,在我们的聚类算法中,会有类似的分析过程.
集群分析算法用于爬网程序更新网页,如图3-4所示.
▲图3-4网页更新策略的聚类算法
以上是使用搜寻器搜寻网页时的三种常见更新策略. 掌握了爬虫的算法思想之后,按照爬虫的实际发展,书面爬虫的执行效率将会更高. 而且执行逻辑将更加合理.
04
网页分析算法
在搜索引擎中,爬网相应的网页后,爬网程序会将网页存储在服务器的原始中. 之后,搜索引擎将分析这些网页并确定每个网页的重要性,这将影响用户检索到的排名结果.
因此,在这里,我们需要对搜索引擎的网络分析算法有一个简单的了解.

搜索引擎网页分析算法主要分为三类: 基于用户行为的网页分析算法,基于网络拓扑的网页分析算法和基于网页内容的网页分析算法. 接下来,我们将分别解释这些算法.
1. 基于用户行为的网页分析算法
基于用户行为的网页分析算法相对容易理解. 在此算法中,将基于用户对这些网页的访问行为(例如,基于用户访问该网页的频率,用户对该网页的访问时间以及用户的访问次数)等信息来评估这些网页点击率. 评价.
2. 基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是一种通过依赖网页的链接关系,结构关系,已知网页或数据来分析网页的算法. 所谓的拓扑仅表示结构关系.
基于网络拓扑的网页分析算法也可以分为三种: 基于网页粒度的分析算法,基于网页块粒度的分析算法和基于网站粒度的分析算法.
PageRank算法是基于网页粒度的典型分析算法. 我相信很多朋友都听说过Page-Rank算法,这是Google搜索引擎的核心算法. 简而言之,它将根据网页之间的链接关系来计算网页的权重,并且可以依靠这些计算出的权重. 页面排名.
当然,有很多特定的算法细节,因此在此不再赘述. 除了PageRank算法,HITS算法还是基于网页粒度的常用分析算法.
还通过网页之间的链接关系来计算基于网页块粒度的分析算法,但是计算规则不同.
我们知道一个网页通常包含多个超链接,但通常并非它指向的所有外部链接都与网站的主题有关,或者这些外部链接对网页的重要性是不同的,因此,如果要基于网页的块粒度进行分析,则需要将网页中的外部链接划分为多个层,并且不同级别的外部链接对该网页的重要性级别也不同.
该算法的分析效率和准确性将优于传统算法.
基于网站粒度的分析算法也类似于PageRank算法. 但是,如果分析基于网站粒度,则将相应地使用SiteRank算法. 也就是说,此时,我们将划分站点的层次结构和等级,而不再专门计算站点下每个网页的排名.
因此,与基于网页粒度的算法相比,它更加简单,高效,但是会带来一些弊端,例如准确性不如基于网页粒度的分析算法那么准确. 页面.
3. 基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,将根据网页数据,文本和其他网页内容特征对网页进行评估.
上面,我向所有人简要介绍了搜索引擎中的网页分析算法. 我们学习爬虫,并且需要相应地了解这些算法.
05
标识

在搜寻器搜寻网页的过程中,搜寻器必然需要访问相应的网页. 常规搜寻器通常会将其对应的搜寻器身份告知相应网页的网站管理员. 网站的管理员可以通过搜寻器通知的身份信息来识别搜寻器的身份. 我们将此过程称为搜寻器的识别过程.
那么,抓取工具应如何告知网站管理员其身份?
通常,在爬网和访问网页时,爬网程序将通过HTTP请求中的“用户代理”字段将其身份信息告知自己. 抓取工具访问网站时,它将首先根据该网站下的Robots.txt文件确定可以抓取的页面范围. Robots协议是Web爬网程序必须遵守的协议. 对于某些禁止的URL地址,Web爬网程序不应该对访问进行爬网.
同时,如果在对某个网站进行爬网时抓取程序陷入无限循环,从而导致该网站的服务压力过大,那么如果设置了正确的身份,则该网站的网站站长可以找到联系爬虫的方法,然后停止相应的爬虫程序.
当然,某些爬网程序会伪装成其他爬网程序或浏览器来爬网以获得其他数据,或者某些爬网程序会随意爬网,而不受机器人协议的限制. 从技术角度来看,这些行为并不难实现,但我们不主张这些行为,因为只有遵循良好的网络规则,我们才能实现搜寻器与站点服务器之间的双赢局面.
06
网络爬虫实施技术
通过先前的研究,我们基本上对履带的基本理论知识有了更全面的了解. 因此,如果我们要实现Web爬虫技术并要开发自己的Web爬虫,可以使用哪些语言进行开发?
有许多用于开发Web爬虫的语言. 常见语言是: Python,Java,PHP,Node.JS,C ++,Go等. 下面我们将介绍用这些语言编写爬虫的特征:
摘要
1. 专注于网络爬虫. 由于需要有目的地对它们进行爬网,因此对于一般的Web爬网程序,有必要增加目标的定义和过滤机制. 具体来说,此时,其执行原理和过程需求比一般的Web爬网程序多3个步骤,即目标的定义,不相关链接的过滤以及下一步要爬网的URL地址的选择.
2. 网页更新策略主要有三种: 用户体验策略,历史数据策略和聚类分析策略.
3. 聚类分析可以根据产品之间的共性进行相应的处理,并将具有更高共性的产品归为一类.
4. 在搜寻器搜寻网页的过程中,搜寻器必须访问相应的网页. 此时,常规搜寻器通常会将其搜寻器身份告知相应网页的网站管理员. 网站的管理员可以通过搜寻器通知的身份信息来识别搜寻器的身份. 我们将此过程称为搜寻器的识别过程.
5. 开发网络爬虫有很多语言. 常见语言是Python,Java网络爬虫的工作原理,PHP,Node.JS,C ++,Go等.
本文摘录自“精通Python Web爬虫: 核心技术,框架和项目实践战斗”
“掌握Python Web爬网程序: 核心技术,框架和项目实战”
点击书的封面以查看详细信息
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-237609-1.html
-

-
余鹏飞
马云也是拼了啊
-
王晓娜
活该
-
中国人不打中国人