3.1 Web爬网程序原理的详细说明
电脑杂谈 发布时间:2020-04-16 21:01:09 来源:网络整理
第二篇核心技术文章
第3章Web爬网程序的实现原理和实现技术
第4章Urllib库和URLError异常处理
第5章Cookies的正则表达式和使用
第6章手写Python爬网程序
第7章学习使用提琴手
第8章爬行动物的浏览器伪装技术
第9章爬行动物的定向爬行技术
通过上一章的研究,我们已经基本了解了Web爬网程序,那么应该如何实现Web爬网程序呢?有哪些核心技术?在本文中,我们将首先介绍Web爬网程序的相关实现原理和实现技术;然后,说明Urllib库的实际战斗内容;然后,带领您共同开发几个典型的Web爬网程序,让所有从事实战项目的人都深入了解Python Web爬网程序的开发;在学习了一些经典的Web爬虫开发之后,我们将学习和学习Fiddler数据包分析技术,浏览器伪装技术,爬虫定向爬网技术等知识,以便每个人都能更深入地进入Web爬虫技术的世界.
第3章Web爬网程序的实现原理和实现技术
我们最初了解了Web爬虫,并了解了Web爬虫的应用领域. 在本章中,我们将学习Web爬虫的实现原理和实现技术,并使用metaseeker为每个人提供一个简单的爬虫案例.
3.1 Web爬网程序实现原理的详细说明
不同类型的Web爬网程序具有不同的实现原理,但是这些实现原理存在许多共性. 这里,我们以两个典型的Web爬虫为例(即普通的Web爬虫和聚焦的Web爬虫),并分别说明Web爬虫的实现原理.
1. 通用网络抓取工具
首先,让我们看一下通用网络抓取工具的实现原理. 通用Web爬虫的实现原理和过程可以概括如下(见图3-1).
1)获取初始URL. 初始URL地址可以由用户手动指定,也可以由用户指定的一个或几个初始抓取的网页确定.

2)根据初始URL爬行页面并获得新的URL. 获取初始URL地址后,首先需要在相应的URL地址中对网页进行爬网. 在使用相应的URL地址对网页进行爬网之后,该网页将存储在原始中,而在对网页进行爬网时,将找到一个新的URL地址,并将同时抓取的URL地址存储在URL列表中,用于重复数据删除和判断爬网过程.
3)将新URL放入URL队列. 在第2步中网络爬虫 工作原理,获取下一个新的URL地址后,新的URL地址将被放置在URL队列中.
4)从URL队列中读取新URL,根据新URL对网页进行爬网,同时从新网页中获取新URL,并重复上述爬网过程.
5)当满足搜寻器系统设定的停止条件时,停止搜寻. 编写搜寻器时,通常会设置相应的停止条件. 如果未设置停止条件,则搜寻器将继续搜寻,直到无法获取新的URL地址为止. 如果设置了停止条件,则在满足停止条件时,爬虫将停止爬网.
以上是一般Web搜寻器的实现过程和基本原理. 接下来,我们将为所有人分析Web爬网程序的基本原理和实现过程.
2. 专注于网络爬虫

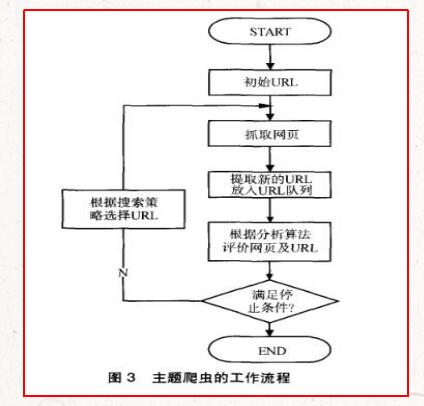
关注网络爬虫. 由于需要有目的地对它们进行爬网,因此对于一般的Web爬网程序,有必要增加目标的定义和过滤机制. 具体而言,此时,它的执行原理和过程需要更加通用. Web爬网程序还有另外三个步骤,即目标的定义,不相关链接的过滤以及下一步要爬网的URL地址的选择网络爬虫 工作原理,如图3-2所示.
1)爬网目标的定义和描述. 在集中式Web爬网程序中,首先必须根据爬网要求定义集中式Web爬虫的爬网目标,并进行相关描述.
2)获取初始URL.
3)根据初始网址抓取页面并获取新的网址.
4)从新URL筛选出与爬网目标不相关的链接. 因为聚焦网络爬虫是有目的的,所以与目标无关的网页将被过滤掉. 同时,还需要将爬网的URL地址存储在URL列表中,以进行重复数据删除和对爬网过程的判断.
5)将已过滤的链接放入URL队列.
6)根据搜索算法,从URL队列中确定URL的优先级,然后确定接下来要爬网的URL地址. 在一般的Web搜寻器中,下一个要爬网的URL地址并不重要,但是在集中式Web搜寻器中,由于其目的,下一个要爬网的URL地址相对重要. 对于专注的Web搜寻器,不同的搜寻顺序可能导致搜寻器的执行效率不同. 因此,我们需要根据搜索策略确定接下来要爬网的URL地址.
7)从下一步要爬网的URL地址中读取新的URL,然后根据新的URL地址对网页进行爬网,并重复上述爬网过程.
8)当满足系统中设置的停止条件时,或者无法获取新的URL地址时,停止爬网.
现在我们已经初步了解了Web爬虫的实现原理和相应的工作流程,下面让我们了解一下Web爬虫的爬虫策略.
最喜欢的朋友可以添加我们的微信帐户:
51CTO读取频道QR码
51CTO阅读频道活动讨论组: 342347198
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-177995-1.html
-
 陈成之
陈成之 -
王安礼
认同和学习几千年传承下来的中华文明
-
宋培源
我的6p上段时间升级了9
-
-
李静
中国可以在附近海