搜索引擎的排名原则是什么
电脑杂谈 发布时间:2020-04-11 02:16:35 来源:网络整理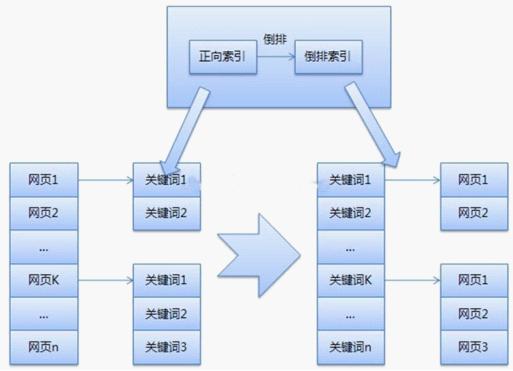
全部展开
要了解搜索引擎的优化搜索引擎原理 存储,首先要了解搜索引擎的基本工作原理. 搜索引擎排名可以大致分为四个步骤. 爬行和爬行

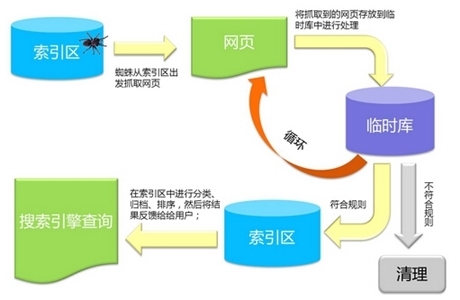
搜索引擎发出一个程序,该程序可以在Internet上找到新的网页和爬网文件. 该程序通常称为蜘蛛或机器人. 搜索引擎蜘蛛从中的已知网页开始,然后像普通用户的浏览器一样访问这些网页和爬网文件.
搜索引擎蜘蛛将跟踪网页上的链接,访问更多网页,此过程称为抓取. 通过链接找到新URL时,爬虫会将新URL记录到中并等待爬网. 跟踪Web链接是搜索引擎蜘蛛发现新URL的最基本方法,因此反向链接已成为搜索引擎优化的最基本因素之一. 没有反向链接,搜索引擎甚至无法找到页面,更不用说排名了.

由搜索引擎蜘蛛抓取的页面文件与用户浏览器获得的页面文件完全相同,并且抓取的文件存储在中. 索引
搜索引擎索引程序分解,分析和存储由Spider爬网的Web文件,并将它们以大表的形式存储在中. 此过程正在建立索引. 在索引中,相应地记录了诸如网页文本内容,关键字的位置,字体,颜色,粗体,斜体等相关信息.
搜索引擎索引存储大量数据,而主流搜索引擎通常存储数十亿个网页. 搜索文字处理
用户在搜索引擎界面上输入关键字并单击“搜索”按钮后,搜索引擎程序将处理输入的搜索词,例如中文特定的分词处理,并删除用于关键字. 确定是否需要开始集成搜索以及是否存在拼写错误或错别字. 搜索词必须非常快速地处理. 排序

处理完搜索词后,搜索引擎排序程序开始工作,从索引中查找包含搜索词的所有页面,并根据排名计算方法计算应首先对哪些页面进行排名搜索引擎原理 存储,然后返回e799bee5baa6e997aee7ad94e78988e69d8331333363386164根据某种格式的“搜索”页面.
尽管排序过程在一到两秒钟内完成以返回用户想要的搜索结果,但是实际上,这是一个非常复杂的过程. 排名算法需要从索引中实时找到所有相关页面,并实时计算相关性,并添加过滤算法,这种算法的复杂性是外人难以想象的. 搜索引擎是当今最大,最复杂的计算系统之一.
但是即使最好的搜索引擎在识别网页方面也无法与人类相比,这就是为什么网站需要搜索引擎优化的原因.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-171267-1.html
-

-
曾小玲
哪个行业不都是少数人赚钱
-
王亚红
明明是四个大帅哥
 联想多合一重装系统教程|如何为联想多合一机通过U盘重新安装win7系统
联想多合一重装系统教程|如何为联想多合一机通过U盘重新安装win7系统 结构关系模型 华人娱乐网
结构关系模型 华人娱乐网 松原激光烧结尼龙,工业3D打印机
松原激光烧结尼龙,工业3D打印机 Photoshop19 32位下载19.1.2 Lite Lite破解版
Photoshop19 32位下载19.1.2 Lite Lite破解版
是赤裸裸的羞辱