搜索引擎原理
电脑杂谈 发布时间:2020-04-11 02:15:26 来源:网络整理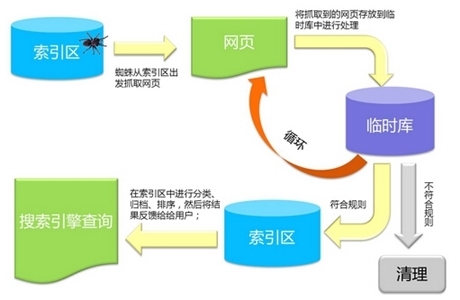
SEO优化技术SEO概述了解搜索引擎SEO概述?从1994年至今,中国互联网已经发展了20多年. 据统计,截至2017年6月,中国网民数量达到5.51亿. 2017年1月至2017年6月,新增1920万网民,半年增长率为2.7%. 互联网普及率超过50%,达到54.3%,超过了全球平均水平的4.6%. SEO概述?截至2017年6月,中国的搜索引擎用户达到6.09亿,利用率为81.1%. 用户规模较2016年底增加707万,增长率为1.2%. 搜索引擎已成为网站获取流量的重要渠道. 如何通过搜索引擎获得更多流量,SEO是非常重要的方式. 无论是个人网站,企业网站还是中型或大型网站,它都非常重视网站的优化. SEO概述? SEO在中国已经开发了10多年. 随着国内SEO行业的不断发展和成熟,业内人士对SEO的认识和理解也有所不同. 这显然是错误的,但这也是普遍现象,那么什么是SEO,为什么要进行SEO,以及与搜索引擎相关的知识,我们将在本章中一起讨论. 学习目标SEO概述,了解搜索引擎?了解SEO概念?了解为什么需要SEO?掌握搜索引擎如何工作?爬行和爬行?预处理?排序?掌握搜索引擎的常用命令和术语什么是SEOSEO概述? SEO是英语搜索引擎优化的缩写,中文翻译是“搜索引擎优化”.
简单地说,SEO是从自然搜索结果中获取网站流量的技术和过程. 严格定义: SEO是指在了解搜索引擎的自然排名,提高搜索引擎中文件的自然排名,获取更多流量从而实现网站销售的基础上,对网站进行内外部的调整和优化. 和品牌建设目标. 什么是SEO网站结构SEO概述网站优化页面规划网站优化内容优化外部链接建设网站优化行业社区的参与和互动? SEO研究对象是搜索引擎结果页面中自然排名的部分. 获取和改善文件的自然排名是SEO的一项功能,但最终目标是获得搜索流量,最终可以带来可观的流量. 为什么要做SEO? SEO当前是将访客吸引到您的网站的最佳方法. 搜索流量质量,高性价比,高可伸缩性,长期有效改善网站的易用性以及改善的用户体验. SEO概述. 搜索引擎如何工作简介了解搜索引擎?搜索引擎的工作过程大致分为三个阶段: 搜索引擎蜘蛛通过跟踪链接来发现和访问网页,阅读HTML代码并将其存储在中. 预处理?索引程序对爬网的页面执行文本提取,中文分词,索引和倒排索引处理,以准备调用排名程序. 排行?用户输入查询词后,排名程序调用索引数据,计算相关性,然后以某种格式生成搜索结果页面.
爬行和爬行(1个蜘蛛)搜索引擎原理?搜索引擎用来爬网和访问页面的程序称为蜘蛛程序或漫游器. 页面访问请求HTML代码?. 图1搜索引擎蜘蛛访问页面的爬网和爬网(1个蜘蛛)搜索引擎的原理?蜘蛛访问任何网站时,都会首先访问网站根目录中的robots.txt文件. 如果robots.txt文件禁止搜索引擎抓取某些文件或目录,则抓取工具将遵守协议并且不会抓取被禁止的网站. 爬行和爬行(1个蜘蛛)搜索引擎如何工作?与浏览器一样,搜索引擎蜘蛛也具有指示其身份的用户代理名称. 网站管理员可以在日志文件中查看特定于搜索引擎的用户代理,以识别搜索引擎蜘蛛. 百度蜘蛛: 百度蜘蛛Google: Googlebot微软MSN: msnbot腾讯搜搜: Sosospider搜狗: 搜狗+网站+蜘蛛网易优道: youdaobot爬行和爬行(2个跟踪链接)搜索引擎的原理?为了在网站页面上尽可能多地爬网,搜索引擎蜘蛛将跟踪页面上的链接并从一个页面爬到下一个页面. 爬行和爬行(2个跟踪链接)搜索引擎的原理?蜘蛛爬行遍历策略: 深度优先,宽度优先爬行和爬行(3个吸引蜘蛛)搜索引擎原理?从理论上讲,爬虫可以爬取和爬取所有页面,但实际上它们不能,也不会.

SEO员工希望使他们的网站更具特色,他们必须找到允许蜘蛛尽可能多地爬行重要页面的方法. 有哪些影响因素?爬网(4地址库)搜索引擎原理?为了避免重复爬网和爬网,搜索引擎将建立一个地址. 蜘蛛程序在页面上找到链接,而不是立即访问它. 而是将URL存储在地址库中,然后以统一的方式安排爬网. 地址库发现了尚未爬网的页面. 页面爬网和爬网页面的爬网(4地址). 搜索引擎原理. 地址库中URL的来源. 从站点蜘蛛爬网页面手动爬网后,新的URL站点得到解决. 网站管理员通过搜索引擎页面提交表单. 网站管理员通过XML映射和网站管理员平台(5个文件存储)提交URL爬行和爬网. 搜索引擎如何工作?搜索引擎蜘蛛抓取的数据存储在原始页面中,其中页面数据和用户浏览的HTML完全相同. 每个URL都有一个唯一的文件编号. ?此外,爬网程序在爬网和爬网文件时会执行一定程度的复制内容检测. 当它们在权重较低的网站上遇到大量重印或抄袭的内容时,它们可能不再继续爬网. 爬网和爬网(质疑)搜索引擎如何工作?大多数主流搜索引擎为网站管理员提供了一种提交URL的表格. 是否包含提交的网页?答: 这些URL仅存储在地址中. 是否包含它们取决于页面的重要性.
搜索引擎中包含的大多数页面是蜘蛛自身通过链接获得的. 爬网和爬网(摘要)搜索引擎的原理?搜索引擎蜘蛛的爬取和爬取是通过跟踪链接查找和访问网页,读取HTML代码并将它们存储在中. ?爬网和爬网是搜索引擎工作的第一步,完成数据收集的任务. 第二步是预处理,也称为“索引编制”,它如何工作?预处理【索引】理解搜索引擎提取文本中文分词,停止单词,消除噪声链接关系的计算方法,以重复的正向索引特殊文件处理倒排索引质量判断预处理(1提取文本)搜索引擎原理 存储,搜索引擎的原理对用户可见浏览器文本HTML标签,JavaScript程序(不能用于排名)删除了一些包含文本信息的特殊代码. 备用文本搜索引擎可提取Meta标签Flash文件中的文本还是基于文本内容的图像替换文本链接锚文本预处理(2个中文分词)?分词是中文搜索引擎的独特步骤. 搜索引擎原理预处理(2个中文分词)搜索引擎原理?中文分词有两种基本方法: 字典匹配和基于统计的方法,它们成功匹配并切出一个单词. 扫描方向正向匹配反向匹配最大匹配最小匹配字典匹配长度优先匹配扫描方向和长度优先混合词分割是中文搜索引擎的独特步骤正向最大匹配反向最大匹配双向最大匹配长春药房上漆和尚画长春市长春节快乐预处理(2个中文分词)搜索引擎的原理?中文分词的基本方法有两种: 字典匹配和基于统计的.
?基于统计的分词方法是指分析大量的文本样本,计算出相邻词出现的统计概率. 出现的相邻单词越多,形成单词的可能性就越大. ?中文分词的准确性通常会影响搜索引擎排名的相关性. ?搜索引擎进行的分词取决于词库的大小和准确性以及分词算法的质量,而不是页面本身. SEO员工唯一能做的就是以页面标题,H1标签和黑体字的形式在页面上提示搜索引擎,并且应将某个单词视为一个单词. ? “和服”,“化妆和服装”的预处理(3个停用词)搜索引擎的原理?页面内容中的某些单词经常出现,但对单词的内容没有任何影响,例如“的”,“地”,“得”,辅助词,例如“ ah”,“ ha”,“ ah”和其他形容词,例如“因此”和“但是”. 这些单词称为停用词. ?搜索引擎将在索引页面之前删除这些停用词,以使索引数据的主题更加突出并减少不必要的计算. 预处理(消除4种噪声)搜索引擎的原理?大多数页面仍然具有部分内容,这些内容不会对页面的主题有所帮助,例如版权声明文本,导航栏,广告等,它们只能在页面主题上扮演分散的角色. ?搜索引擎需要识别并消除这些噪音,并且在排名时不要使用噪音内容. 降噪的基本方法是基于HTML标签将页面分为多个块,区分页眉,导航,文本,页脚,广告和其他区域. 网站上大量重复出现的方块通常是噪音.

预处理(5个重复数据删除)搜索引擎的原理是什么? “重复数据删除”的基本方法是计算页面特征文件的指纹. (分词,停用词,减少噪音)页面的主要内容是文件计算中最具代表性的部分?经典的指纹计算方法,例如MD5算法,输入特征关键字和顺序的任何细微变化都将导致计算出的指纹存在较大差距. ?了解搜索引擎的重复数据删除算法后,您应该知道,仅添加“”,“ land”和“ get”,更改段落的伪原始顺序,就无法逃脱搜索引擎的重复数据删除算法. 预处理(6个前向索引)搜索引擎的原理是什么?接下来,搜索引擎从唯一的可以反映页面主要内容的单词字符串中提取关键词,并根据分词程序对单词进行划分,将页面转换为关键词集合,同时记录关键词的出现频率. 页面上每个关键字的出现次数,格式(例如标题标签,粗体,H标签,锚文本等),位置和其他信息. 索引程序将页面和关键字存储到词汇表结构中,并将它们存储在索引库中. 简化的索引词汇表格式如下: 文件ID内容文件1文件2文件3文件6…关键字2,关键字7,关键字10,…,关键字X关键字1,关键字2,关键字7,关键字10,...,关键字L关键字1,关键字7,关键字30,...,关键字M关键字2,关键字70,关键字305,...,关键字N File x ...关键字7,关键字50,关键字90,...,关键字Y预处理(7个倒排索引)搜索引擎原始吗?正向索引不能直接用于排名,搜索引擎会将正向索引重建为反向索引,将相应的文件映射到关键字转换为从关键字到文件的映射.
?当用户搜索某个关键字时,排序程序会在倒排索引中找到这些关键字,您可以立即找到所有包含该关键字的文件. 关键字关键字1关键字2关键字3…关键字7…关键字Y文件80,文件90,文件100,...,文件x文件1,文件2,文件6,...,文件x文件文件1,文件2,文件15,文件58,...,文件1,文件3,文件6,...,文件m,文件5,文件700,文件805,...,文件n预处理(8个链接关系计算)搜索发动机原理?现在,所有主流搜索引擎排名因素都包括页面之间的链接流信息. 搜寻页面内容时,搜索引擎必须预先计算页面上的链接,指向其他页面的对象以及用于每个页面上的传入链接的锚点. 文字Google PR值是这种链接关系的最重要体现. 网站和页面的链接权重预处理(9个特殊文件处理)搜索引擎原理?除了HTML文件之外,搜索引擎通常还可以抓取和索引多种基于文本的文件类型,例如PDF,Word,WPS,XLS,PPT,TXT文件等. 但是,当前的搜索引擎无法处理图像和视频,并且只能处理对非文本内容(例如Flash)以及脚本和程序的处理受到限制.
?图片和视频内容的排名通常基于相关的文本内容. 预处理(10个质量判断)搜索引擎原理?在预处理阶段,搜索引擎会对页面内容的质量和链接质量做出判断. 在过去的两年中,预先计算了百度Luluo和Pomegranate算法,Google的Panda和Penguin算法. 而不是在查询时实时计算. 定性关键词提取和用户体验链接计算,价值计算,页面布局,页面内容判断,广告布局页面打开速度判断,预处理(提问)搜索引擎原理?搜索引擎蜘蛛对页面进行爬网之后,索引程序将计算反向索引. 此后,搜索引擎可以随时处理用户搜索了. 在用户的搜索框中填充查询词后,排名程序将调用索引并计算排名并将其显示给用户. 它可以显示在成千上万包含搜索关键字的页面上,如何对它们进行排序以进行显示?排名(搜索词处理)了解搜索引擎?在接收到用户输入的搜索词之后,搜索引擎需要对搜索词进行一些处理以进入排名过程. 搜索词的处理包括以下几个方面: 中文分词ֹ单词命令处理error拼写错误纠正综合搜索触发器搜索框提示排名(文件匹配)了解搜索引擎?处理了搜索词后,搜索引擎将根据该词集获取关键字. 文件匹配阶段是查找所有搜索关键字的所有文件. 索引部分中提到的反向索引使文件匹配得以快速完成.

如下所示,倒排索引会快速匹配文件. 关键字关键字1关键字2关键字3…关键字7…关键字Y文件80,文件90,文件100,...,文件x文件1,文件6关键字2关键字7文件1,文件2,文件6,...,文件x文件文件1,文件2,文件15,文件58,...,文件l文件1,文件3,文件6,...,文件m文件5,文件700,文件805,...,文件n排名(选择初始子集)了解搜索引擎吗?找到包含所有关键字的匹配文件后,将无法执行相关性计算搜索引擎原理 存储,因为找到的文件通常为数十万至数百万甚至数千万. 大多数用户只会查看前两个页面,这是前20个结果. ?百度通常返回76页的结果,而Google最多返回100页的结果. 360通常会返回64个结果页. ?由于显示的结果页面远小于实际文件数,因此用于最终相关性计算的初始页面子集的选择必须依赖于其他功能而不是相关性. 最重要的是页面重量. 排名(相关性计算)知道搜索引擎吗?选择初始子集后,计算子集中页面的关键字相关性. 计算相关性是排名过程中最重要的步骤. ?影响相关性的主要因素包括: 排名(排名过滤和调整)了解搜索引擎?在选择了匹配文件的子集并计算了相关性之后,就确定了总体排名.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-171263-1.html
 JAVA图像识别技术示例
JAVA图像识别技术示例 图像识别算法 优势 教育人工智能面临发展难题,技术路径如何突破
图像识别算法 优势 教育人工智能面临发展难题,技术路径如何突破 剑指提供程序设计问题-二叉搜索树的后遍历序列
剑指提供程序设计问题-二叉搜索树的后遍历序列 下台式机电脑开机后显示器无信号故障的解决方法
下台式机电脑开机后显示器无信号故障的解决方法
关键是我们抓紧时间好好发展