SPSS中因子分析的操作过程和结果解释
电脑杂谈 发布时间:2020-04-04 18:09:48 来源:网络整理
进行这项研究时,我检查了Internet上的许多信息,并以更加的方式编写了这些信息,因此本文从因素分析的前端到后端进行了简单明了的解释. 全文不包含非常晦涩的公式. 原理.
在因子分析模型中,假定每个原始变量都由两部分组成: 一个公共因子和一个唯一因子. 公因子是所有原始变量的公因子,解释了变量之间的相关性. 顾名思义,唯一因子是每个原始变量唯一的因子,这意味着该变量不能用公因子来解释.
(帮助解释: 例如,现在一个Excel工作表中有10个变量,因子分析可以通过某种算法将这10个变量更改为3、4、5等,并且每个因子都可以表达一个含义,从而达到降维的效果,方便后续数据分析
主成分分析是试图找到原始变量的线性组合. 此线性组合的方差越大,组合包含的信息越多. 换句话说spss视频教程 因子分析,主成分分析就是扩大原始数据的主要成分.
因子分析,假定原始变量后面有隐藏的因素. 该因子可以包括一个或多个原始变量. 因子分析不是原始变量的线性组合.
(帮助解释: 主成分分析降低了维数以突出显示变量中的主要变量,因子分析发现了变量背后的因子可以概括变量的特征)
---------------------------将不再介绍算法和原理,但更秃头---------- -------------------
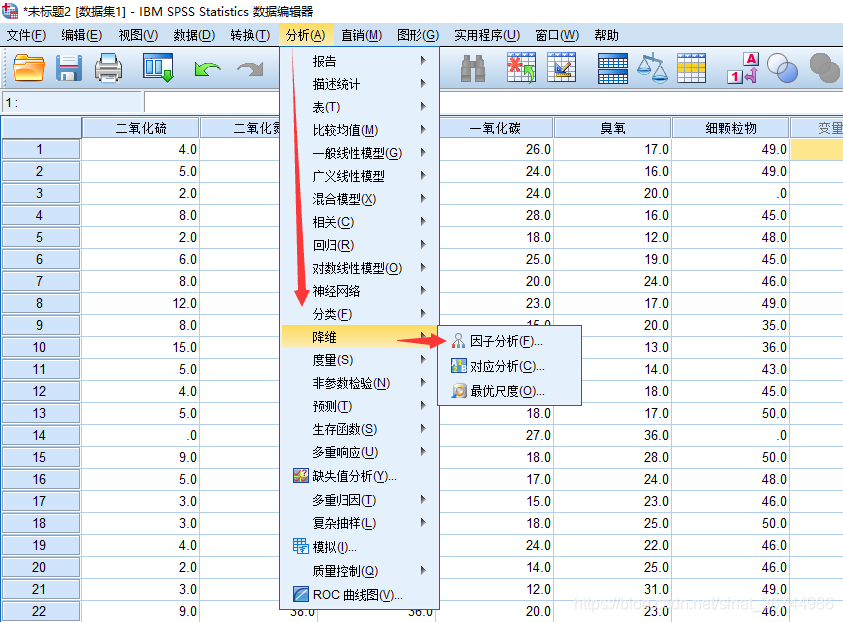
以下数据是一个城市的空气质量数据,共有6个变量,即: 二氧化硫,二氧化氮,可吸入颗粒物,一氧化碳,臭氧,细颗粒物. 在SPSS中打开数据,如下所示:


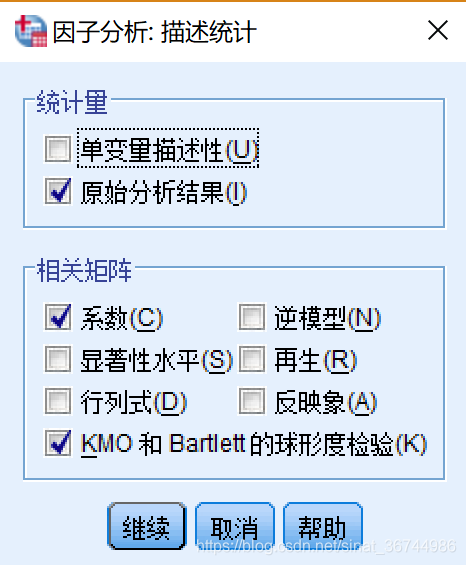
a. 说明: 让我们谈谈KMO和Bartlett的球形度测试,
KMO测试统计数据是用于比较变量之间的简单相关系数和部分相关系数的指标. 它主要用于多元统计的因子分析. KMO统计数据在0到1之间. Kaiser给出了常用的kmo度量: 0.9表示非常合适; 0.8表示合适; 0.7表示平均值; 0.6表示不太适合; 0.5表示非常不合适. KMO统计信息介于0和1之间. 当所有变量之间的简单相关系数的平方和远大于部分相关系数的平方和时,KMO值接近1. KMO值越接近1变量之间的相关性越强,原始变量就越适合进行因子分析;当所有变量之间的简单相关系数的平方和都接近0时,KMO值接近0. KMO值越接近0,变量之间的相关性越弱,原始变量就越不适合合作因素分析.
Bartlett的球面检验用于检验相关矩阵中变量之间的相关性,是否为单位矩阵,即每个变量是否独立. 如果变量彼此独立,则不可能从变量中提取公因子,也不能应用因子分析. Bartlett球形检验判断如果相关矩阵是单位矩阵,则每个变量都是独立的,并且因子分析方法无效. 当SPSS测试结果显示为Sig. <0.05(即p值<0.05),表明变量之间存在相关性,并且因子分析是有效的.

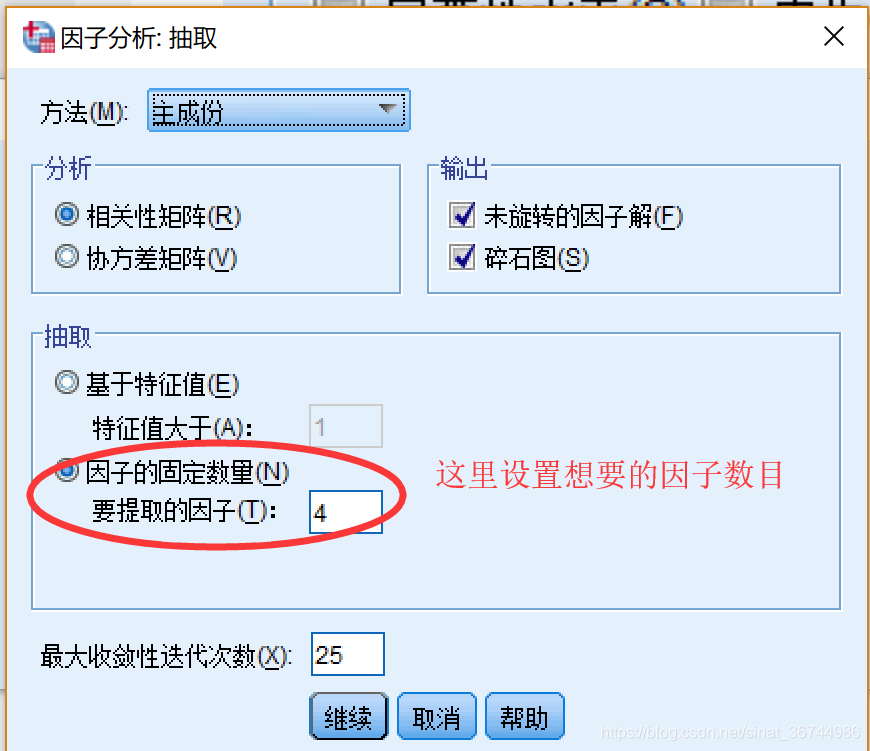
b. 提取: 通常,我们选择主成分方法,但是此方法不用于python中的因子分析.
c. 轮换: 轮换的作用是促进最终了解哪个变量属于哪个因素.
d. 得分:

e. 选项:
设置模型后,单击“确定”以在SPSS窗口中查看分析结果.
主要看以下几节的结果.
首先,KMO的值为0.733,大于阈值0.5,这表明变量之间存在相关性并符合要求;这是Bartlett球形测试的结果. 在这里,我们只需要查看Sig. 该值是0.000,因此小于0.05. 换句话说,可以对这些数据进行分解.

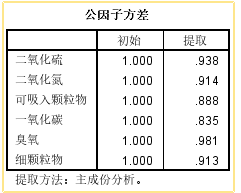
公共因子方差表意味着每个变量可以用一个公共因子表示,并且该公共因子可以表达多少,其表达的大小是公共因子中的``提取的''和``提取的''值方差表值越大,由公因子表示的变量越好. 通常,可以说当它大于0.5时可以表示它,但是最好要求大于0.7以解释该变量可以由公因子表表示. 在此示例中,您可以看到``提取的''值都大于0.7,因此可以很好地表达变量.

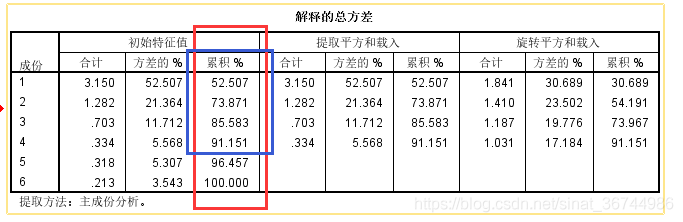
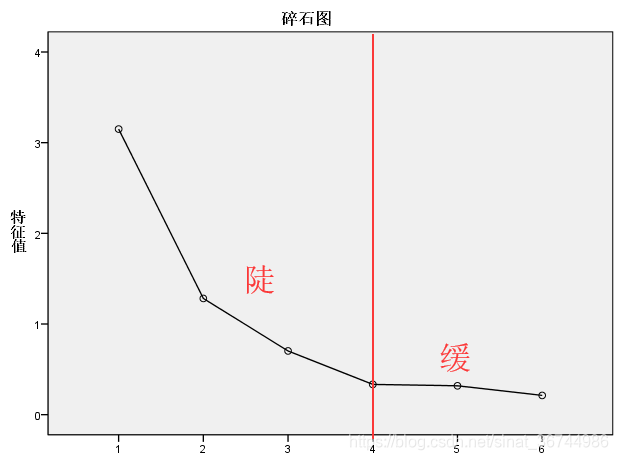
简而言之,解释的总方差基于因子对变量解释的贡献率(可以理解为将变量表示为100%需要多少个因子). 该表仅需查看图中红色框内的列,该列代表贡献率,蓝色框代表四个因子,以将该变量表示为91.151%,表明该表达式仍然不错. 我认为通常将其表示为90. 仅需要%以上,否则必须调整因子数据. 再次查看砾石图,的确,经过四个因素,折线变得平坦了.
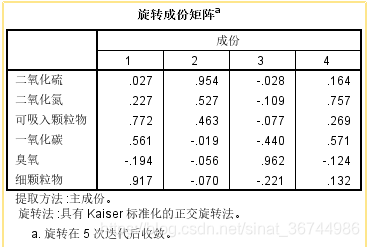
该表用于逐列查看哪些因子可以包含在哪些因子中: 第一列spss视频教程 因子分析,最大值为0.917和0.772,分别对应于细颗粒和可吸入颗粒,因此我们可以将因子归因于颗粒物. 在第二列中,最大值0.95对应于二氧化硫,因此我们可以将因子归因于硫化物. 在第三列中,最大值为0.962,它对应于臭氧,因此该因素可以归因于臭氧. 在第四列中,最大值分别为0.754和0.571,分别对应于二氧化氮和一氧化碳. 我不知道为什么这个因素下降了. 我可以问一下环境工程与环境科学系的学生. 在这里我选择好笑...
因子分析仍然是一种非常易于使用的降维方法. SPSS中的操作非常简单方便,结果一目了然. 喜欢机器学习的学生自然也知道这种好方法可以减少Python的使用. 是的,python也可以进行因子分析,并且代码量不是很大. 但是,当python执行因子分析时,将需要一些功能. 根据算法(头皮发麻)(例如KMO测试)编写自己. 如果您喜欢这篇文章,请喜欢它或留言. 将会有一些数据分析和机器学习知识可以与大家分享〜
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-163917-1.html
 .net反射器反编译失败. 索引超出了数组的限制.
.net反射器反编译失败. 索引超出了数组的限制. vs2017安装 招商部年终总结ppt 招商部年终总结工作总结
vs2017安装 招商部年终总结ppt 招商部年终总结工作总结 超市管理系统的详细设计手册
超市管理系统的详细设计手册 联想多合一重装系统教程|如何为联想多合一机通过U盘重新安装win7系统
联想多合一重装系统教程|如何为联想多合一机通过U盘重新安装win7系统
看到你那批样子