一种面向高维数据的集成聚类算法
电脑杂谈 发布时间:2019-10-13 17:03:26 来源:网络整理
聚类集成已经作为机器学习的探究热点,它对原始数据集的多个权值结果进行学习和集成高维聚类分析,得到一个能很好地体现数据集内在结构的数据划分。很多专家的探究证明聚类集成能有效地提升聚类结果的准确性、鲁棒性和稳定性。本文提出了一种面向高维数据的降维集成算法。该方式对于高维数据的特征,先用分层抽样的方式结合信息增益对每个特点簇选择适合数量非常重要的特点的生成新的具代表含义的数据子集,然后用基于链接的方式[1]对数据子集上生成的降维结果进行集成.最后在文本、图像、基因数据集上进行试验,结果证实,与集成前的K均值聚类算法及基于链接的降维集成算法相比,该方式能有效的缓解聚类结果。
关键词:分层抽样,高维数据,聚类集成,K均值聚类
1、引 言
聚类分析又称群探讨,是按照“物以类聚”的道理对样品或指标进行分类的一种多元统计预测方式。它是一个将数据分到不同类或者簇的过程,所以同一个簇中的对象有多大的相似性,而不同簇间的对象有很高的相异性。聚类分析是机器学习、模式识别的一个最重要的研究方向之一,它是知道数据集的结构的一种最重要的方式,并即将失败的应用于数据挖掘、信息检索、语音识别、推荐平台等领域[2]。
现实世界中的数据集具有诸多样式和构架,不存在哪一种单一的算法对任何数据集都体现的很高[3],没有一种聚类算法能精确揭示各种数据集所展现起来的多种多样的颜色和簇结构[4],每一种聚类算法都有其优缺点,对于任何给定的数据集,使用不同的算法就会有不同的结果,甚至针对同一种算法给定不同的参数就会有不同的降维结果,自然分组概念内在的不明确性决定了没有一个通用的聚类算法能适用于任何数据集的降维问题。此外,类存在多样性的特征,类带有不同的颜色、大小、密度,而且类之间常常是互相重叠的,这样的难题在高维数据中非常显著,因为不相关的或则冗余的特点会使类的结构非常不显著。K均值算法[5]是一种应用广泛的最经典的聚类算法之一,它的特征之一就是随机选择初始的阈值中心,如果选择的中心点不同,聚类结果就也许形成巨大的差别。K均值聚类算法对初始中心点的依赖性,导致K均值算法的聚类结果不稳定。在这些状况下,聚类集成应运而生,许多专家在这个领域进行了深入的探究。
聚类集成的目的在于结合不同聚类算法的结果得到比单个聚类算法更优的降维。对阈值集体中的成员聚类的问题作为一致性函数问题,或叫做集成问题。很多专家推测通过聚类集成可以有效的提升像K均值方差这些单一聚类算法的准确性、鲁棒性和稳定性 [6].在现有的探究中,产生基聚类结果的方式有:(1)使用同一种聚类算法,每次运行使用不同的参数和随机初始化[7];(2)使用不同的聚类算法,如K均值产生多个不同的聚类[4]; (3)对数据集的子集聚类,子集通过不同采样像bagging、Sub-sampling等方式获取[8];(4) 在数据集的不同特征子集或在数据集的不同子空间的投影上权值得到不同聚类结果构成聚类集体[9]。我们的方式主要是对第四种聚类集成问题进行了深入探究,在数据集的不同子集上进行集成分析。对于高维数据来说,数据点为单位界定仍存在维数灾难的难题,维数灾难可能会引发这样现象,一个给定数据点与离它今天点的距离比与离它最远的数据点的距离近,所以我们引入相同的数据点但基于不同的特点子集就可能会避免这些难题。生成基聚类结果之后就是设计一致性函数对方差结果集成,就是将聚类成员进行合并,得到一个统一的聚类结果。目前存在诸多一致性函数,常用的有投票法、超图划分、基于共协矩阵的证据积累、概率积累等等,我们在文章中用了文献[1]中的方式,它是一种基于链接的方式。常规的集成方法通常基于一个由基聚类结果即那些数据基聚类结果内部的关系生成,忽略了很多结果之间的关系,所以Iam-on[10]等运用簇之间的相似度来精炼集成信息矩阵。在高维数据中,我们将数据集的局部特性子集用作聚类成员与基于链接的集成聚类方式有效结合,解决了高维数据进行集成聚类的问题。
本文组织如下:第2节对聚类集成做了一个概述,并针针对高维数据这一特殊数据集提出了自己的集成聚类方式。第3节是本文的核心部分,它讲述了对特点进行分层抽样,并基于信息增益抽取出非常重要的具备代表含义的局部特性子集的过程,此外对传统的K均值算法的详细过程进行了详尽的叙述,然后引出了分层抽样的概念,用分层抽样的观念确定我们选取的特点的数量,最后给出了信息增益的定义,通过这个指标最后确认我们在每一个聚类簇中选取的特点;最后把我们后面的工作抽取局部特性子集与基于链接的方式结合出来产生了自己的算法描述;第4节首先对8个实际数据集包括文本、图像、基因数据进行表述,然后在这八个数据集上非常和探讨了我们的方式(SSLB)和传统K均值算法和基于链接的降维集成算法(LB)在四个聚类评价标准上的聚类性能;第5节是对全文的小结。
2、相关工作
2.1 聚类集成概述
聚类分析是根据某些相似性测度将多维数据分隔成自然分组或簇的过程。 聚类算法很多,但是没有一个万能的聚类算法能用于任何聚类问题,其原因在自然分组概念的内在不明晰性或者类可以有不同的颜色、大小、密度等,这个在高维数据中的弊端更为明显,那些不相关的特点和冗余的特性会使类结构非常模糊。单个聚类存在的这种难题,引发了学者们对阈值集成的探究。首先由Strehl[12]等人提出”聚类集成”的概念,而后Gionis[13]等人也给出该问题的表述。杨草原等给聚类集成下了一个定义,认为聚类集成就是利用经过选择的多个聚类结果找到一个新的数据(或对象)划分,这个界定在最大程度上共享了所有输入的阈值结果对数据或对象集的聚类信息。
聚类集成的符号化形式为:假设数据集X有n个例子,X={x1,x2,…,xn},首先对数据集X使用M次聚类算法,得到M个权值,={1,2,…,M}(下面称为聚类成员),其中i(i=1,2,…,M)为第i次聚类算法得到的降维结果。然后用一致性函数T对的降维结果进行集成得到一个新的数据划分’[1].
摘 要

Fig. 1: The basic process of cluster ensembles. Firstly, we obtain diverse partitions via different clustering, and then those Intermediate results are combined to establish the final result via the consensus function.

图1聚类集成的基本过程。首先对数据集使用不同的聚类算法得到不同的界定,然后对这种划分用一致性函数合并为一个聚类结果P’
由下面的前馈集成过程推测,对一个数据集进行拟合集成[11],主要有两个阶段,第一个阶段是基聚类器对原始数据进行加权,得到基聚类结果。第二个阶段是基聚类结果集成,根据加权集成算法对前一个阶段收集的基聚类结果进行处理,使之才能最大限度地分享这种结果,从而受到一个对原始数据最好的聚类集成结果。
2.2 面向高维数据的集成聚类
信息时代互联网成为最大的信息聚集地,像Web文档、交易数据、基因表达数据、用户评分数据等等,这些作为聚类分析的主要研究对象,而这种数据的维度成千上万,甚至更高,这给聚类分析带给了极大的挑战。高维数据的降维集成面临更多的难题。
传统的集成学习的第一步是造成多个基聚类结果,这一阶段是对数据集或者其子集反复进行聚类算法。现有的方式主要有:使用一个聚类算法,每次运行修改不同的参数和随机初始化;使用不同的聚类算法;对数据集的子集进行加权;将数据集的特点空间投影到数据子空间。基聚类结果生成之后就起初对基聚类结果进行集成。一致性函数是一个函数以及是一个方法,它将聚类成员进行集成,得到一个统一的聚类结果[14]。目前存在许多一致性函数,它大概可以分为: (1)基于成对相似性的方式[3],它主要考量的是所有的数据点对的关系的再现、(2)基于超图划分的方式[15]和(3)基于特征的方式[16],它是把聚类的集成转化为类标的集成。
针对高维数据的特征,我们选取基于相似性的方式对拟合结果进行集成,凝聚层次聚类算法是最经典的基于相似性方法,我们用了文献[12]中的方式,他把SL凝聚聚类算法用来生成最后的界定。但是基于成对相似度的集成的过程都是一个比较粗糙的过程,集成的结果通常基于一个由基聚类结果即那些数据划分内部的关系生成,忽略了很多划分结果之间的关系,所以它使用了Iam-on[17]等利用簇之间的相似度来提炼集成信息矩阵,实验证明这些方式在众多数据集上体现较好,不仅提高了聚类稳定性也提升了阈值性能。由于我们研究的对象是高维数据,考虑到需要拟合的对象的维度很大,对完整的对象聚类一定会降低聚类算法的运行开销。这对基于链接的方式性能有所影响,因此,我们考量对特点空间的局部特性子集进行拟合得到结果。经过前面的预测,我们引出自己的方式。我们对其中的基本方法进行强化,我们的方式如下:

Fig. 2 The basic process of our proposed method.it describe the steps in details, what’s more, this picture show the input and output in each step.
图2 我们原则的,对拟合集成的过程进行了明确,描述了每一个过程的输入和输出
我们的方式就是针对高维数据的特征,对传统的降维集成进行了一些优化,我们首先用上面看到的K均值算法对特点进行加权,然后用信息增益来评判不同簇中的特点的重要程度,而每个特点簇中的所抽取特性的数量nh由上面stratified sampling[18]的方式受到,最后运用信息增益选择top(nh)的特点。根据上述步骤对特点进行迭代,得到了最具代表的数据子集。数据子集的生成,变换K均值算法的k值,取 k=2,3…√N(N为数据点的数量)生成不同的具备差异的数据子集,然后沿用[1]中的方式进行降维集成,最后把这√N-2次的聚类结果进行最后一次集成得到我们最后的降维结果。基于局部特性子集的生成方式内容在下一章详细讲述。
3、基于局部特性的数据子集生成方式
集成时使用哪种方式形成聚类成员通常从两个方面来考量,一个是集成者的目的,一个是数据集的结构。在机器学习的实际应用中,我们应对的绝大多数都是高维数据。数据集的特点数量通常较差,可能存在不相关的特点,特征之间也许存在相互依赖,容易造成分析特点、训练模型的时间变长,甚至导致“维度灾难”,模型复杂推广能力上升。所以我们采取基于局部特性的数据子集生成方式。图3是我们生成局部特性的数据子集的:

Fig. 3 The basic process of the generation of feature subset
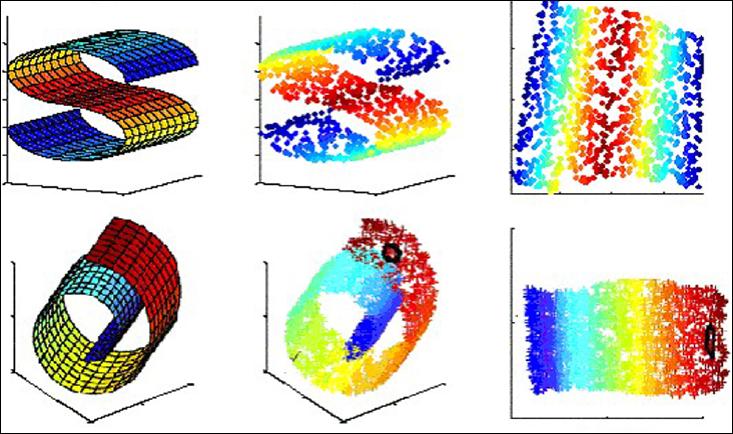
图3 局部特性子集的生成方式
首先我们用传统的K均值算法对数据集的特点进行加权,然后针对不同的特点簇我们用信息增益来评判它的重要性,不同的特点簇中我们需要筛选多少特性簇呢?分层抽样很好的缓解了这个难题,分层抽样的观念是推导每个案例之间的相关性(用标准差、方差来评判),它觉得类中的例子相关性比较大的可以选用较好的样本来替代当前类,类中相关性较小的就少选用一些例子来替代当前类的样本,根据分层抽样中估算出的特点簇的数量再利用信息增益这种评判重要性的标准进行筛选后就受到了局部的特点子集。下面详细阐述基于局部特性的数据子集生成方式中的关键技术。
3.1 k均值算法
K均值算法[5]是MacDueen提出的一个著名的聚类学习算法。它按照相似度距离迭代的升级向量集的降维中心,当聚类中心不再变化以及满足这些停止条件,则中止迭代过程受到最后的降维结果。K均值算法的详细方法为:
(1)随机选取k个数据项作为加权中心;
(2)根据相似度距离公式,将数据集中的每一项数据分配到离他今天的聚类中去;
(3)计算新的聚类中心;
(4)如果聚类中心没有发生改变,算法结束;否则跳转到第(2)步.
我们使用K均值算法对数据集的特点进行加权,我们借助选取不同的k值进行特点聚类,然后用下面的分层抽样进行选取得到变化度非常显著的局部特性的数据子集作为上面的降维集成的输入。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-126198-1.html
-

-
王倩倩
怎么没有人靠炒股发财
-
人妖雷
必须给他弄沉
-
 Rhinoceros(犀牛软件)5
Rhinoceros(犀牛软件)5 教你出现蓝屏代码0x000000d1的解决方法,你知道吗?
教你出现蓝屏代码0x000000d1的解决方法,你知道吗? 雨林木风ghost xp sp3一键装机版V2018.05
雨林木风ghost xp sp3一键装机版V2018.05 湖南: 关于促进全省工业园区高质量发展的实施意见
湖南: 关于促进全省工业园区高质量发展的实施意见
才能有效制止战争