中国艺术研究院好考吗_amd中国研究院_中国鼻科研究院在哪里(5)
电脑杂谈 发布时间:2017-02-22 01:04:14 来源:网络整理Big Data + 深度学习模型本身包括大量的计算并行和数据并行,其实非常匹配利用GPU的硬件结构进行加速。2013年斯坦福的Andrew Ng带领团队实现了一个16个节点CPU+GPU的集群,大大降低了系统造价和成本。不幸的是,该系统现在在解决大数据问题时也遇到了瓶颈问题。
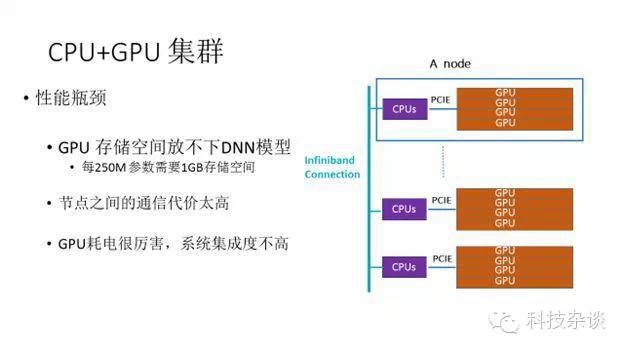
下图显示了Andrew搭建的系统和其性能瓶颈。
每个节点包括2个CPU和4个GPU,一共16个节点组成集群,每层的大量神经元的计算是完全独立的,可以并行进行。
参考文献 Stanford Univ. Andrew Y. Ng etc., “Deep learning with COTS HPC systems”, International Conference on Machine Learning, 2013
CPU+GPU系统的瓶颈问题是由算法本身的并行切分造成的,这个问题比较复杂,今天可能讲不清楚。有感兴趣的私下讨论吧。
五、AMD的研究实践和价值
总结上面所述,Big Data+深度神经网络带来的挑战包括多个层面:算法、应用以及硬件系统设计。AMD DNN团队包括AMD中国研究院和工程团队联合而成,我们从实现加速、硬件系统搭建和应用同时解决。
AMD DNN项目致力于研发基于DNN的软件和硬件解决方案,在软件层面我们实现了主流的多种DNN模型和算法,正在搭建不同规模的语音和图像识别应用,系统设计涵盖两个方向,基于CPU+GPU的硬件解决方案,和基于APU的高密度系统前瞻性研究。AMD的DNN软件解决方案由OpenCL编写而成,OpenCL可以兼容在不同的异构平台上运行。今天时间有限,主要跟大家共享一下基于APU系统设计以及其相对于已有系统的架构优势。
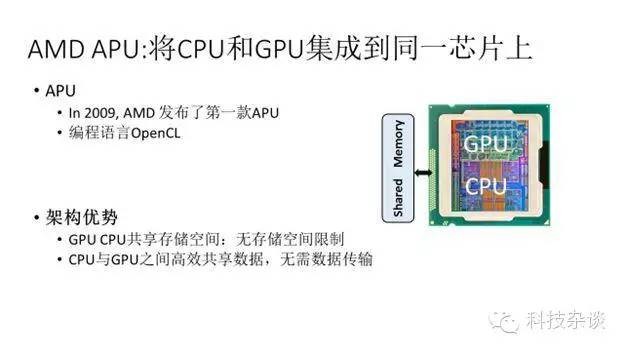
前面我们描述过,DNN的算法非常适合通过GPU加速,然而现在基于CPU+GPU的方式搭建的集群存在GPU存储空间受限和CPU-GPU之间通信代价太大。这个问题从硬件的角度来讲,揭示的是CPU和GPU的耦合程度太松了。AMD的APU架构很好的解决了这个问题
APU是AMD将CPU和GPU整合到同一个芯片上的异构多核处理器,能够实现CPU和GPU的紧耦合和逻辑上的紧密协同合作。下张图显示了APU的体系结构和其架构优势。
我们知道CPU的体积同一个CPU的大小,比GPU要小非常多,因此基于APU可以实现高密度的集群,在同样的空间内集成更多的CPU和GPU的计算能力,提高系统吞吐率,同时降低系统能耗。
设计此系统光有APU还不够, 还需要有专门定制的快速互联硬件和系统框架。AMD2012年收购了高密度server公司SeaMicro,使得我们具备了研制高密度APU系统的条件。下图显示采用高密度集成和定制互联我们可以在一个有限物理空间内,采用3D互联集成512个计算节点。amd中国研究院该图显示的不是产品,而是。
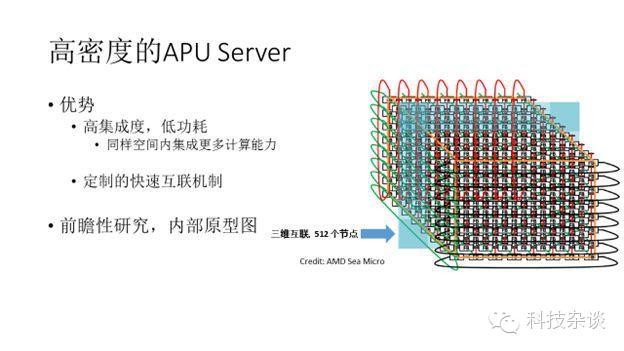
总线访问,APU上有多个总线,根据不同的访问情况选择不同总线,AMD DNN研究小组,初步的研究结果显示APU集群系统相比于CPU+GPU 集群存在的潜在优势如下:
APU系统在同等功耗条件下可以取得2.5倍加速比;在同等性能下可以节省2.5倍系统功耗;
APU系统在同等性能条件下可以节省1.8倍的造价;
在解决 Big Data问题时, APU解决了CPU+GPU集群在的存储空间不够用和节点通信代价太高的两大瓶颈问题。
因此我们看到了APU可以提供一个高密度低功耗的人工智能系统,这是AMD DNN团队的一个研究点之一,希望后续有更多成熟的研究成果跟大家共享。
当然了,我们也在同时搭建基于AMD自己产品的CPU+GPU的分布式平台,已有相关公司采用我们的硬件解决方案。最后提一句,如何最有效的搭建人工智能依赖的硬件系统是一个学术研究课题,除了今天提高的高层次系统搭建方法,还有一些从更底层硬件进行的前瞻性探索和研究, 比如在FPGA上的实现(百度和微软美国),设计专门的集成电路(中科院计算所的陈云霁老师设计神经计算机)。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/dianqi/article-33771-5.html
-

-
宋美龄
请问马先生你能活几个25年
 浙江乃伊集团完全收购台湾“很多管家”
浙江乃伊集团完全收购台湾“很多管家” 重庆20000风量蒸发冷却器制造商欢迎来电
重庆20000风量蒸发冷却器制造商欢迎来电 海尔洗衣机的使用说明
海尔洗衣机的使用说明 Trane中央空调风机盘管3排管12Pa系列HFCF010(大型3.5马力)
Trane中央空调风机盘管3排管12Pa系列HFCF010(大型3.5马力)
应该趁势说明由于国家利益受到美国侵害使相关岛屿军事化