cmt算法_opentld算法_sctp协议
电脑杂谈 发布时间:2017-06-17 08:04:24 来源:网络整理CMT(Clustering of Static-Adaptive Correspondences for Deformable Object Tracking),是一套比较新的跟踪算法,诞生于2014年,原名叫Consensus-based Tracking and Matching of Keypoints for Object Tracking ,当时在计算机视觉应用(Application of Computer Vision)的冬季会议上获得了最佳论文奖,随后于2015年发表在了CVPR上:论文地址。
CMT是一个非常好用且效果超好的跟踪算法,可以跟踪任何场景任何物体;这是一种基于特征的跟踪方法,并且使用了经典的光流法作为算法的一部分。这篇文章不打算分析CMT的代码,因为他的code很容易找到(Github),网上也有很多分析它的code的文章,这篇博客的目的打算结合原论文分析下CMT的主要思想。cmt算法cmt算法
--初始化
step1:(交互)选择待跟踪的物体框PR,计算矩形框中心;
step2:灰度化frame,提取fast特征点,并分离出前景和背景部分的特征点;
step3:创建前景类,即特征点的索引;
step4:将fast特征点生成BRISK特征描述子;
step5:将前景特征点进行归一化;
step6:利用归一化的前景点初始化匹配器(BruteForce-Hamming),生成前景类标签,匹配库;
step7:利用归一化的前景点初始化一致器,生成矩形框内任意点对之间的距离和角度矩阵;
step8:创建初始的有效类和有效点,即前景点的坐标和step6中生成的类标签;
--光流法获取第一部分跟踪点
step1:利用forward-backward 跟踪,提高准确度;
step2:剔除跟踪失败的点;
--全局匹配获取第二部分跟踪点
即全图像与矩形框匹配,这部分的工作对应于论文中的‘3.1 Static-Adaptive Correspondences’;其中code中的thr_dist对应于论文中的,thr_ratio对应于论文中的;
--对两部分跟踪点进行数据融合
即找到两部分中都跟踪到的点,保留下来;
--估计尺度和旋转,进行凝聚聚类
这部分的工作对应于论文中的‘3.2 Correspondence Clustering’;
step1:估计尺度变化;
step2:估计旋转变化;
step3:利用尺度和旋转生成变换矩阵H,即论文中的变换矩阵H;
step4:寻找得到的各特征点之间的一致性,方法是让每一个点为中心投票,这部分的目的是为了使匹配更加准确;
此部分,论文是基于这样一个假设:与目标相关的点肯定都包含在最大的聚类中,于是我们的目的就是通过计算vote点之间的非相度D(对应于论文中的D)来进行投票,最后得到最大的聚类;其中,code中使用的thr_cutoff对应于论文中的,这个参数控制着可容忍的物体的形变程度,当其较小时,往往会导致将所有的点都划为外点outliers,当其较大时,往往能够识别更多的点为内点inliers,当为0时,则表示物体为完全刚性;
注:聚类这部分,论文中作者是调用了一个聚类的库fastcluster来完成实现的;
--利用融合得到的点进行局部匹配;
即矩形框与矩形框匹配,这部分的工作目的是为了去歧义,即为了解决那些完全一样的点或是具有相同描述子的点匹配难的问题,它对应于论文中的‘3.3 Disambiguation of Correspondences’;
--再次进行数据融合
--更新输出的跟踪矩形框
--将该矩形框以及矩形框内的内点作为下一帧的输入,循环
可以发现,CMT的核心就在于以下几个公式:
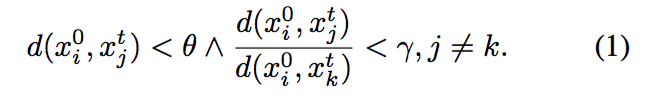
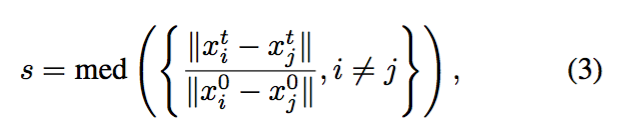
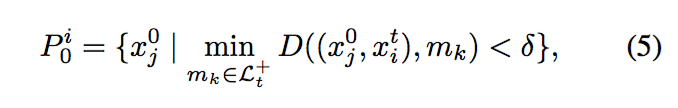
最后,为了更清晰,我将重新注释好的代码附上,应该就好理解了;
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/tongxinshuyu/article-53280-1.html
-

-
段宏娟
这种先人后己
-
 节奏大师刷辅助_节奏大师bug刷_节奏大师刷软件
节奏大师刷辅助_节奏大师bug刷_节奏大师刷软件 各个银行的短信提醒收费标准摘要
各个银行的短信提醒收费标准摘要 mysql存储过程分析
mysql存储过程分析 sdh速率 电信基础知识题库doc下载
sdh速率 电信基础知识题库doc下载
2003年军队就已经进驻台湾