dom xml解析_java dom解析xml_dom解析xml transform(2)
电脑杂谈 发布时间:2017-05-17 19:07:24 来源:网络整理 <?xml version="1.0" ?>
version是必须存在的属性,表明当前xml所遵循规范的版本,目前位置都写1.0就可以了。
<?xml version="1.0" encoding="utf-8" ?>
一定要保证xml格式的数据在保存时使用的编码和解析时使用的编码必须一致,才不会有乱码问题
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>
standalone属性用来指明当前xml是否是一个独立的xml,默认值是yes表明当前文档不需要依赖于其他文档,
如果当前文档依赖其他文档而存在则需要将此值设置为no
(二)元素
元素的语法
一个XML 标签就是一个元素
一个标签分为开始标签和结束标签
在开始标签和结束标签之间可以包含文本内容,这样的文本内容叫做标签体
如果标签的开始标签和结束标签之间不包含标签和子标签则可以将开始标签和结束标签进行合并,这样的标签就叫做自闭标签
一个标签中也可以包含任意多个子标签,但是一定要注意标签一定要合理嵌套
一个格式良好的XML 要包含并且只能包含一个根标签,其他的标签都应该是这个标签的子孙标签
元素的命名
区分大小写,例如,<C>和<c>是两个不同的标记。
不能以数字或标点符号或”_”开头。
不能以xml(或XML、或Xml 等)开头。
不能包含空格
名称中间不能包含冒号(:)。
(三)属性
一个标签可以有多个属性,每个属性都有它自己的名称和取值,例如:<china capital="beijing"/>
属性的名在定义时要遵循和XML 元素相同的命名规则
属性的值需要用单引号或双引号括起来
(四)注释
注释可以出现在XML 文档的任意位置除了整个文档的最前面,不能出现在文档声明之前。
注释不能嵌套注释。dom xml解析
(五)CDATA区/转义字符
当XML中一段内容不希望被解析器解析时可以使用CDATA区将其包住。当解析器遇到CDATA区时会将其内容当作文本对待,不会进行解析
语法:<![CDATA[ 内容 ]]>
转义字符:
& --> &
< --> <
> --> >
" --> "
' --> '
( 六)处理指令
处理指令,简称PI (processing instruction)。处理指令用来指挥解析引擎如何解析XML文档内容。dom xml解析
<?xml-stylesheet type="text/css" href="1.css"?>
XML编程: 利用java程序去增删改查(CRUD) XML 中的数据。
解析思想: DOM解析和SAX解析
1、DOM解析
DOM(Document Object Model) 它是 W3C 组织推荐的处理 XML 的一种方式。它会将整个XML使用类似树的结构保存在内存中,再对其进行操作,所以它需要等到XML完全加载进内存才可以进行操作。它的缺点是耗费内存,当解析超大的XML时慎用。优点是可以方便的对XML 进行增删改查的操作。
在java SE的api提供了org.w3c.dom包里面有Node接口,此接口中提供了很多增删改查节点的方法,而所有文档树的对象都实现这个接口。
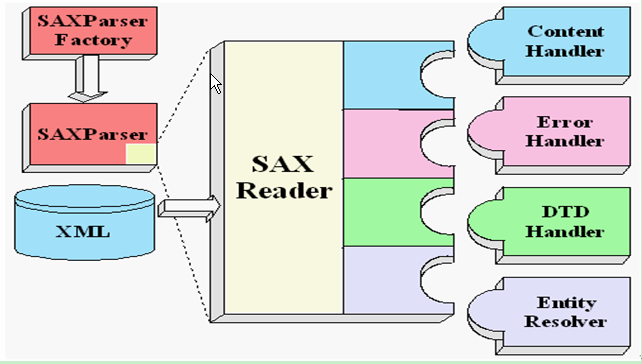
2、SAX解析
这种解析方式会逐行地去扫描XML文档,当遇到标签时会触发解析处理器,采用事件处理的方式解析XML (Simple API for XML) ,不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。优点是:在读取文档的同时即可对XML进行处理,不必等到文档加载结束,相对快捷。不需要加载进内存,因此不存在占用内存的问题,可以解析超大XML。缺点是:只能用来读取XML中数据,无法进行增删改。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/tongxinshuyu/article-47696-2.html
-
 台莹
台莹 -
刘晃
美国欺负到门上了
-
赵令畤
再加上制度的不完善
-
舒川
你说对了
-
 组装的计算机配置:推荐的计算机机箱
组装的计算机配置:推荐的计算机机箱 电信扩招!网友无限流量+500分钟: 经济高效!
电信扩招!网友无限流量+500分钟: 经济高效! C语言strncpy()函数: 复制字符串的前n个字符
C语言strncpy()函数: 复制字符串的前n个字符 现代IX35首次在国内进行ECU的升级和修改工作
现代IX35首次在国内进行ECU的升级和修改工作