基于深度学习的文本情感分析
电脑杂谈 发布时间:2020-01-10 03:02:14 来源:网络整理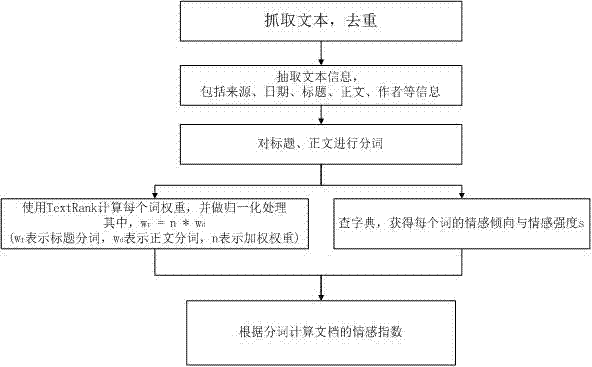
摘要:

随着Web 2.0时代的蓬勃发展,互联网上发生了长期的数据。人们在博客,微博,产品评论,电影评论,网络讨论群等区域留下了相当多的文本信息。这些非结构化的文本中包括了作者的观念,情感,观点或者想法。如果无法从这种非结构化的数据中提取出情感数据,将会加强自动抉择支持、网络舆情风险预测、信息预警、商品销售的发展,在科研或者实际应用中带有相当大的价值。传统的用于缓解文本情感分析问题的方式包含基于常识的技巧,基于统计的方式或者混合的技巧。在数据量不大或者语义不够丰富的之后,这些方式才能获得一定的效果。但是随着数据量越来越大,表达形式越来越丰富,传统的方式尚未能够有效地解决这一类疑问,新的方式亟待提出。深度学习自2006年以来获得了人学术界以及工业界广泛的关注。虽然在整体架构上,基于深度学习的方式与传统的神经网络相同,但是鉴于采用了不同的数据表示方法或者锻炼模式,梯度扩散、过拟合等弊端得到了有效地解决。目前,在图像辨识文本情感分析,语音识别等领域,基于深度学习的方式尚未获得了比传统的机器学习方法更好的效果。卷积神经网络和循环神经网络是深度学习中两个比较有效的建模文本情感分析,前者适合从数据中提取出局部特点,而后者能够有效地预测时序数据。单独地使用这两个模型中的一个难以在文本情感分析任务中获得令人满意的效果,因此发生了由两者一同组成的混合模型。本文针对混合建模中存在的弊端做出了三点改进:优化输入向量序列,将文本转换为等长的输入向量序列;提出一种新的唤醒函数,有效解决了梯度消失的难题并增加了建模的弱化能力;使用Max Pooling技术提取局部特点的最大值。从Yelp2015数据集的实验结果可以看出,本文提出的三点改进是有效的。此外,本文针对建模中非常重要的参数做了多组对比试验,研究了很多参数对于模型的影响。

展开
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/tongxinshuyu/article-136393-1.html
-

-
之侯
很棒
-
萼岭书生
记着了——浙江财经学院的谢做死教授
-
 通过移动储值卡出售的固定无法报销~~
通过移动储值卡出售的固定无法报销~~ 具有两天假,五种保险和一千金基本工资的手机客户服务
具有两天假,五种保险和一千金基本工资的手机客户服务 移动宽带和电信宽带,两者的差距在哪里?说出来你都不敢相信
移动宽带和电信宽带,两者的差距在哪里?说出来你都不敢相信 雅虎冒天下之大不韪 扫描2亿邮箱向广告商出售数据
雅虎冒天下之大不韪 扫描2亿邮箱向广告商出售数据
别以为这是US的强大