TinyHttpd----超轻量型Http Server源码分析(3)
电脑杂谈 发布时间:2019-09-05 12:03:11 来源:网络整理执行CGI脚本,动态页面申请:execute_cgi
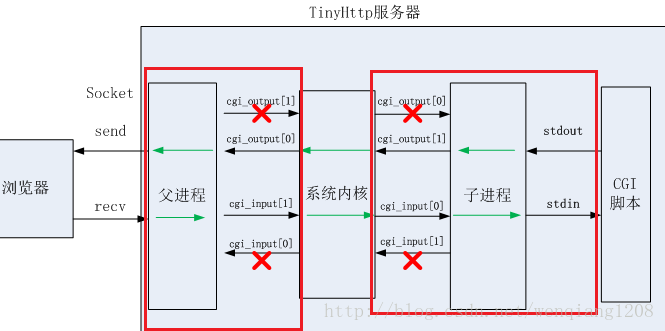
GET 方法用来请求访问已被 URI 识别的资源。指定的资源进服务器端解析后返回响应内容。换言之,如果请求的资源是文本(静态页面请求),那就维持原样返回;如果是像CGI 那样的程序(动态页面请求),则返回经过执行后的输出结果。
结合程序工作步骤看下面代码,更容易理解
/*execute_cgi函数负责将请求传递给cgi程序处理,
服务器与cgi之间通过管道pipe通信,首先初始化两个管道,并创建子进程去执行cgi函数
子进程执行cgi程序,获取cgi的标准输出通过管道传给父进程,由父进程发送给客户端
*/
//参数path指向执行的CGI脚本路径 ,method指向http的请求方法
void execute_cgi(int client, const char *path,
const char *method, const char *query_string)
{
char buf[1024];
int cgi_output[2];
int cgi_input[2];
//cgi_out 是指CGI脚本输出数据的管道
//cgi_input是指向CGI脚本输入数据的管道
pid_t pid;
int status;
int i;
char c;
int numchars = 1;
int content_length = -1;
buf[0] = 'A'; buf[1] = '\0';
//如果是get请求,读取并丢弃头部
if (strcasecmp(method, "GET") == 0)//
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
else /* POST */
{
//如果是post请求
numchars = get_line(client, buf, sizeof(buf));
while ((numchars > 0) && strcmp("\n", buf))
{
buf[15] = '\0';
//读取头信息找到Content-Length字段的值
if (strcasecmp(buf, "Content-Length:") == 0)
//Content-Length:15
content_length = atoi(&(buf[16]));
numchars = get_line(client, buf, sizeof(buf));
}
if (content_length == -1) {
bad_request(client);
return;
}
}
//正确返回200
sprintf(buf, "HTTP/1.0 200 OK\r\n");
send(client, buf, strlen(buf), 0);
//pipe(int filep[2]) 管道函数,f[0]读,f[1]写
//必须在fork()中调用pipe(),否则子进程不会继承文件描述符。
//两个进程必须有血缘关系才能使用pipe。但是可以使用命名管道。
if (pipe(cgi_output) < 0) {
cannot_execute(client);
return;
}
if (pipe(cgi_input) < 0) {
cannot_execute(client);
return;
}
if ( (pid = fork()) < 0 ) {
cannot_execute(client);
return;
}
/*子进程继承了父进程的pipe,然后通过关闭子进程output管道的输出端,input管道的写入端;
关闭父进程output管道的写入端,input管道的输出端*/
if (pid == 0) /* child: CGI script */
{
char meth_env[255];
char query_env[255];
char length_env[255];
//把stdout 重定向到cgi_output[1]
dup2(cgi_output[1], 1);
dup2(cgi_input[0], 0);
close(cgi_output[0]);//关闭cgi_output读端
close(cgi_input[1]); //关闭cgi_input 写端
sprintf(meth_env, "REQUEST_METHOD=%s", method);
putenv(meth_env);
if (strcasecmp(method, "GET") == 0) {
/*设置 query_string 的环境变量*/
sprintf(query_env, "QUERY_STRING=%s", query_string);
putenv(query_env);
}
else { /* POST */
/*设置 content_length 的环境变量*/
sprintf(length_env, "CONTENT_LENGTH=%d", content_length);
putenv(length_env);
}
//exec函数簇,执行CGI脚本,获取cgi的标准输出作为相应内容发送给客户端
execl(path, path, NULL);
exit(0);
}
else
{ /* parent */
close(cgi_output[1]);
close(cgi_input[0]);
/*通过关闭对应管道的通道,然后重定向子进程的管道某端,这样就在父子进程之间构建一条单双工通道
如果不重定向,将是一条典型的全双工管道通信机制
*/
if (strcasecmp(method, "POST") == 0)
for (i = 0; i < content_length; i++) {
recv(client, &c, 1, 0);//从客户端接收单个字符
write(cgi_input[1], &c, 1);
//数据传送过程:input[1](父进程) ——> input[0](子进程)[执行cgi函数] ——> STDIN ——> STDOUT
// ——> output[1](子进程) ——> output[0](父进程)[将结果发送给客户端]
}
while (read(cgi_output[0], &c, 1) > 0)//读取output的管道输出到客户端,output输出端为cgi脚本执行后的内容
send(client, &c, 1, 0);//即将cgi执行结果发送给客户端,即send到浏览器,如果不是POST则只有这一处理
close(cgi_output[0]);//关闭剩下的管道端,子进程在执行dup2之后,就已经关闭了管道一端通道
close(cgi_input[1]);
waitpid(pid, &status, 0);//等待子进程终止
}
}整体代码在GitHub上面:
如果错误,欢迎指出,交流进步,谢谢
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shumachanpin/article-121791-3.html
相关阅读
发表评论 请自觉遵守互联网相关的政策法规,严禁发布、暴力、反动的言论
-

-
长孙铸
-
张舜民
傻帽真的变亲妈呀
每日福利
 初学者的相机镜头型号的含义
初学者的相机镜头型号的含义 宾得645d和佳能5d3_宾得645d 故障_宾得k50致命缺点
宾得645d和佳能5d3_宾得645d 故障_宾得k50致命缺点 如果删除了Excel剪贴板上的内容,如何恢复?
如果删除了Excel剪贴板上的内容,如何恢复? 2019年全画幅单反相机销售清单佳能全画幅单反型号汇总
2019年全画幅单反相机销售清单佳能全画幅单反型号汇总热点图片
你穿的鞋