Linux系统下怎么将进程与CPU绑定到某个CPU
电脑杂谈 发布时间:2021-05-30 17:05:27 来源:网络整理昨天群里的一个朋友问:如何将进程绑定到某个CPU并运行它。
首先,我们先了解一下将进程绑定到 CPU 的好处。
进程绑定CPU的好处:在多核CPU结构中,每个核都有自己的L1、L2缓存,L3缓存是共享的。如果一个进程在内核之间来回切换,每个内核的缓存命中率都会受到影响。反之,如果进程无论怎么调度都可以一直在一个核上执行,那么L1、L2缓存的数据命中率可以显着提高。
所以,将进程绑定到CPU可以提高CPU缓存的命中率,从而提高性能。进程和 CPU 的绑定称为:CPU 亲和性。
设置进程的CPU亲和性
介绍完将进程绑定到CPU的好处之后,现在来介绍一下Linux系统下如何将进程绑定到CPU(即设置进程的CPU亲和性)。
Linux系统提供了一个名为sched_setaffinity的系统调用,它可以设置进程的CPU亲和力。我们来看看sched_setaffinity系统调用的原型:
intsched_setaffinity(pid_tpid, size_tcpusetsize, constcpu_set_t*mask);
下面介绍sched_setaffinity系统调用各个参数的作用:
参数掩码的类型是cpu_set_t,cpu_set_t是一个位图,该位图的每个位代表一个CPU,如下图所示:
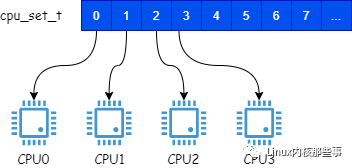
例如,将cpu_set_t的第0位设置为1,表示该进程必须在CPU0上运行。当然,我们可以将进程绑定到要运行的多个CPU。
我们通过一个例子来介绍如何通过sched_setaffinity系统调用来设置一个进程的CPU亲和度:
#define_GNU_SOURCE
# 包含
# 包含
# 包含
#include
# 包含
# 包含
intmain( intargc, char**argv)
{
cpu_set_tcpuset;
CPU_ZERO(&cpuset); // 初始化CPU集,将cpuset置为空
CPU_SET( 2, &cpuset); // 将此进程绑定到 CPU2
//设置进程的CPU亲和性
if(sched_setaffinity(0, sizeof(cpuset), &cpuset) == -1) {
printf("设置 CPU 关联失败,错误:%s\n", strerror(errno));
return-1;
}
return0;
}
CPU 亲和性实现
了解了如何设置进程的 CPU 亲和性后,我们来分析一下 Linux 内核是如何实现 CPU 亲和性功能的。
本文使用的Linux内核版本为2.6.23
Linux内核为每个CPU定义了一个struct rq类型的可运行进程队列,即每个CPU都有一个独立的可运行进程队列。
一般来说,CPU只会从自己的可运行进程队列中选择一个进程来运行。也就是说,CPU0只会从属于CPU0的可运行队列中选择一个进程运行,而永远不会从CPU1的可运行队列中获取。
所以,从以上信息可以分析出,要将一个进程绑定到某个CPU上运行,只需要将该进程放入其所属的可运行进程队列即可。
我们来分析一下 sched_setaffinity 系统调用的实现。 sched_setaffinity 系统调用的调用链如下:
sys_sched_setaffinity
└→ sched_setaffinity
└→ set_cpus_allowed
└→ migrate_task
从上面的调用链可以看出,sched_setaffinity系统调用最终会调用migrate_task函数来完成将进程绑定到CPU的过程。我们来分析一下 migrate_task 函数的实现:
静态
migrate_task(struct task_struct *p, intdest_cpu, struct migration_req *req)
{
structrq * rq = task_rq(p);
// 情况 1:
// 如果进程不在任何运行队列中
// 那么你只需要将进程的cpu字段设置为dest_cpu
if(!p->se.on_rq && !task_running(rq, p)) {
set_task_cpu(p, dest_cpu);
return0;
}
// 情况二:
//如果进程已经在某个CPU的可运行队列中
//然后进程需要从之前的CPU可运行队列迁移到新的CPU可运行队列
//这个迁移过程由migration_thread内核线程完成
// 构建流程迁移请求
init_completion(&req->done);
req->task = p;
req->dest_cpu = dest_cpu;
list_add(&req-> list, &rq->migration_queue);
返回1;
}
首先让我们介绍一下migration_task函数的每个参数的含义:
那么,migrate_task函数的作用就是将进程描述符为p的进程绑定到编号为dest_cpu的目标CPU上。
migrate_task函数主要分两种情况将进程绑定到某个CPU上:
进程迁移过程由__migrate_task函数完成,我们来看一下__migrate_task函数的实现:
staticint
__migrate_task(struct task_struct *p, intsrc_cpu, intdest_cpu)
{
structrq* rq_dest, * rq_src;
intret = 0, on_rq;
...
rq_src = cpu_rq(src_cpu); // 进程所在的原始可运行队列
rq_dest = cpu_rq(dest_cpu); // 进程要放置的目标可运行队列
...
on_rq = p->se.on_rq; // 进程是否处于可运行队列(可运行状态)
if(on_rq)
deactivate_task(rq_src, p, 0); // 从原来的可运行队列中删除进程
set_task_cpu(p, dest_cpu);
if(on_rq) {
activate_task(rq_dest, p, 0); // 将进程放入目标可运行队列
...
}
...
返回;
}
__migrate_task 函数主要完成以下两个任务:
工作流程如下图(将进程从CPU0的可运行队列迁移到CPU3的可运行队列):
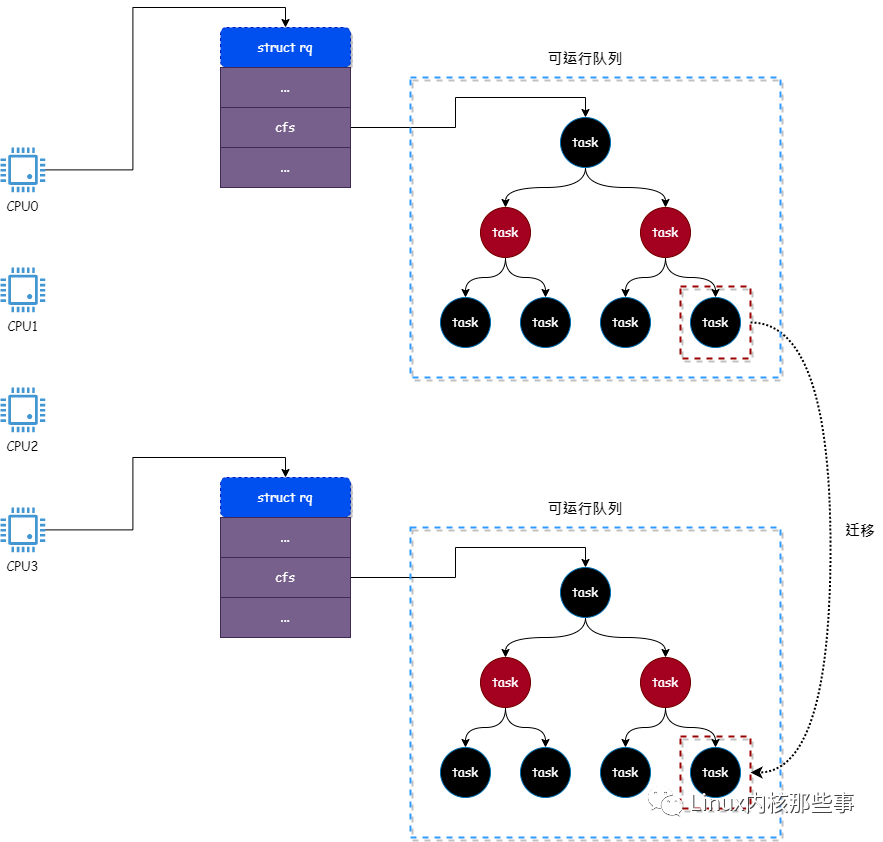
如上图所示,该进程最初位于CPU0的可运行队列中,但是由于该进程已重新绑定到CPU3,因此需要将该进程从CPU0的可运行队列迁移到CPU3的可运行队列。 .
迁移进程首先从CPU0的可运行队列中删除该进程,然后将该进程插入到CPU3的可运行队列中。
当CPU要运行一个进程时,首先从它所属的可运行队列中选择一个进程,并调度这个进程在CPU中运行。
总结
从上面的分析可以看出,将进程绑定到某个CPU,只是将进程放入CPU的可运行队列中。
因为每个CPU都有一个可运行队列,所以可能存在CPU间可运行队列负载不均衡的问题。比如CPU0的可运行队列中的进程比CPU1的可运行队列中的进程多很多,导致CPU0的负载很高,而CPU1的负载很低。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-379227-1.html
-

-
杨恋恋
很棒
-
田剡
即使做好最坏打算
 Java使用有向图的方式进行内存管理:new为对象分配内存
Java使用有向图的方式进行内存管理:new为对象分配内存 最新版本:打桩机APU FM2接口A75主板实际测试的好伙伴
最新版本:打桩机APU FM2接口A75主板实际测试的好伙伴 教程:联想主板正面USB音频接线图(精美)
教程:联想主板正面USB音频接线图(精美) 减少CPU使用量的软件
减少CPU使用量的软件- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
正义的国家站在正义的立场应该坚决予以反击