GPU逐渐强化的双精度运算能力和存储子系统优势
电脑杂谈 发布时间:2021-04-29 10:00:21 来源:网络整理GPU逐渐增强的双精度计算功能和存储子系统优势
从GTX200和HD4870系列图形卡开始,两家主要的制造商都提供了对双精度操作的支持。 HD4870中集成的大型ALU依靠ALU先验电路执行双精度浮点数据操作。 ALU.transcendental的主要功能是完成指令。它可以在每个时钟周期中执行双精度乘法和加法运算。因为它可以每个周期执行160条MULADD指令,这意味着HD4870的峰值双精度计算能力是单精度计算能力(240GFLOPS)的四分之一。但是在正常情况下,HD4870的双精度性能将被视为1/4或1/2,因为在编写通用程序时人们很少会使用ALU.transcendental。此时,程序将显示1/4个单精度MULMAD指令吞吐率或1/2个单精度ADD指令吞吐率。
GTX200内核的每个SM均包含一个双精度64Bit浮点运算单元,该单元为SFU(特殊功能单元,特殊功能单元)。该处理单元可用于协助SP单元处理特殊功能操作,插值属性的顶点+像素阴影以及执行浮点乘法指令(MUL)。 GTX200芯片中的SFU单元不再像G80时代的线程调度程序那样,而是具有完整的线程发布功能,支持单周期的一个乘法和加法+一个连续的加法运算。因此,GT200的双精度计算性能下降是单精度的1/8。这样,GTX200相当于30核双精度64位处理器。根据数据计算,GTX280峰值双精度64Bit浮点运算能力约为90GFLOPS。
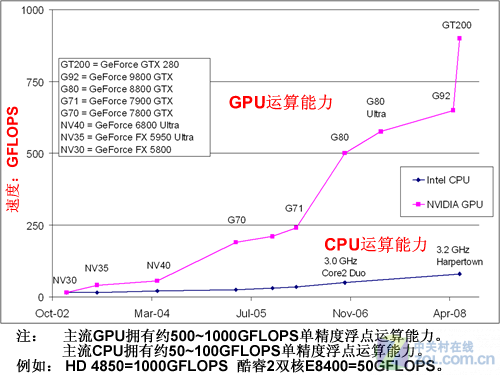
计算能力的比较
当前困扰GPU制造商的主要问题之一是资源的缺乏,尤其是共享寄存器空间的缺乏,因为双精度算术寄存器系统消耗的最大。此处的寄存器是缓存。 NVIDIA将其称为Sharedmemory,而AMD将其称为LDS(本地DataShare)。该共享寄存器位于每个流处理器单元内的所有算术单元中。它负责在常规计算期间共享数据并临时挂起线程。
共享存储空间的改善需要半导体技术的大力支持,因为高速缓存的这一部分使用6TSRAM晶体管(如CPU)。 SRAM的每个位都需要6个晶体管,并且存储密度很低。一个1MB的二级缓存仅需要占用5000万个晶体管,这是一个非常惊人的数字。目前,在CPU的逻辑分布中,辅助缓存所占用的硅芯片面积甚至大于计算核心。在晶体管数量已经非常大的GPU(例如具有14亿个晶体管集成水平的GTX280)中集成大量的缓存甚至更加困难。
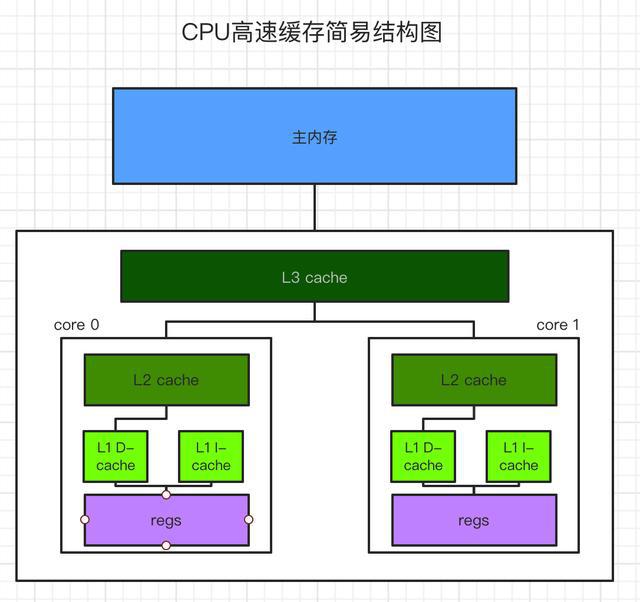

6T-SRAM晶体管形成缓存
具有足够大容量的共享缓存可以提高计算期间线程的挂起能力,这将直接提高GPU的分支计算能力。当提高计算精度时,相同的大容量缓存可以确保较低的性能下降。届时,GPU将具有更强的双精度功能,并且从理论上讲,它将远远超过CPU的单精度计算功能。这样做的直接后果是使GPU更适应混合精度环境,从而使通用计算更进一步。
例如,在将来的DirectX11中,每组流处理器必须具有32k的共享存储空间,以增强GPU的双精度计算能力。另一个例子是在2008年12月,另一个重要的分布式项目SETI @ home宣布正式使用CUDA平台来支持图形计算。 SETI的重要研究方向是从天球背景中接收到的中滤除噪声。这种降噪操作必须依靠混合精度,而GPU支持这种操作的前提是要具有稳定而强大的混合精度计算功能。
GPU计算相对于CPU具有另一个巨大的优势,那就是其内存子系统,即图形卡上的视频内存。当前的台式机顶级产品3通道DDR3-1333的峰值为32GB / S。在实际测量中,由于许多因素,带宽会在20GB / S左右波动。 HD 4870512MB使用超高带宽GDDR5视频存储器,并且存储器总线的数据传输速率为3. 6T / s或107GB / s的总线带宽。 GTX280使用高频GDDR3显存,但其显存控制器支持512bit的位宽,配备16 0. 8nsGDDR3显存,带宽高达142GB / s。主流GPU通常具有40-60GB / s的视频内存带宽。内存的超高带宽可实现稳定的吞吐量,可实现巨大的浮点计算功能,并为数据密集型任务的高效运行提供了保证。
目前,GPU是足够强大的可编程处理器,非常适合于地质勘探,生物学,流体力学,财务建模等科学应用。这使得GPU在地球科学,分子生物学和医学诊断领域的高性能计算应用得以实现,从而有可能实现重大发现,从而改变数十亿人的生活。
GPU架构设计导致的计算能力差异
GTX280总共有十个流处理器阵列,每个阵列有8×3 = 24个流处理器,每个组成8个组,形成SIMT(单指令多任务架构),并共享16K指令缓存,三组SIMT共享第一级缓存。这种标量流处理器设计适合于执行高度并行化的指令,而不管传统的图形渲染,物理加速度计算和数据处理如何。 HD4870也留在后面。 800个高度优化的流处理器由160个流处理单元组成。每个流处理器单元的“ 1大4小”结构包括一个功能齐全的SP单元和4个乘法和加法运算。 SP。它还具有可怕的理论计算能力。
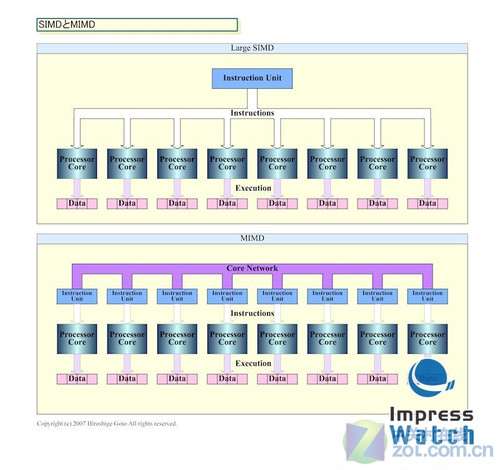
SIDM与MIMD之间差异的例证
应注意,两家图形芯片制造商设计的产品的实际性能无法通过理论峰值性能来估算。例如,由于结构因素,AMD的SIMD + VLIW结构化流处理器几乎无法完全装载所有SP单元。主要原因是科学计算的指令部分没有很多自然的4D指令。 SIMD的最大问题是程序数据必须一致,这意味着当您同时操作5D(4D + 1D)数据时,5D数据必须在同一数据流中,并且5D的相关性是默认。同时,条件分支的数量巨大,因此R600和RV770的体系结构性能与NVIDIA产品相比有一定程度的性能下降。
Radeon HD4870和GTX 280之间最明显的区别是流处理器结构。 Radeon HD4870选择继续使用上一代非统一执行架构GPU产品的SIMD结构,以巨大的规模效应压制对手,并倾向于ILP(指令并行性)方向,而GTX280自G80起采用创新的MIMD架构,并专注于有关TLP(线程并行性)方向的更多信息。在单指令多数据流(SIMD)结构中,单个控制组件将指令分配到每个流水线,并且所有处理组件同时执行同一指令。另一种控制结构是多指令多数据流(MIMD),每个管道可以独立于其他管道执行不同的程序。
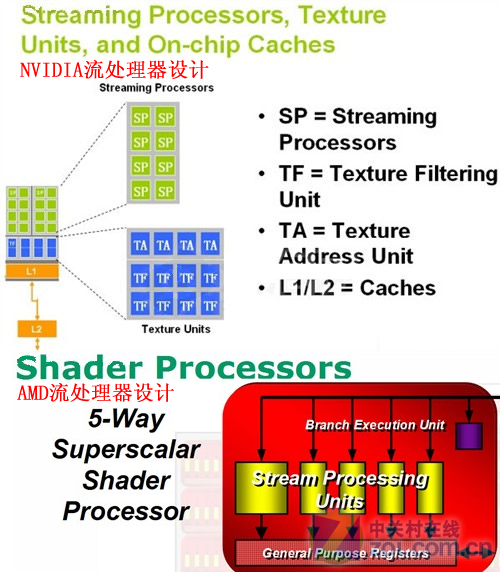
NVIDIA和AMD使用两种不同的流处理器架构
实际上,在上一代非统一执行架构GPU(例如Geforce 6800Ultra)中,顶点着色器管道已由MIMD控制,像素着色器管道继续使用SIMD结构。 MIMD可以更有效地执行分支程序,而SIMD体系结构在运行条件语句时将导致非常低的资源利用率。 TLP需要强大的仲裁机制,丰富的共享缓存和寄存器资源以及足够的,所有这些组件都是晶体管密集型的。但是,SIMD所需的硬件更少,这是一个优势,这就是RadeonHD 4870具有800个流处理器的原因,但其晶体管集成度却低于具有240个流处理器的GTX 280。
此外,在高密度并行计算中,AMD的R600和RV770资源面临一定程度的短缺。以RV770(Radeon HD487 0))为例,每个流处理器单元(“ 1个大4个小” 5个流处理器)都配备了一个,因此,如果要确保不限制指令吞吐量,请通过VLIW ,也就是说,几个短指令以超长指令包装的形式打包在一起,RV770中的VLIW应用程序理论上可以将1 4D + 4 1D装入一个包装中并扔到美国,这可以避免将其传输到美国。但是,如果遇到条件分支,那么不幸的是,此程序包中的1D指令的结果是同一程序包中另一条1D指令的初始条件,并且效率很高。整个架构都会受到影响。
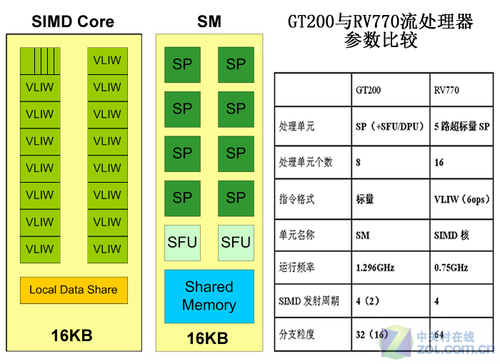
GPU流处理器架构的比较
另一个不能忽略的问题是最小线程执行粒度。粒度越细,可以调用并行机制以覆盖指令延迟的机会就越大,而性能下降的幅度也就越小。精细的粒度偏向TLP方向,这需要大量的GPU线程仲裁机制,这最终会导致过多的硬件开销。我们知道,GPU通用计算中最小的执行单元是线程。多个线程将被打包为一个经线。 NV称其为翘曲,而AMD称其为Frontwave。但是,两家制造商在粒度方面做出了不同的选择。 Frontwave包含64个线程,并且NV的线程管理粒度更小,每个Warp包含32个线程。每次R600和RV770组成64个线程时,仲裁器将执行一次操作,并将Frontwave发送到空闲的SIMDCore。 NV的G80和GT200非常特殊,并且具有“半扭曲”,这意味着可以每16个线程将其发送到SM一次。半经由该线程中的前16个线程或后16个线程组成。
通常,两家供应商之间的区别在于AMD建造了更大的计算单元,而NVIDIA则更加关注如何使用有限的计算资源。 AMD在大量SIMDCore单元中消耗了更多的晶体管,而NVIDIA在仲裁机制,丰富的共享缓存资源和寄存器资源以及足够的中消耗了更多的晶体管。 AMD的GPU更喜欢ILP结构,而NVIDIA则更喜欢TLP结构。 TLP(线程并行性)测试线程功能和并行性,而ILP(指令并行度)测试指令处理。从G80和R600的对抗开始,两家主要的图形芯片制造商一直在延续这种竞争思想。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-371739-1.html
-

-
张宰
-
马凤杰
当心被控告到时候会赔死
 笔记本可以换显卡吗及笔记本更换显卡有什么方法?
笔记本可以换显卡吗及笔记本更换显卡有什么方法? AC97通用声卡驱动程序AC97声卡驱动程序详细说明
AC97通用声卡驱动程序AC97声卡驱动程序详细说明 主板,什么是PCI slot_IT / Computer_Professional信息
主板,什么是PCI slot_IT / Computer_Professional信息![最佳解决方案:[无法读取正在运行的游戏内存]无法读取打开游戏内存的解决方案](http://crawl.nosdn.127.net/7fe86ad6685e8aacc60d6d83256624bb/e0909d52ed451ba5fbe25b656d05bcba.jpg) 最佳解决方案:[无法读取正在运行的游戏内存]无法读取打开游戏内存的解决方案
最佳解决方案:[无法读取正在运行的游戏内存]无法读取打开游戏内存的解决方案- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
第一