内存地址空间布局
电脑杂谈 发布时间:2021-03-13 05:08:26 来源:网络整理多任务操作系统中的每个进程都在其自己的内存沙箱中运行。该沙箱是虚拟地址空间(virtual address space)。
1个32位虚拟内存布局
在32位。探索过程通常需要引用绝对内存地址:堆栈地址,库函数地址等。远程攻击者必须依靠地址空间布局的一致性,并摸索选择这些地址。如果您要求他们猜对了,就会有人纠正。因此,地址空间的随机排列已逐渐流行。 Linux通过向堆栈,内存映射段和堆的起始地址添加随机偏移来破坏布局。不幸的是,32位地址空间非常紧凑,几乎没有随机化的空间,从而削弱了该技术的效果。
堆栈
进程地址空间中最上面的段是堆栈,大多数编程语言都使用它来存储局部变量和函数参数。调用方法或函数会将新的堆栈框架压入堆栈。函数返回时,将清除堆栈框架。也许因为数据严格遵循LIFO的顺序,所以这种简单的设计意味着不需要使用复杂的数据结构来跟踪堆栈的内容,只需使用指向堆栈顶部的简单指针即可。因此,推入和弹出过程非常快速且准确。此外,不断重复使用堆栈空间有助于将活动堆栈内存保留在CPU缓存中,从而加快访问速度。进程中的每个线程都有自己的堆栈。
通过不断将数据推入堆栈,超出其容量,将耗尽与堆栈相对应的存储区域。这将触发页面错误,并由Linux的expand_stack()处理,该扩展将调用acct_stack_growth()来检查是否有合适的堆栈增长空间。如果堆栈的大小小于RLIMIT_STACK(通常为8MB),则在正常情况下,堆栈将被加长,程序将继续快乐地运行,而不会感觉到正在发生什么。这是用于将堆栈扩展到所需大小的常规机制。但是,如果达到最大堆栈大小,则会发生堆栈溢出,并且程序将收到分段错误。当映射的堆栈区域扩展到所需的大小时,即使堆栈不是很满,它也不会收缩。就像联邦预算一样,它总是在增长。
动态堆栈增长是唯一允许访问未映射的内存区域(图中的白色区域)的情况。对未映射内存区域的任何其他访问都将触发页面错误,从而导致分段错误。一些映射区域是只读的,因此尝试写入这些区域也将导致段错误。
内存映射段
堆栈下方是我们的内存映射段。在这里,内核直接将文件的内容映射到内存。任何应用程序都可以通过Linux的mmap()系统调用(实现)或Windows的CreateFileMapping()/ MapViewOfFile()来请求此映射。内存映射是文件I / O的便捷高效方式,因此可用于加载动态库。也可以创建不对应于任何文件的匿名内存映射。此方法用于存储程序数据。在Linux中,如果您通过malloc()请求大量内存,则C运行时库将创建此类匿名映射,而不使用堆内存。 “大块”表示大于MMAP_THRESHOLD,默认值为128KB,可以通过mallopt()进行调整。
堆
说到堆,它是下一个地址空间。像堆栈一样,堆用于运行时内存分配。但是不同之处在于,堆用于存储其生命周期与函数调用无关的数据。大多数语言都提供堆管理功能。因此,满足内存请求已成为语言运行库和内核的共同任务。在C语言中,用于堆分配的接口是malloc()系列函数,而在具有垃圾回收功能的语言(例如C#)中,该接口是new关键字。
如果堆中有足够的空间来满足内存请求,则语言运行库可以对其进行处理,而无需内核的参与。否则,将扩展堆,并通过brk()系统调用(实现)分配请求所需的内存块。堆管理非常复杂,需要复杂的算法来应对程序中混乱的分配模式,并优化速度和内存使用效率。处理堆请求所需的时间可能相差很大。实时系统通过专用分配器解决了这个问题。堆也可能变得碎片化,如下图所示:
图5
BSS数据段代码段
最后,让我们看一下底部的内存段:BSS,数据段,代码段。在C语言中,静态(全局)变量的内容存储在BSS和数据段中。区别在于BSS保存未初始化的静态变量的内容,并且它们的值未直接在程序的源代码中设置。 BSS内存区域是匿名的:它没有映射到任何文件。如果您编写静态int cntActiveUsers,则cntActiveUsers的内容将保存在BSS中。
另一方面,数据段存储在已在源代码中初始化的静态变量内容中。该存储区不是匿名的。它映射程序的二进制映像的一部分,它是具有源代码中指定的初始值的静态变量。因此,如果您编写静态int cntWorkerBees = 10,则cntWorkerBees的内容将保存在数据段中,并且初始值为10。尽管该数据段映射了一个文件,但它是一个私有内存映射,这意味着更改内存这里不会影响映射文件。情况也必须如此,否则为全局变量分配值将更改硬盘上的二进制映像,这是不可想象的。
下图中的数据段示例更加复杂,因为它使用了指针。在这种情况下,指针奇闻趣事(4字节内存地址)本身的值存储在数据段中。它指向的实际字符串不在此处。该字符串存储在代码段中。该代码段是只读的。它可以保存您所有的代码以及点点滴滴,例如字符串文字。该代码段还将您的二进制文件映射到内存,但是写入该区域将导致您的程序收到分段错误。这有助于防止指针错误,尽管在用C进行编程时不如采取预防措施有效。下图显示了这些段和示例中的变量:
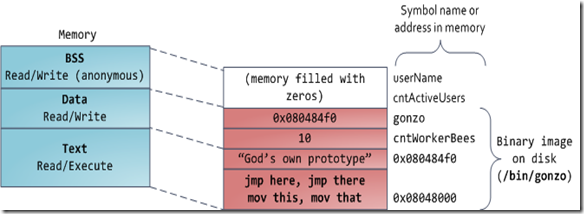
图6
您可以通过读取文件/ proc / pid_of_process / maps来检查Linux进程中的内存区域。请记住,一个细分可能包含许多区域。例如,每个内存映射文件在mmap段中都有其自己的区域,而动态库具有类似于BSS和数据段的其他区域。下一篇文章解释了这些“区域”(区域)的真正含义。有时人们指的是“数据段”,即整个数据段+ BSS +堆。
2个64位虚拟内存布局
64位系统具有相对较大的寻址空间,因此仍使用经典的32位布局,但是添加了一个随机的mmap起始地址以防止溢出攻击。无论如何,如此大的内存地址将不会使用一段时间,因此至少N不会改变很多年。
首先,大多数当前的操作系统和应用程序不需要如此大的16EB(264)地址空间。实现64位地址只会增加系统的复杂性和地址转换的成本,并且不会带来任何好处。因此,当前的x86-64架构CPU遵循AMD的Canonical形式,即,仅虚拟地址的最低48位将用于地址转换,任何虚拟地址的48至63位必须与47位保持一致(标志扩展名)。换句话说,虚拟地址总空间为256TB(248)。
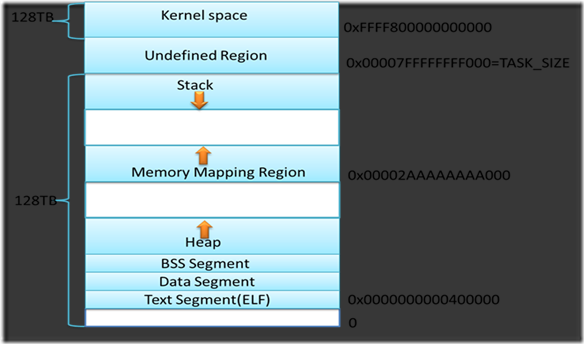
图7
然后,在此256TB虚拟内存空间中,00000-00007fffffffffff(128TB)是用户空间,而ffff8-ffffffffffffffffff(128TB)是内核空间。这里应该注意的是,内核空间中有很多空洞,它超出了第一个空洞。在一个空洞之后,ffff880000000000-ffffc7ffffffffff(64TB)是直接映射物理内存的区域,也就是说,默认的PAGE_OFFSET为ffff88000000000 0.从这里,我们还可以看到,如此大的直接映射区域足以映射所有物理内存,因此,在x86-64架构下,目前没有高端内存,即ZONE_HIGHMEM(请参阅上一篇文章)
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-364149-1.html
 谁将成为跑分的赢家? 2016年8月手机性能排名前10名
谁将成为跑分的赢家? 2016年8月手机性能排名前10名 hahadaxiao20122k11最低配置要求Model3.0显卡推荐
hahadaxiao20122k11最低配置要求Model3.0显卡推荐 谁更节能?四次浏览器内存使用评估
谁更节能?四次浏览器内存使用评估 冷却风扇的一些误解!新手必看
冷却风扇的一些误解!新手必看- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
干净