CPU管道_计算机硬件和网络_IT /计算机_数据(2)
电脑杂谈 发布时间:2021-01-03 04:07:04 来源:网络整理所有三个执行单元都可以执行基本的算术运算或执行更复杂的微指令。但是每个执行单元都擅长执行不同种类的微指令,从而使它们在执行操作时效率更高。在理想条件下,当今乱序的执行组件可以在一个时钟周期内执行11条微指令。最后,将执行微指令,并且在几个流水线阶段之后,它们最终将退出流水线。此时,指令完成并且指令指针增加。但是从程序员的角度来看,指令仅从一端进入CPU,而从另一端退出,就像旧的8086一样。如果您仔细阅读了以上内容,将会注意到上面提到的一个重要问题:在执行指令的位置发生跳转?例如,当指令运行到“ if”或“ switch”时会发生什么?在较旧的处理器中,这意味着清除流水线,并等待要执行的新跳转目标指令的提取。当CPU指令队列中存储100条以上的指令时,由于管道阻塞而导致的性能损失非常严重。所有指令都需要等待跳转目标的指令被获取并重新启动管道。在这种情况下,乱序执行组件需要取消跳转指令之后已执行的所有微指令,并返回到执行前的状态。当所有乱序执行的微指令退出乱序执行单元时,它们将被丢弃,然后从新地址执行。这对于处理器来说相当困难,而且经常发生,因此对性能有很大影响。
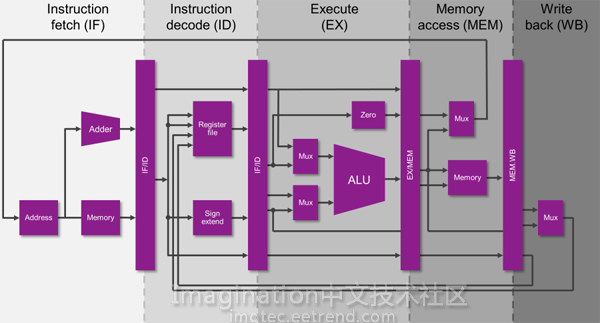
这时,引入了乱序执行组件的另一个重要功能。答案是猜测执行。推测执行意味着当遇到分支指令时,乱序执行组件将执行所有分支指令。一旦确定了分支指令的跳转方向,所有具有错误跳转方向的指令都将被丢弃。通过同时在两个跳转方向上执行指令,避免了由分支跳转引起的阻塞。处理器设计人员还发明了分支预测缓存,该缓存可预测何时面对多个分支,从而进一步提高性能。尽管仍然发生CPU阻塞,但是此解决方案将CPU阻塞的可能性降低到可接受的范围。最后,具有超线程的处理器将两个虚拟处理器公开给共享的无序执行单元。它们共享一个重新排序的缓存和无序执行组件,因此操作系统认为它们是两个独立的处理器,看起来像这样:超线程处理器具有两个虚拟处理器,它们可以给出无序执行该组件提供更多数据。超线程可以提高通用应用程序的性能,但是对于某些计算密集型应用程序,超线程将迅速使乱序的执行组件饱和。在这种情况下,超线程将稍微降低性能。但是这种情况毕竟很少见,超线程通常可以为日常应用程序提供大约两倍的性能。这一切的一个例子似乎有点令人困惑,所以让我们举一个例子来弄清楚。从应用程序的角度来看,就像旧的8086处理器一样,我们仍在指令流水线上运行。
处理器是一个黑匣子。黑匣子将处理指令指针所指向的指令,并且在处理后,将在内存中找到处理后的结果。但是从指令本身的角度来看,这一过程经历了沧桑。让我们介绍一下当今处理器中的指令处理过程(大约在2008年至2013年之间)。首先,您是一条指令,并且您所属的程序正在运行。您一直在耐心等待指令指针指向您自己,等待由CPU执行。当指令指针距离您4KB(约1500条指令)时,CPU会将您访问该指令到指令缓存中。尽管从内存加载到指令高速缓存需要花费一些时间,但距离执行的那一刻还很遥远,并且您有足够的时间。此预取过程属于管道的第一阶段。当指令指针离您越来越近并且距离您仍有24条指令时,您和您旁边的5条指令将被放置在指令队列中。该处理器具有4个,可容纳一个复杂的指令和最多三个简单的指令。您碰巧是一条复杂的指令。通过解码,您将被翻译成4个微指令。解码过程可以分为多个步骤。解码过程中的第一步是检查所需数据,并猜测您可能会有地址跳转。检测到所需的其他数据后,无需通知您,该数据将开始从内存加载到数据缓冲区中。您的四个微指令到达了寄存器重命名表。
您告诉它需要读取哪个内存地址(例如fs:[eax + 18h]),然后寄存器重命名表将该地址转换为临时地址以供微指令使用。地址转换完成后,您的微指令将进入重排序缓冲区(ROB)并记录指令的顺序。然后首次进入预留站(RS)。保留站用于存储准备好执行的指令。立即选择您的第三个微指令,并将其发送到端口5。该端口直接执行计算。但是您不知道为什么会首先选择它,实际上它确实已执行。在几个时钟周期后,您的第一个微指令将转到端口2,即装载地址执行单元。其余的微指令一直在等待,每个端口都在收集不同的微指令。他们都在等待端口2从缓存和内存中加载数据并将其放入临时存储空间。他们等待了很长时间……很长时间……但是当他们等待第一个微指令返回数据时,其他新的指令又来了。幸运的是,处理器知道如何使这些指令不按顺序执行(也就是说,将首先执行到达保留站的微指令)。当第一个微指令返回数据时,其余两个微指令立即发送到执行端口0和1。现在这4条微指令已经执行,最终它们将返回到保留站。
这些微命令返回其“票证”并提供其临时地址。通过这些地址,可以将它们合并为完整的说明。最后,CPU将为您提供结果并退出。当您到达标有“出口”的门时,您将在这里找到一个队列。输入后,您发现自己正站在前面的传入指令的后面。即使执行顺序可能有所不同,但退出的顺序仍然相同。似乎乱序执行组件确实知道它做了什么。最终,每条指令都以与指令指针所指顺序相同的顺序一次离开一条CPU!结束语我希望这篇简短的文章可以向读者展示处理器工作的一些奥秘,这不是魔术。让我们回到最初的问题,现在我们应该能够给出一些更好的答案。处理器内部如何工作?在这个复杂的过程中,首先将指令分解为较小的微指令,然后以无序的方式尽快执行它们,然后按原始顺序提交执行结果。因此,从指令的内容以及相邻缓存的大小和内容有关。
一条指令通过处理器的时间最短,但是可以粗略地说,这个时间是恒定的。一个好的程序员和编译器可以使许多指令同时运行,因此为每条指令分配的时间几乎为零。这里提到的几乎为零的执行时间并不意味着一条指令的总执行时间非常短。相反,通过整个无序部分读取和写入数据并等待内存需要大量时间。新处理器具有12级或18级,甚至更深的31级流水线意味着什么?这意味着可以将更多指令同时发送到加工厂。非常深的流水线可以允许同时处理数百条指令。当一切顺利时,乱序的组件可以保持高速运行,从而获得惊人的吞吐量。不幸的是,深层次的流水线还意味着流水线停滞可以从相对可忍受的性能损失变为可怕的性能噩梦。因为必须停止数百条指令,所以等待管道恢复操作。如何根据此信息优化程序?幸运的是,CPU在大多数情况下都可以正常工作,并且编译器已经针对乱序处理器进行了近20年的优化。当指令和数据按顺序执行时(无烦人的跳转),CPU可获得最佳性能。因此,首先,使用简单的代码。简单明了的代码将帮助编译器的优化引擎识别和优化代码。尽量不要使用跳转指令。当您必须跳时,每次尝试跳向相同的方向。
复杂的设计(例如动态跳转表)虽然看起来很酷并且可以完成非常强大的功能,但是处理器和编译器都无法执行良好的预测处理,因此复杂的代码非常复杂,可能会导致流水线停顿和猜测错误,这会大大损害处理器性能。其次,使用简单的数据结构。保持数据顺序,相邻和连续可以防止数据停顿。使用正确的数据结构和数据分布可以极大地提高性能。只要使代码和数据结构尽可能简单,其余的工作就可以安全地移交给编译器的优化引擎来完成。感谢您和我一起参加这次旅行!
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-345153-2.html
- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
会在网上实名揭露吗