CPU缓存行:CPU缓存行/缓存块
电脑杂谈 发布时间:2020-12-31 12:03:49 来源:网络整理目录
前言
代码由CPU运行。我们的代码编写得好坏决定了CPU的执行效率。尤其是在编写计算密集型程序时,要特别注意CPU的执行效率,否则会大大影响系统性能。
CPU缓存嵌入在CPU内部。它的存储容量很小,但是非常接近CPU内核,因此缓存的读写速度非常快。然后,如果CPU正在运行,则直接从CPU缓存读取数据。如果从数据而不是从内存中获取数据,则计算速度将非常快。
但是,大多数人不了解CPU缓存的操作机制,因此他们不知道如何编写可用于CPU缓存的代码。一旦掌握了它,在编写代码时,就会有新的Optimize思想。
那么,让我们看一下CPU缓存是什么样的,它是如何工作的,以及如何编写使CPU更快执行的代码?

CPU缓存有多快?
您可能想知道为什么仍需要内存使用CPU缓存?根据摩尔定律,CPU的访问速度每18个月增加一倍,相当于每年增长约60%。当然,内存的速度将继续提高,但是增长率远远低于CPU的增长率,CPU的增长率每年仅约7%。结果,CPU和内存访问性能之间的差距继续扩大。
到目前为止,内存访问所需的时间超过200至300个时钟周期,这意味着CPU和内存的访问速度相差200至300倍。
为了弥补CPU和内存之间的性能差异,在CPU内部引入了CPU高速缓存(也称为高速缓存)。
CPU缓存通常分为三个大小不同的缓存级别,即L1缓存,L2缓存和L3缓存。
由于CPU高速缓存使用的材料是SRAM,因此价格远高于内存使用的DRAM。如今,生产1 MB CPU Cache的成本为7美元,而内存仅花费0.015美元,成本差是466倍,因此CPU Cache并不是像内存一样随意以GB计算的,其大小以KB或MB计算。
在Linux系统中,我们可以使用下图查看所有级别的CPU缓存的大小。例如,在我的服务器上,最接近CPU内核的L1缓存为32KB,其次是256KB的L2缓存。最大的三级缓存为3MB。

其中,L1缓存通常分为“数据缓存”和“指令缓存”,这意味着数据和指令分别在L1缓存层缓存。上图中的Index0是数据缓存,而index1是指令缓存,两者的大小通常是相同的。
此外,您还将注意到L3缓存比L1缓存和L2缓存大得多。这是因为L1缓存和L2缓存对于每个CPU内核都是唯一的,而L3缓存由多个CPU内核共享。
执行程序时,内存中的数据将被加载到共享的L3缓存中,然后被加载到每个内核的唯一L2缓存中,最后被加载到最快的L1缓存中,然后由CPU读取。它们之间的层次关系,如下所示:
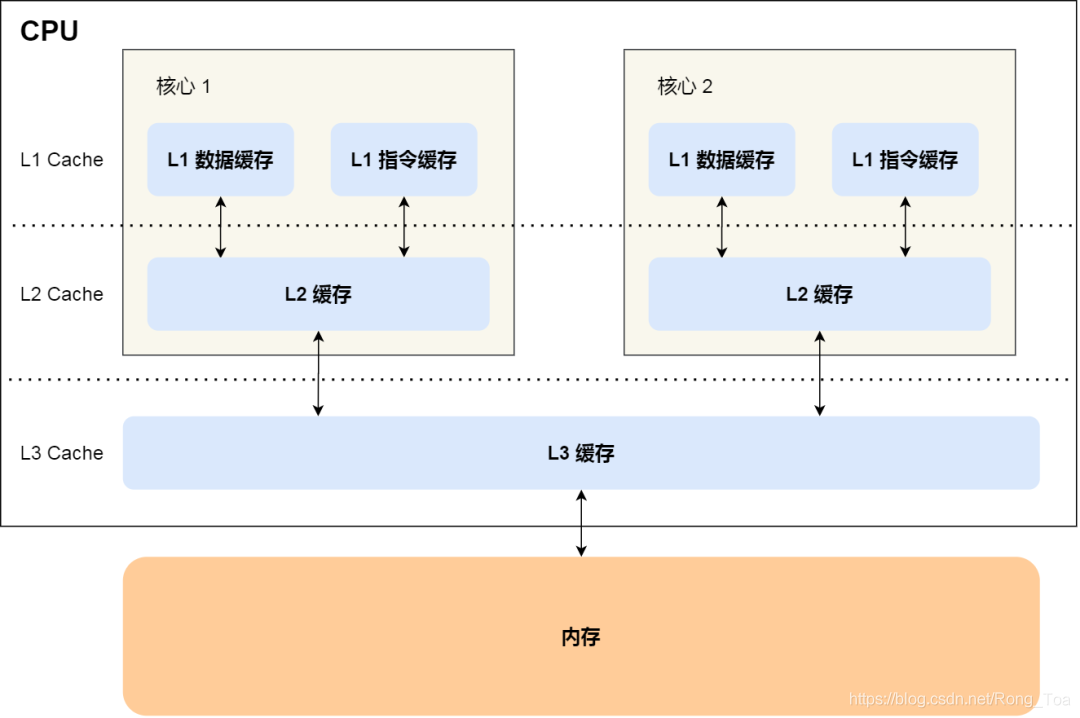
缓存离CPU内核越近,访问速度就越快。 CPU仅需要2到4个时钟周期访问L1缓存,大约10到20个时钟周期访问L2缓存,大约20到60个时钟周期访问L3缓存。内存访问速度约为200到300个时钟周期。下表:
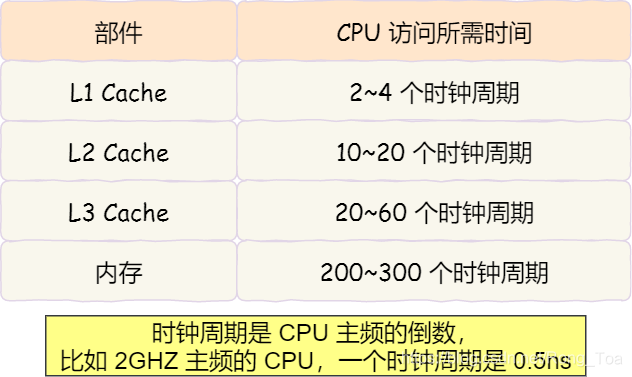
因此,CPU从L1缓存读取数据的速度比从内存读取数据的速度快100倍以上。
CPU Cache的数据结构和读取过程是什么?
从存储器中读取CPU高速缓存的数据。它按小块读取数据,而不是根据单个数组元素读取数据。在CPU缓存中,这样的一小部分数据称为缓存行(缓存块)。
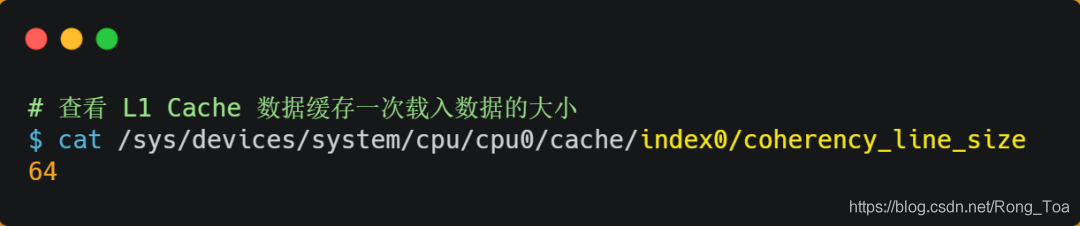
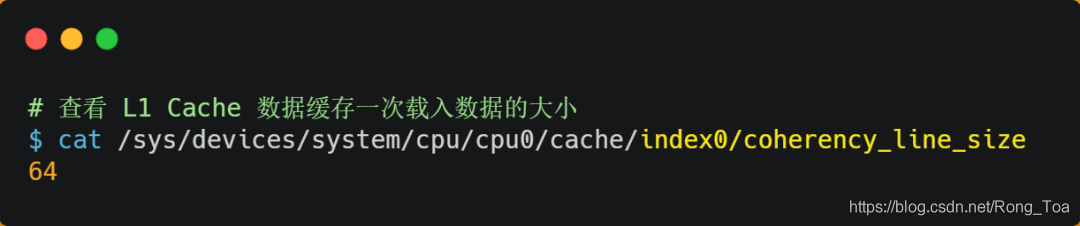
您可以使用以下方法在Linux系统上查看CPU缓存行。您可以看到我的服务器的L1缓存行的大小为64字节,这意味着L1缓存一次加载数据。它是64个字节。
例如,有一个整数数组[100]。加载array [0]时,由于数组元素的大小在内存中仅占用4个字节,小于64个字节,因此CPU将按顺序将数组元素加载到array [15],这意味着array [0] 〜array [15]数组元素将被缓存在CPU缓存中,因此,下次访问这些数组元素时,将直接从CPU缓存中读取它们,而不是从存储介质中读取,从而大大提高了CPU读取数据的性能。
实际上,当CPU读取数据时,无论数据是否存储在缓存中,CPU都会首先访问缓存。仅当无法在缓存中找到数据时,它才会访问内存并将数据保存在内存中。读入缓存,CPU从CPU缓存中读取数据。
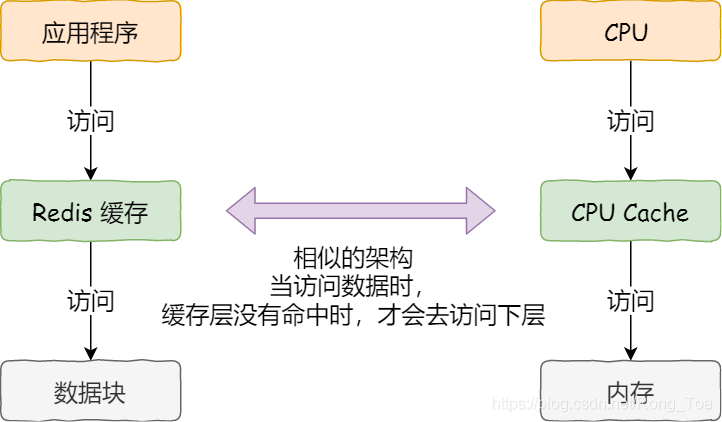
这种访问机制与我们使用“内存作为硬盘缓存”的逻辑相同。如果内存中有缓存的数据,它将直接返回,否则,它将以正常速度访问硬盘。
然后,CPU如何知道要访问的内存数据是否在缓存中?如果是这样,如何找到与Cache相对应的数据?让我们从最简单和基本的直接映射缓存(Direct Mapped Cache)开始,然后看一下整个CPU缓存的数据结构和访问逻辑。

之前,我们提到过,当CPU访问存储器数据时,它会读取少量数据。这小块数据的具体大小取决于coherency_line_size的值,该值通常为64个字节。在内存中,这条数据称为博克(Bock)。读取时,我们需要获取数据所在的内存块的地址。
直接映射高速缓存所采用的策略是始终将内存块的地址“映射”到CPU行(高速缓存块)的地址。至于映射关系的实现,它使用“模运算”和模运算。结果是与内存块地址相对应的CPU行(缓存块)的地址。
例如,内存分为32个内存块,CPU高速缓存具有8条CPU行。假设CPU要访问第15个存储块。如果第15个内存块中的数据已缓存在CPU行中,则必须将其映射到7号CPU行中,因为15%8的值是7。
如果您很机智,那么您一定已经发现,如果使用模映射,将有多个内存块对应于同一CPU Line。例如,在上面的示例中,除了在第7号CPU行中映射了第15号存储块外,还有映射到第7号的第7号,第23号和第31号存储块CPU线。
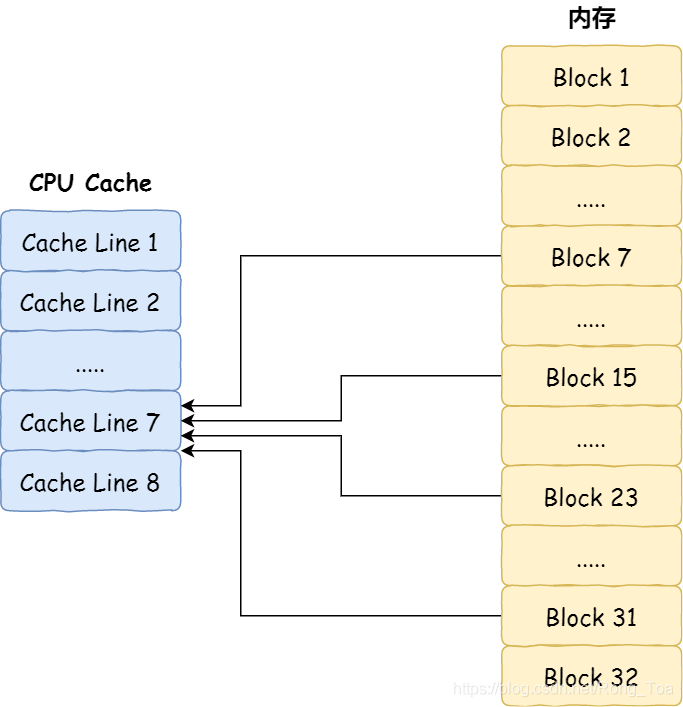
因此,为了区分不同的存储块,我们还将在相应的CPU Line中存储一个组标签(Tag)。该组标记将记录与当前CPU行中存储的数据相对应的存储块。我们可以使用该组标记来区分不同的内存块。
除了组标签信息外,CPU Line还具有两个信息:
CPU从CPU高速缓存读取数据时,它不会读取CPU线路中的整个数据块,而是会读取CPU所需的一条数据。这些数据统称为单词。然后,如何在相应的CPU线的数据块中找到所需的字?答案是需要偏移量。
因此,存储器的访问地址包括三种类型的信息:组标记,CPU Line索引和偏移量,因此CPU可以使用这些信息在CPU缓存中查找缓存的数据。对于CPU缓存中的数据结构,它由索引+有效位+组标记+数据块组成。
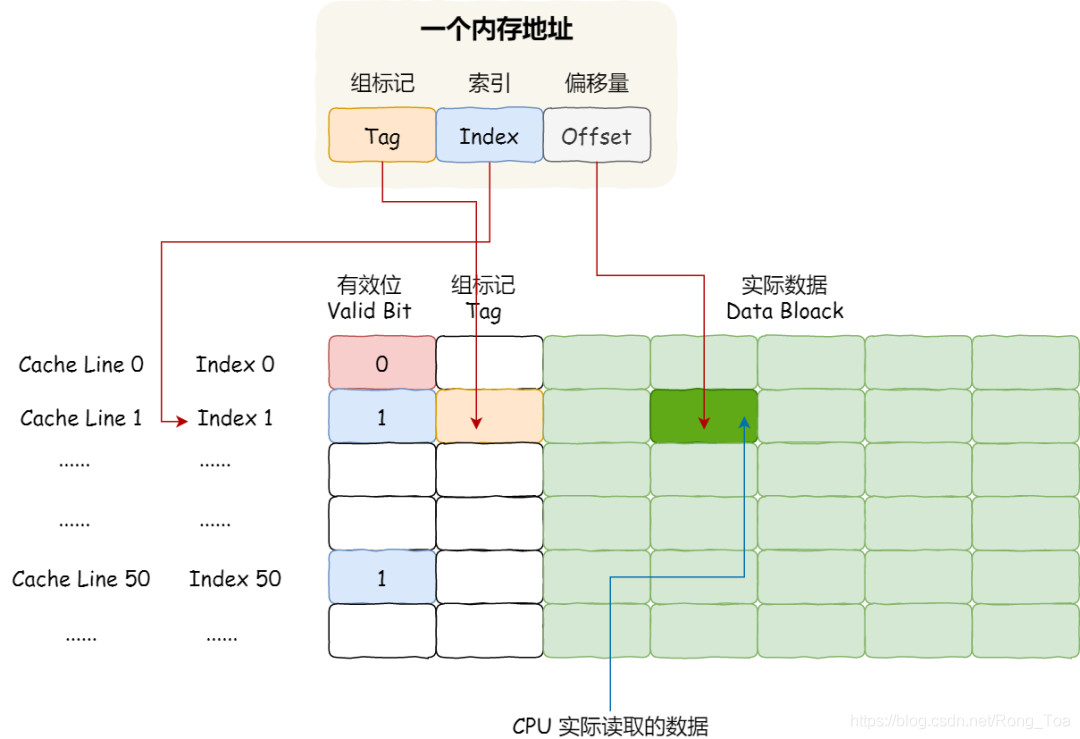
如果内存中的数据已经在CPU缓存中,则当CPU访问内存地址时,它将经历以下4个步骤:
根据内存地址中的索引信息,计算CPU Cahe中的索引,即找到对应的CPU Line的地址;
找到相应的CPU线后,判断CPU线中的有效位并确认CPU线中的数据是否有效。如果无效,CPU将直接访问内存并重新加载数据。如果数据有效,请转到“执行”;
将内存地址中的组标签与CPU行中的组标签进行比较,以确认CPU行中的数据是否是我们要访问的内存数据。如果不是,CPU将直接访问内存并重新加载数据;如果是,则执行下来;
根据存储器地址中的偏移量信息,从CPU Line的数据块中读取相应的字。
在这里,我相信您对直接映射Cache有一定的了解,但是实际上,除了直接映射Cache之外,还有其他策略可以通过内存地址在CPU Cache中查找数据,例如Fully Associative Cache,Set Associative缓存(设置关联缓存)等。这些策略的数据结构相对相似。我们了解流如何直接映射Cache。如果您有兴趣研究其他策略,相信您很快就会了解。
如何编写使CPU运行更快的代码?
我们知道CPU访问内存的速度比CPU访问CPU缓存的速度慢100倍以上,因此,如果CPU要处理的数据在CPU缓存中,将会带来很大的性能提升。如果访问的数据在CPU高速缓存中,则表示高速缓存已命中。缓存命中率越高,代码的性能越好,CPU运行得越快。
因此,“如何编写使CPU运行更快的代码”问题可以更改为“如何编写具有较高CPU缓存命中率的代码”。
正如我前面提到的,L1缓存通常分为“数据缓存”和“指令缓存”。这是因为CPU分别处理数据和指令。例如,操作1 + 1 = 2,+是指令,将其放置在“命令缓存”中,将输入数字1放置在“数据缓存”中。
因此,我们必须分别查看“数据缓存”和“指令缓存”的缓存命中率。
如何提高数据缓存的命中率?
假设您要遍历二维数组,有以下两种形式。尽管代码执行结果相同,但是您认为哪种形式最有效?为什么高?

经过测试,一个数组[i] [j]的执行时间比两个数组[j] [i]的执行时间快几倍。
之所以存在如此大的差距,是因为二维数组数组所占用的内存是连续的。例如,如果长度N的值为2,则数组元素在内存中的布局顺序如下:

表1使用array [i] [j]访问数组元素的顺序与存储在内存中的数组元素的顺序相同。当CPU访问array [0] [0]时,由于数据不在缓存中,因此它将“依次”将以下3个元素从内存加载到CPU缓存中,以便当CPU访问接下来的3个数组元素时到时候,可以在CPU缓存中成功找到数据,这意味着缓存命中率非常高,并且缓存命中的数据不需要访问内存,从而大大提高了代码的性能。
如果您使用形式二的array [j] [i]进行访问,则访问顺序为:

如您所见,访问方法被跳过,而不是顺序访问,因此,如果N的值很大,则无法操作array [j] [i] [i]的方法也被读入CPU缓存中,由于array [j + 1] [i]尚未读取CPU缓存,因此需要从内存中读取数据元素。显然,这种对数据元素的不连续,跳转类型的访问可能无法充分利用CPU高速缓存的特性,因此代码的性能并不高。
当访问array [0] [0]元素时,CPU将从内存向CPU高速缓存加载多少个元素?正如我们前面提到的,此问题与CPU缓存行有关。它代表一次CPU缓存性能负载数据的大小。您可以通过Linux中的coherency_line_size配置检查其大小,通常为64个字节。
换句话说,当CPU访问内存数据时,如果数据不在CPU缓存中,它将一次连续地将64个字节的数据加载到CPU缓存中。然后,在访问array [0] [0]时,由于该元素小于64个字节,因此array [0] [0]〜array [0] [15]将被顺序读取到CPU缓存中。顺序访问数组[i] [j]利用了此功能,因此它比跳转访问数组[j] [i]更快。
因此,在遇到遍历数组的情况时,以内存布局的顺序访问它们将有效地利用CPU缓存的优势,从而大大提高我们代码的性能。
如何提高指令缓存的命中率?
提高数据的高速缓存命中率的方法是按内存布局的顺序访问数据。如何改善指令的缓存?
让我们举个例子来看,有一个一维数组,它由0到100之间的随机数组成:

接下来,对该数组执行两项操作:

那么问题是,您认为遍历然后排序,还是先排序然后遍历更快?
在回答这个问题之前,让我们首先了解CPU的分支预测器。对于if条件语句,这意味着至少您可以选择跳到两条不同的指令执行,即if或else中的指令。然后,如果分支预测可以预测if中的指令或else指令将被执行,则可以“提前”将这些指令放入指令高速缓存中,以便CPU可以直接从高速缓存中读取指令,因此执行速度很快。
当数组中的元素是随机元素时,分支预测将无法有效工作,而当数组中的元素是顺序元素时,分支预测器会根据历史命中数据动态预测未来,因此命中率将会很高。
因此,排序然后遍历的速度将更快。这是因为排序后,数字从小到大,所以如果
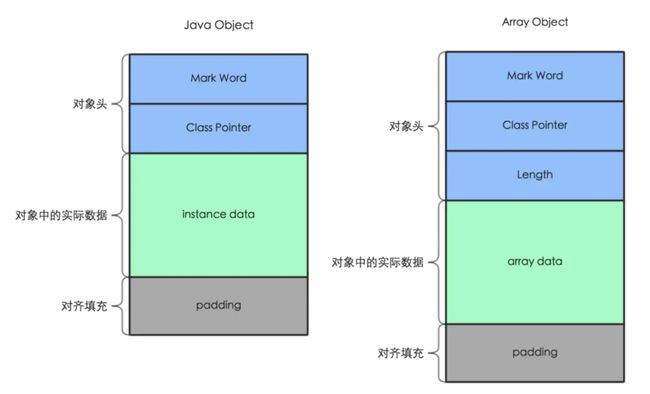
如果您确定代码中的if表达式具有较高的判断正确率的可能性,则可以使用显示分支预测工具。例如,在C / C ++语言中,编译器提供了两个宏,分别是like和different,如果if条件的概率为true,则可以使用like宏将表达式包装在if中,否则使用different宏
实际上,CPU本身的动态分支预测相对准确,因此仅当您非常确定CPU不能准确预测并且可以知道实际概率时,才建议使用这两个宏。
如何提高多核CPU的缓存命中率?
在单核CPU中,尽管只能执行一个进程,但是操作系统会为每个进程分配一个时间片。当时间片用完时,将调度下一个进程,因此每个进程将根据该时间片交替占用CPU,从宏的角度来看,每个进程都在同时执行。
现代CPU都是多核的。进程可以在不同的CPU内核之间来回切换。这对CPU缓存无益。尽管L3缓存在多个内核之间共享,但是L1和L2缓存对于该内核都是唯一的,但是,如果进程在不同内核之间来回切换,则每个内核的缓存命中率都会受到影响。相反,如果所有进程都在同一内核上执行,则可以有效获得其数据的L1和L2 Cache的高速缓存命中率。高速缓存命中率高意味着CPU可以减少访问内存的频率
当有多个线程同时执行“计算密集型”时,为了防止高速缓存命中率由于切换到不同的内核而降低,我们可以将线程绑定到某个CPU内核以实现此性能。得到很大的进步。
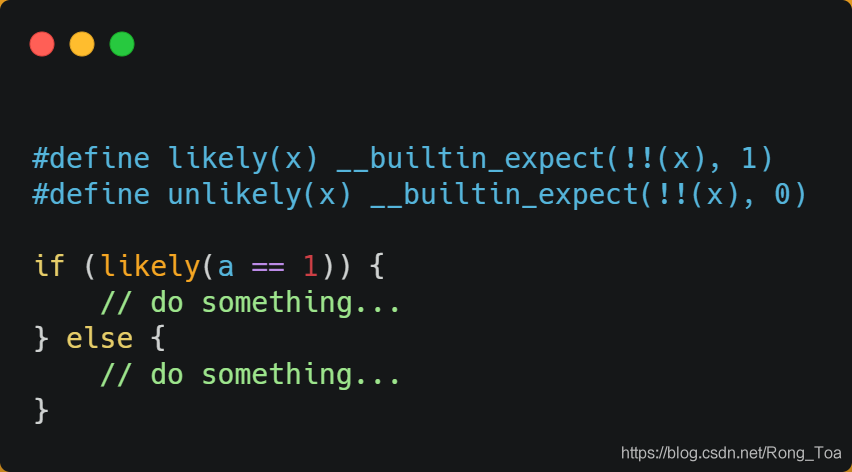
Linux上提供了sched_setaffinity方法,以实现将线程绑定到特定CPU内核的功能。
摘要
随着计算机技术的发展,CPU和内存之间的访问速度差异越来越大。现在差距是数百倍,因此CPU缓存组件作为内存和CPU之间的缓存层嵌入到CPU中。 CPU缓存非常接近CPU内核,因此访问速度也非常快,但是由于所需的材料成本较高,因此它不像几GB的内存,而只有几十KB到MB大小。
CPU访问数据时,首先访问CPU缓存。如果缓存命中,则直接返回数据,因此无需每次都从内存中读取数据。因此,缓存命中率越高,代码的性能越好。
但是应该注意的是,当CPU访问数据时,如果CPU高速缓存不缓存数据,它将从内存中读取数据,但它不仅是一条数据,而且是一条数据一次存储。在CPU缓存中,稍后将由CPU读取。
有许多策略可以将内存地址映射到CPU缓存地址。更简单的是直接映射Cache。它巧妙地将内存地址分割为“索引+组标记+偏移量”,以便我们可以将较大的内存地址映射为较小的CPU缓存地址。
如果要编写使CPU更快运行的代码,则需要编写具有较高缓存命中率的代码。 CPU L1缓存分为数据缓存和指令缓存,因此您需要分别提高它们的缓存命中率:
此外,对于多核CPU系统,线程可能会在不同的CPU内核之间来回切换,因此每个内核的缓存命中率都会受到影响,因此如果要增加处理器的缓存命中率,进程中,您可以考虑将线程绑定到某个CPU。一个CPU内核。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-344512-1.html
 Java内存模型(JMM)与JVM内存区域划分的区别
Java内存模型(JMM)与JVM内存区域划分的区别 主板上的纽扣电池没有电,系统时间就会恢复
主板上的纽扣电池没有电,系统时间就会恢复 Luca玩家超频记录改写华擎主板超频低调印象(组图)
Luca玩家超频记录改写华擎主板超频低调印象(组图) 内存被识别成4GB最后重新启动系统,一切搞定!
内存被识别成4GB最后重新启动系统,一切搞定!- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
半途猎杀之