操作方法:常用的JVM性能调整监视工具,功能太强大
电脑杂谈 发布时间:2020-09-02 23:02:23 来源:网络整理
在实际的企业级Java应用程序开发和维护中,有时会遇到以下问题:
OutOfMemoryError,内存不足
内存泄漏
线程死锁
锁定争用(锁定争用)
Java进程消耗太多CPU
......
在日常开发和维护中,许可能会忽略这些问题(例如,有些人仅在重新启动服务器或增加内存时才遇到上述问题,而没有探究问题的根本原因),但是他们可以了解并解决这些问题对高级Java程序员的基本要求. 本文将介绍一些常用的JVM性能调优和监视工具,希望会有用.
此外,无论您是进行操作,开发还是测试,都必须掌握这些监视和调整工具的使用.
A,jps(Java虚拟机进程状态工具)
jps主要用于输出在JVM中运行的进程状态信息. 语法格式如下:
如果未指定hostid,它将默认为当前主机或服务器.
命令行参数选项描述如下:

例如:

B,jstack

jstack主要用于查看Java进程中的线程堆栈信息. 语法格式如下:

命令行参数选项描述如下:

jstack可以找到线程堆栈,并且我们可以根据堆栈信息找到特定的代码,因此它在JVM性能调整中被大量使用. 让我们以一个示例为例,在某个Java进程中查找最消耗CPU的Java线程并找到堆栈信息. 使用的命令是ps,top,printf,jstack和grep.
第一步是找出Java进程ID. 我在服务器上部署的Java应用程序的名称为mrf-center:

获取进程ID 21711,第二步是查找进程中最消耗CPU的线程,可以使用ps -Lfp pid或ps -mp pid -o THREAD,tid,time或top -Hp pid,我在这里使用它的第三个,输出如下:
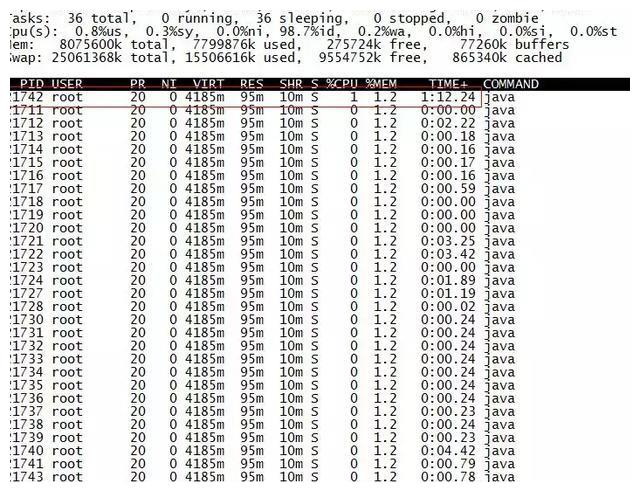
TIME列是每个Java线程消耗的CPU时间. CPU时间最长的是线程ID为21742的线程. 使用

21742的十六进制值为54ee,将在下面使用.
好的,下一步终于到了jstack了. 用于输出进程21711的堆栈信息,然后根据线程ID的十六进制值输出grep,如下所示:

您可以看到CPU消耗在PollIntervalRetrySchedulerThread类的Object.wait()中. 我找到了我的代码并找到了以下代码:

它是轮询任务的空闲等待代码. 上面的si.wait(timeUntilContinue)对应于先前的Object.wait().

C,jmap(内存映射)和jhat(Java堆分析工具)
jmap用于查看堆内存使用情况,通常与jhat结合使用.
jmap语法的格式如下:

如果您在64位JVM上运行,则可能需要指定-J-d64命令选项参数.

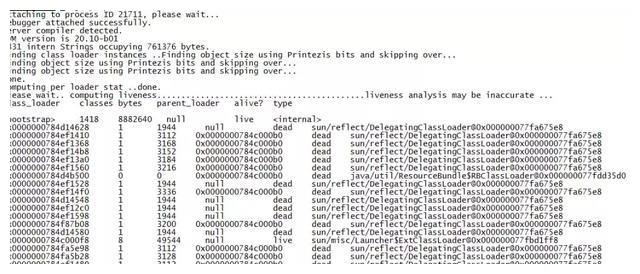
打印进程的类加载器以及由类加载器加载的持久性生成对象信息,输出: 类加载器的名称,对象是否存在(不可靠),对象地址,父类加载器,所加载类的大小等,如下所示:
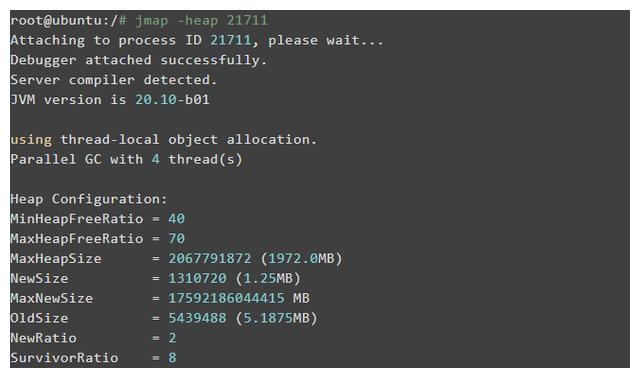
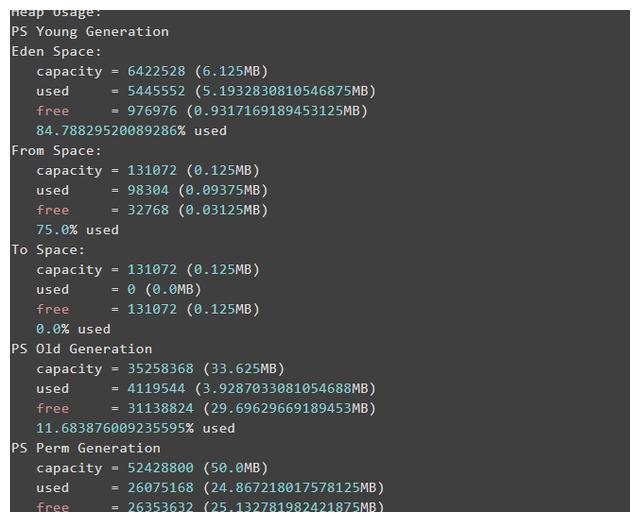
使用jmap -heap pid查看进程的堆内存使用情况,包括所使用的GC算法,堆配置参数以及每一代中的堆内存使用情况. 例如,以下示例:
使用jmap -histo [: live] pid查看堆内存中对象的数量和大小的直方图. 如果带电,则仅对带电物体进行计数,如下所示:
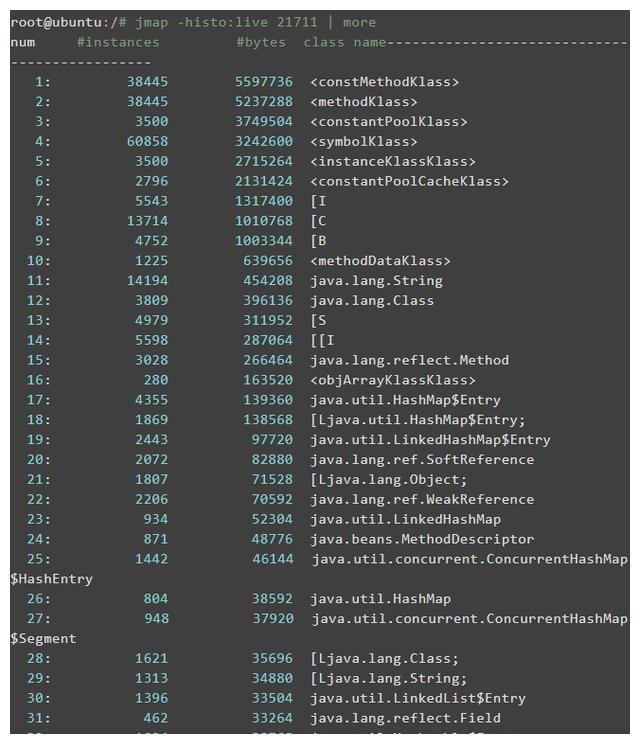
类名是对象类型,描述如下:

还有一种非常普遍的情况: 使用jmap将进程的内存使用量转储到文件中,然后使用jhat进行分析和查看. jmap dump命令的格式如下:

我对上述进程ID 21711进行了相同的转储:

可以使用MAT,VisualVM和其他工具查看转储的文件,这里使用jhat进行查看:
请注意,如果转储文件太大,则可能需要添加参数-J-Xmx512m以指定最大堆内存,即jhat -J-Xmx512m -port 9998 /tmp/dump.dat. 然后,您可以在浏览器中输入主机地址: 9998来查看:
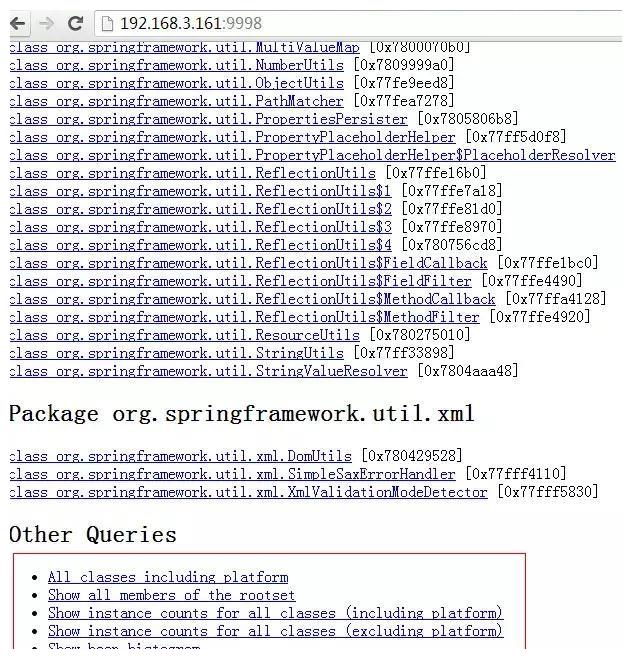
您可以在上面的红色框中浏览零件. 最后一项支持OQL(对象查询语言).
D,jstat(JVM统计监视工具)
语法格式如下:

vmid是Java虚拟机ID,通常是Linux / Unix系统上的进程ID. interval是采样间隔. 计数是样本数. 例如,下面的输出是GC信息,采样间隔为250ms,采样数为4:
root @ ubuntu: /#jstat -gc 21711 250 4 S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT 192.0 192.0 64.0 0.0 6144.0 1854.9 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649192.0 192.0 64.0 0.0 6144.0 1972.2 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649192.0 192.0 64.0 0.0 6144.0 2109.7 32000.0 4111.6 55296.0 25472.7 702 0.431 3 0.218 0.649
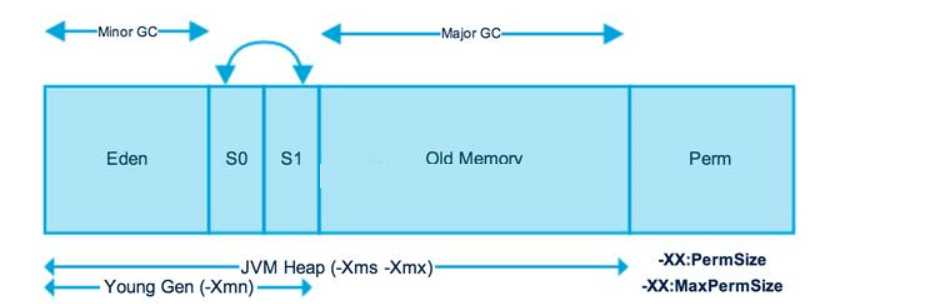
要了解以上各列的含义,请首先查看JVM堆内存布局:
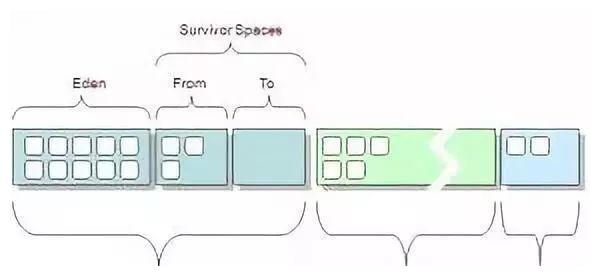
可以看到:

现在让我们解释每一列的含义:


E,hprof(堆/ CPU分析工具)
hprof可以显示CPU使用率并计算堆内存使用率.
语法格式如下:

完整的命令选项如下:
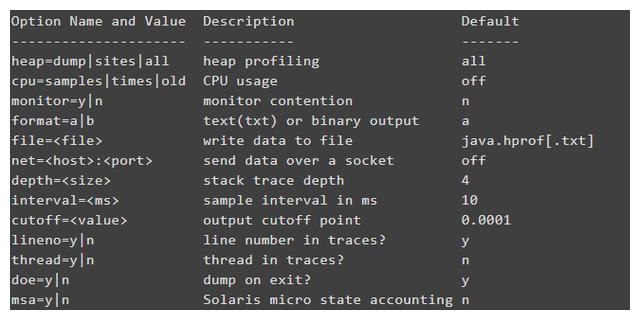
官方指南中的一些示例.
CPU使用率采样分析示例(cpu = samples):

上面的示例每20毫秒对CPU消耗信息进行一次采样,堆栈深度为3,生成的配置文件名称为java.hprof.txt,位于当前目录中.
以CPU使用情况时间概要分析(cpu = times)为例,与CPU使用情况采样概要文件相比,它可以获得更多细粒度的CPU消耗信息,详细信息可参见每个方法调用的开始和结束. 它的实现使用词段代码注入技术(BCI):

堆分配分析(heap = sites)示例:

堆转储(heap = dump)示例,它可以生成比上面的堆分配概要分析更详细的堆转储信息:

尽管-Xrunprof: heap = sites参数可以添加到JVM启动参数中以生成CPU /堆配置文件,但是它对JVM的性能有很大影响,因此不建议在JVM中使用它. 服务器环境.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-312635-1.html
-

-
池泽春菜
错
 计算机主板制造商列表
计算机主板制造商列表 即将发布:问题2:魅族一体机如何看待手机型号?
即将发布:问题2:魅族一体机如何看待手机型号? 联想690主板BIOS设置方法
联想690主板BIOS设置方法- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
高速成长的时代已经永远结束