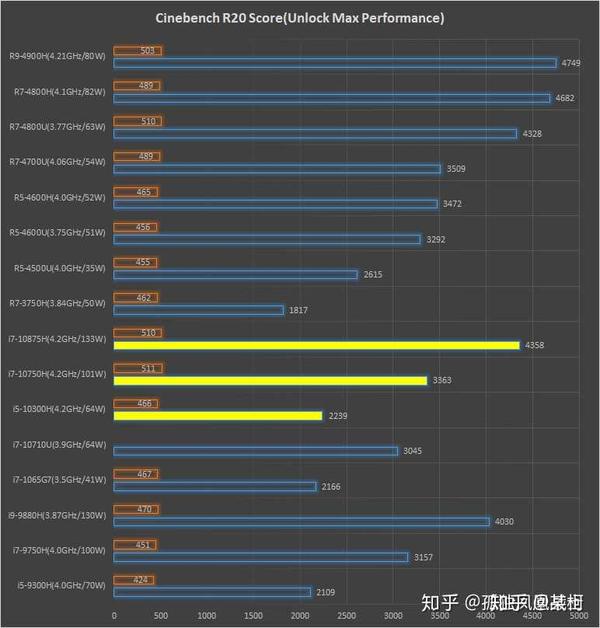
基于排队论的单核处理器和多核处理器性能的简单定量评估
电脑杂谈 发布时间:2020-06-29 21:24:06 来源:网络整理
摘要: 自cpu诞生以来,主要频率一直在不断提高. 然而,随着主频率的增加,电压和热量的产生已经成为单核CPU的主要障碍,这使得CPU无法通过简单地增加主频率来提高处理器的性能. 因此,增加CPU内核数已成为最实际的方法. 如何评估增加的CPU内核数量和性能提高水平是设计CPU时应考虑的主要问题之一. 本文使用排队论的方法来提供简单的定量分析. 根据排队理论的相关模型,我们可以对核的数量和性能改进进行简单的评估. 为多核CPU的设计提供定量依据. 关键词: 多核CPU;单核CPU; CPU性能排队论定量评估概述: 自CPU诞生以来,主频一直在不断提高,如今主频之路已到达拐点. 台式机处理器的主频率在2000年达到1GHz,在2001年达到2GHz,在2002年达到3GHz. 但是在将近5年之后,我们仍然没有看到4GHz处理器的出现. 电压和热量的产生已成为最重要的障碍. 结果,在台式机处理器(尤其是笔记本电脑)中,英特尔和AMD不再能够通过简单地增加时钟频率来设计下一代新型CPU. 面对主频的结束,英特尔和AMD开始寻找其他方法来维持或提高处理器的能效,同时提高其性能. 最实用的方法是增加CPU中的处理核心数.
多核是指在一个处理器中集成两个或多个完整的计算引擎(核). 多核技术的发展源于工程师们的认识,即增加单核芯片的速度将产生过多的热量,并且不会像以前的处理器产品那样带来相应的性能改进. 他们意识到,在以前的产品中,处理器所产生的热量将以这种速度迅速超过太阳表面. 即使没有散热问题,性价比也不可接受,而且速度更快的处理器也要昂贵得多. 英特尔工程师已经开发了多核芯片,以满足“水平扩展”(而非“垂直扩展”)方法来提高性能. 该框架实现了“分而治之”的战略. 通过划分任务,线程化的应用程序可以充分利用多个执行核心,并且可以在特定时间内执行更多任务. 多核处理器是单个芯片(也可以称为“硅核”,可以直接插入单个处理器插槽中,但是操作系统将使用所有相关资源将其每个执行内核视为离散逻辑处理器. 通过将任务划分为两个执行内核,多核处理器可以在特定的时钟周期内执行更多任务,该多核体系结构可以使当前软件更好地运行,并创建可以促进未来软件编写的体系结构. 仍在探索新的软件并发处理模式,随着向多核处理器的迁移,现有软件可以支持多核平台而无需进行修改.

该操作系统旨在充分利用多个处理器的优势,并且无需修改即可运行. 为了充分利用多核技术,应用程序开发人员需要在程序设计中纳入更多思想,但是设计过程与当前的对称多处理(SMP)[1]系统设计过程相同. ,现有的单线程应用程序也将继续运行. 多核技术是处理器的必然发展. 在过去的20年中,有两个主要因素推动着微处理器性能的不断提高: 半导体工艺技术的飞速发展和体系结构的不断发展. 半导体工艺技术的每一项进步都提出了新的问题,并为微处理器体系结构的研究开辟了新领域. 随着半导体工艺技术的发展,体系结构的进步进一步提高了微处理器的性能. 这两个因素相互影响,相互促进. 一般而言,工艺和电路技术的发展使处理器的性能提高了约20倍,体系结构的发展使处理器的性能提高了约4倍,编译技术的发展使性能得到了提高. 大约是处理器的1.4倍. 但是今天,这种规律性很难维持. 多核的出现是技术发展和应用需求的必然产物. 基于上述知识,在设计多核处理器时,如何更好地评估内核数量的增加以及相应的理论性能改进也是不可避免的. 本文采用排队论模型对单核处理器和多核处理器处理同一任务所花费的时间进行定量分析.
2. 单核处理器和多核处理器的体系结构a)单核处理器的结构和处理机制ͼ1单核CPU的结构如图1所示. 自诞生以来,CPU一直在不断提高其主频. 对于单核处理器,提高主频是提高性能的最简单方法. 主频率是CPU的时钟频率,仅是CPU工作时的工作频率(在1秒钟内生成的同步脉冲数)的缩写. 单位是Hz. 它决定了计算机的速度. 与多核相比,单核架构相对简单. 在处理机制中,处理核心仅需要完成L2缓存请求. 这一直循环到任务完成为止. 从操作系统的角度来看,单核处理器以串行方式(基本上是并行)完成并行工作. b)多核处理器的结构和处理机制. 对于多核处理器,该体系结构分为CMP(片上多核处理器,芯片,多处理器)和SMP(同时多线程处理器,同时多处理器). 从体系结构的角度来看,SMP比CMP具有更高的处理器资源利用率. 但是,从使用效果的角度来看,CMP在多线程中具有较低的通信延迟,并且其最大的优势体现在模块化设计的简单性上,并且没有因SMP中共享资源争用多个线程而引起的延迟. 问题.
因此,本文中的分析基于CMP体系结构. 如图所示: (也参考该论文)随着半导体技术的发展,CPU与主存储器之间的速度差距越来越大. 在CMP中,多个处理器内核共享单个内存空间使这一矛盾更加突出,因此在设计中使用了多级Cache来缓解这种矛盾. 此外,Cache本身的体系结构设计还直接关系到整个系统的性能. 许多CMP设计都采用了分布式第一级缓存,共享的第二级缓存和第三级缓存的结构. CMP通常可以分为同构CMP和异构CMP,其判据基于此. 芯片上集成的多个微处理器内核是否相同?大多数同类CMP由通用处理器组成,其中多个处理器执行相同或相似的任务. 异构CMP包含通用处理器作为控制,通用计算,多集成DSP,ASIC,媒体处理器,VLIW处理器和其他特定应用程序,以提高计算性能. 基于X86技术的多核处理器使用类似的技术,而AMD Opteron处理器的设计更接近于传统的RISC处理器设计. 英特尔产品是从单插槽处理器开发的,与多插槽产品中的上述结构有很大不同,但设计中还引用了许多类似的技术. 在本文中,我们使用同构CMP进行分析.
从操作系统的角度来看,系统中的所有作业都将移交给辅助共享缓存,之后,这些作业将在处理器中进一步分配. 分配给不同的处理核心以进行并行处理,该处理实际上是并行的. 但是,并行线程不是这种情况. 因为同一线程还可以划分为不同的时间片,并同时在不同的处理核心上进行处理. 这样单核性能和多核性能,您可以在外部(处理器外部)按照原始(单核)调度方法将系统中的任务传递给处理器. 这在一定程度上保持了兼容性. 但是,这不是有效利用多核处理器的最佳方法. 这里没有讨论. 3.排队理论概述排队理论起源于20世纪初期的电话交谈. 从1909年到1920年,丹麦数学家和电气工程师A. K. Erlang使用概率论方法研究电话交谈问题,从而创建了该应用数学学科,并建立了该学科的许多基本原理. 在1930年代中期单核性能和多核性能,W. Feller提出了出生和死亡过程时,排队理论被数学认为是一门重要的学科. 排队系统也称为服务系统. 服务系统由服务组织和服务对象(客户)组成. 服务对象到达的时间和服务对象的时间(即占用服务系统的时间)是随机的. 图1显示了最简单的排队系统模型. 排队系统包括三个部分: 输入过程,排队规则和服务组织.
输入过程: 输入过程检查客户进入服务系统的规则. 可以用一定时间段内客户到达的数量或两个客户连续到达之间的间隔来描述. 它通常分为两种: 确定性和随机性. 排队规则: 排队规则分为等待系统,损失系统和混合系统. 当客户到达时,所有服务机构都被占用,然后客户排队等待,这就是等待系统. 在等待系统中,客户的服务顺序可以是先到先服务,后到先服务或随机服务和优先服务(例如,接收急诊患者的医院). 如果客户到达并且发现服务组织没有空闲时间离开,那就是损失系统. 某些系统的空间有限,客户无法排队等候,因此超出容量的客户必须离开系统. 该排队规则是混合系统. 服务机构: 可以是一个或多个服务台. 多个服务台可以并联或串联排列. 服务时间通常分为两种: 确定性和随机性. 排队模型中的主要性能参数: 1)客户到达率λ: 每单位时间的客户到达数量2)平均服务率μ: 每单位时间可服务的客户数量,1-μ表示平均服务时间3)服务强度ρ: ρ=λ/μ代表服务组织的数量,是服务效率和服务组织利用率的重要标志. 4)平均客户等待时间W: W =ρ/(μ-λ)4.使用排队论模型分析处理器的性能a)单核处理器的性能分析本文假设多个我们正在评估的系统中独立的处理请求是平衡的,即输入速率等于离开速率.
根据Littles律[2],我们可以获得: 平均服务(N服务器)中的任务数=到达率(λ)*每个任务(T服务器)的平均服务时间. 服务器利用率=平均服务/服务速率中的任务数. 对于单个服务器,服务速率为1 / T服务器. 这样我们就可以得到: 服务器利用率=到达率* T服务器,因此队列中每个任务的平均等待时间(T队列)=服务器利用率* T服务器+(到达率* T队列)* T -服务器. 简化后,我们可以得到: T-queue = T-server *(服务器利用率/(1-服务器利用率))对于单核处理器,我们假设其平均服务时间为T-server = 1 /主频率. 这只是一个简单的假设,在实践中有许多情况需要考虑. 现在考虑一个主频率为2的单核处理器. 3GHZ,假设客户的平均到达率为50,则根据M / M / 1模型,可以获得服务器利用率和平均队列等待时间. : T-server = 1 /(2.3 *)根据上面的推导,可以获得服务器的利用率: 服务器的利用率=到达率* T-server = 50 * 1 /(2.3 * 1024)= 0. 02122最后,可以计算出每个任务在队列中的平均等待时间: T队列= T服务器*(服务器利用率/(1-服务器利用率))= 50 *(0.

02122 /(1-0.02122))=1. 0840025337665 b)多核处理器的性能分析在这里,我们使用AMD三核处理器进行测试. 如图所示的三核处理器的体系结构. 处理机制满足排队模型的三个基本组成部分: 输入过程是系统对CPU资源的请求;输入过程是系统对CPU资源的请求. 排队规则是处理器的处理机制,这里我们简化为一般的先进先出排队规则,并且不考虑L2缓存用于任务分配的延迟;服务组织具有三个处理核心. 该系统模型在排队论中成为M / M / C模型. 如图所示: 请参见本书第270页. M / M / C队列的公式如下所示,其中N-server代表服务器数量. 然后很容易从前面的两个公式中得出: 利用率=到达率* T服务器/ N服务器T队列= T服务器*(P-moretask /(1-利用率))此公式和M该公式/ M / 1中的命令类似,除了使用任务在队列中等待的概率而不是服务器的利用率,然后处理服务器的数量. 在具有多个服务器的系统中,计算任务在队列中等待的可能性很复杂. 我们必须首先计算系统中无任务的概率: 请参阅第271页. 系统中任务数与服务器数相同或更多时的概率P-moretask =(N-server * utilization * utilization / N-server!*(1-utilization))* P-notask是基于以上问题的,然后我们通过双核处理器进行操作,这里我们使用双核处理器的主频为2.
3 GHZ由于使用双核,因此不考虑处理核任务的时间. T服务器= 1/2. 3GHZ * 2解决以上问题: 服务器利用率=到达率* T-server / N-server = 50 * 0.00008491 / 2 = 0.02122队列中无任务的概率: P-notask = 0.9397使用此结果计算以下概率: 队列中有任务: P-moretask = 0.0004322最后计算队列中的等待时间: T-queue = T-server *(P-moretask / N -server *(1-utilization))=1. 8746859355524224034001512086475e-8 1. 840853102842313900978769488547547-6 5.比较结果可以清楚地看到单核和多核性能的比较. 在忽略其他因素的情况下,对于具有相同性能的单核和双核处理器主要频率,他们正在处理相同数量的任务. 此时,单核任务的平均等待时间是双核任务的平均等待时间的100倍. 可以很容易地推断出,对于每个附加内核,任务的处理速度将提高100倍. 6.总结这项研究的意义: 用一个简单的排队模型来分析多核处理器的改进是有帮助的,这样可以在技术投资和获得高效率速度之间找到一个稳定点. 这样多核的发展就可以更加科学和可预测. 参考: [1]: 对称多处理器SMP: [2]利特尔定律指出: “系统中的平均对象数等于平均对象离开系统的速率与每个对象在系统中停留的平均时间的乘积. ”胡扬,焦庆禄撰写并整合,转载并标记作者!! !
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shouji/article-262794-1.html
-

-
豆彦贵
敢到朝鲜打击美国佬
-
姜瑾斐
包括岛礁上的军事设施建设
-
-
同治
我们可以打一场快速的局部战争
 三星s8待机功耗严重三星s8待机功耗快速
三星s8待机功耗严重三星s8待机功耗快速 苹果7手机回收价格表赣州哪里会回收闲置的二手手机_赣州苹果手
苹果7手机回收价格表赣州哪里会回收闲置的二手手机_赣州苹果手 史上危害最大的病毒你又知道几个?
史上危害最大的病毒你又知道几个? 手机想防摔就一定要贴钢化膜吗?有必要吗?答案说出来你或许不信
手机想防摔就一定要贴钢化膜吗?有必要吗?答案说出来你或许不信
强烈建议大家更新后抹除所有数据