深度学习图形卡参数的详细比较
电脑杂谈 发布时间:2020-12-21 22:01:23 来源:网络整理在这里,我们列出了近年来适用于深度学习的Nvidia各种图形卡的详细参数,并作了一些解释,以便每个人都可以根据自己的需要选择自己的图形卡。直接在图片上(编辑者组织了很长时间)。
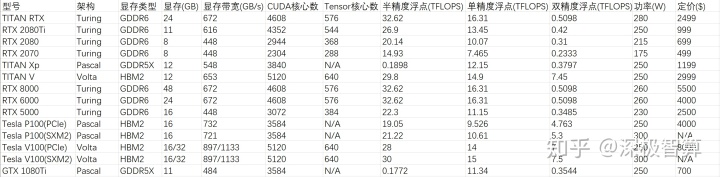
如何看这张图,主要看几个关键性能指标。
1.单精度浮点计算速度
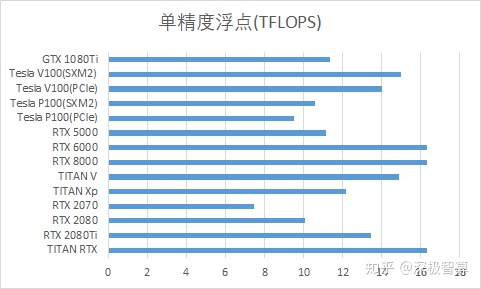
单精度浮点数,在tensorflow中也称为FP32,tf.float32,是我们最常用的数据精度和每个深度学习框架的默认数据精度。可以看出,在该性能指标中,各种图形卡之间的差距不是很大。总体性价比,我们推荐2080Ti,2080和1080Ti。
2.视频内存大小
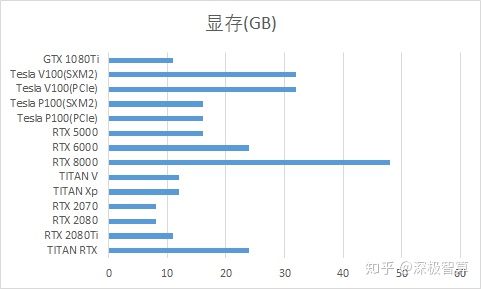
视频内存是图形卡内存,它确定我们可以读取多少图形数据以进行计算(批处理大小)以及可以构建的模型大小(网络层数,单位数),即对深度学习研究人员而言非常重要根据这些指标,您可以看到RTX 8000具有48GB的最大视频内存,而Tesla V100 32GB版本具有32GB的视频内存。但是,这些卡的价格太贵了。在这里,我推荐2080Ti和1080Ti。如果您确实需要大量视频内存,那么更实惠的解决方案是购买两个TITAN RTX,并使用Nvlink形成双卡来共享视频内存,并享受48GB和两张卡的计算能力。


3.半精度浮点数计算速度
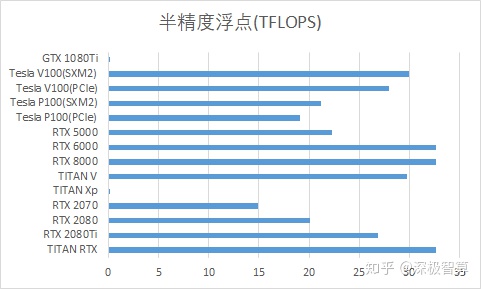
如果运算的精度不高,则可以尝试使用半精度浮点数进行运算。此时,Tensor核心将派上用场。 Tensor Core专门从事矩阵数学运算,适用于深度学习和某些类型的HPC。 Tensor Core执行融合乘法和加法,其中将两个4 * 4 FP16矩阵相乘,然后将结果添加到4 * 4 FP16或FP32矩阵中,最后输出一个新的4 * 4 FP16或FP32矩阵。 NVIDIA称这种由Tensor Core混合精度数学执行的运算,因为输入矩阵的精度为半精度,但乘积可以达到全精度。 Tensor Core进行的这种操作在深度学习训练和推理中非常普遍。因此,购买具有Tensor Core的显卡以迎接未来。 Nvidia声称,使用Tensor Core进行矩阵运算可以轻松达到2-5倍的训练速度,同时将内存访问和存储量减少一半。它不仅可以提高计算速度,而且可以将视频内存使用量减少一半。 Tensor Core是一件好事。这里推荐使用RTX系列,例如2080Ti。应该注意的是,具有上一代Pascal架构的图形卡(例如1080Ti和TITAN Xp)没有诸如Tensor Core之类的特殊计算单元,因此半精度浮点数的性能非常差。
有关混合精确训练的好处,请参阅此处
Dreaming.O:谈论混合精度训练

4.双精度浮点计算速度
适用于需要非常高精度的人员,例如医学图像,CAD。但是,高性能双精度浮点数是非常昂贵的模型。如果您在购买时没有特殊需求,则不建议参考此指标。
5.不同类型神经网络的索引参考顺序
对于不同类型的神经网络,主要参考指标是不同的。这是指标顺序的参考:
卷积网络和变压器:张量核心数>单精度浮点性能>视频存储带宽>半精度浮点性能
递归神经网络:内存带宽>半精度浮点性能>张量核数>单精度浮点性能
可以看出,主流显卡的内存带宽差不多,至少400GB / s的速度根本不是正常使用的瓶颈。至于Tensor内核的数量,只要不是上一代Pascal架构,主流显卡张量内核的数量就完全足够了。我们认为对于进行深度学习的学生,主要参考指标应该是单精度浮点性能和视频内存大小,而次要参考指标应该是半精度浮点性能(张量核心数)。
*********************************************** ***********************************************
总而言之,不同的显卡适合不同的人。黄仍然很机灵。大容量视频存储器和双精度计算性能等更的产品越贵。但是对于我们来说,我们可以使用老黄的游戏卡进行深度学习。这里强烈推荐2080Ti。适中的价格,出色的性能以及对混合精度培训的支持确实非常好。
最后,对于所有人来说,配置您自己的GPU服务器太昂贵了,一个RTX为20,000元,而2080Ti为10,000,这是禁止的。对于新手来说,拥有可以随时练习的GPU服务器仍然非常重要。我建议使用深机智能云计算平台(),该平台可以使用功能强大的GPU服务器,且投资少。 1080Ti每张卡不到1元。 2080Ti每卡小时不到2元,因此每个人都可以运行更深的模型!
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shenmilingyu/article-342175-1.html
-

-
石超宇
如果没有蛆
-
房玄龄
 HP V3000 DV2000笔记本电脑图形门维修的全面解决方案
HP V3000 DV2000笔记本电脑图形门维修的全面解决方案 GPU和图形卡之间有什么关系?
GPU和图形卡之间有什么关系? 图形卡cpu-z CPU
图形卡cpu-z CPU 2000w 开房信息下载?2000w使用方法?2000w数据查?2000w开房数据下载信息裸奔 开房网网址查询
2000w 开房信息下载?2000w使用方法?2000w数据查?2000w开房数据下载信息裸奔 开房网网址查询
而且又是密封包装