图形带宽计算,深度学习中GPU卡的选择
电脑杂谈 发布时间:2020-09-04 00:11:13 来源:网络整理
写在前面
本文针对的读者:尝试使用深度学习技术的GPU加速卡(图形卡)新手/公司购买者/实验室研究人员
构建GPU服务器的预算:每张卡8k或更多
写作动机:1.实验室正在(再次)购买一批GPU服务器
2. Zhihu似乎没有找到Turing或Volta GPU信息,并且大多数比较还是在1080ti / titan XP上进行。
注:比较中涉及的GPU卡均为N卡(NVIDIA / NVIDIA)。在深度学习领域,A卡还不及N卡,而且平台资源还不够丰富。
再次注意:本文中的比较模型是:RTX 2080ti / P40 / P100 / V100。如果您对其他GTX系列产品(例如1080ti / titan XP等)感兴趣,可以转到[门户☞深度学习的方法一些选择合适的GPU卡进行共享的经验和建议]
*转载需征得作者的同意。基础知识
什么是GPU加速卡(图形卡)?

[门户☞图形卡_百度百科]
[门户☞多比七:最重要的图形卡性能指标是什么?如何选择图形卡? )
为什么在深度学习中需要GPU加速卡?
[门户☞团爸爸:图形卡和深度学习之间有什么联系? )
[门户☞实用指南:如何为您的深度学习任务选择最合适的GPU?]
为什么本文只写N卡?如果我想使用A卡怎么办?
[门户☞Rebel:为什么GPU计算,AMD显卡很少用于深度学习,基本上是nvidia? )
[门户☞BlueWanderer:深度学习平台的显卡选择? )
我没有那么多预算,但是我想运行代码并自己玩。我该怎么办?

[门户☞租用两台具有双电源的1080TI计算机:穷人也需要深入学习](自己动手建造)
[门户☞GPU云服务器深度学习性能模型](阿里云)
[门户☞逐步教您在Amazon云服务器AWS上训练深度学习模型](Amazon)
输入主题
首先将当前(201 8. 1 2)个消费者级别(游戏级别)图形卡最新产品RTX 2080ti作为基准粘贴。
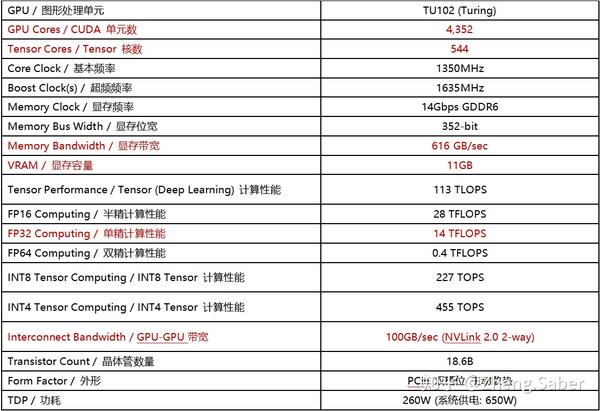
(您知道您不能写一张桌子吗?我不知道,或者我根本不支持它,我请大个子们进行教育)
我用红色标记了需要注意的参数。我将主要讨论这些参数在深度学习中的重要性,以便将来与项目需求相比可以添加和删除这些参数。
GPU体系结构:GPU体系结构是指硬件的设计方式,例如流处理器集群中有多少个内核,是否有L1或L2缓存,是否有双精度计算单元等等。每一代的架构都是一种思想,如何更好地完成并行思想,而芯片就是上述思想的实现。目前,N家的主流架构包括Turing,Pascal,Kepler,Volta等。通常,GPU加速卡以GPU架构模型的首字母命名,例如:P100是Pascal架构。当然,还有一种类似于2080ti的命名方法,这是一种图灵架构(我认为目的是区分特斯拉,我不知道它是否正确)。 CUDA单元数:CUDA(计算统一设备体系结构)是NVIDIA发布的通用并行计算体系结构,它使GPU能够解决复杂的计算问题。基本上,在进行深度学习时,没有人不知道CUDA的名称。此单位数直接影响GPU的计算性能。 Tensor核心数:我们知道在高维矩阵(张量Tensor)之间执行了大量的深度学习操作。 Tensor Core可以使张量的计算速度迅速提高。 Tensor Core专用于执行矩阵数学运算,并且适合于深度学习和某些类型的HPC。

Tensor Core执行融合乘法和加法,其中将两个4 * 4 FP16矩阵相乘,然后将结果加到4 * 4 FP16或FP32矩阵中,最后得到一个新的4 * 4 FP16或FP32矩阵。输出。 NVIDIA称这种由Tensor Core混合精度数学执行的运算,因为输入矩阵的精度为半精度,但乘积可以达到全精度。碰巧的是,由Tensor Core完成的这种操作在深度学习训练和推理中非常普遍。 Tensor Core在GPU中处理矩阵运算,而不是简单的单指令流多数据流标量运算。尽管在执行标量运算时性能较差,但可以将更多运算打包到同一芯片区域中。显存带宽:显存带宽是指显示芯片与显存之间的数据传输速率。根据我的观察,如果我们正在对图像进行深度学习研究,则具有更大内存带宽的GPU允许您设置更大的batch_size,这意味着您可以取出更多数据以同时进行训练。显存容量:显存容量是图形卡上的显存容量。视频存储容量决定了临时存储的视频存储量。作为图像研究的示例,更大的视频存储容量使您可以一次将更多的训练图像读取到内存中,甚至可以将整个数据集直接存储到变量中,这就像编写Queue或tfrecord这样的堆栈要酷得多缓慢读取数据,至少可以解决随机播放不足的问题〜双精度/单精度/半精度计算性能:这当然是最重要的,该指标表明GPU正在处理FP64 / FP32 / FP16浮点具有不同精度的浮点数的计算能力。对于浮点计算,CPU可以同时支持不同精度的浮点运算,但是在GPU中,单精度和双精度需要单独的计算单元。因此,这取决于项目是否需要进行双精度计算的级别。一般来说,深度学习计算的精度要求非常低。在小数点对最终结果的影响更大之后,没有权重矩阵的变化超过十位数。是的,否则您必须考虑它是否是病理性的。
差不多了,我稍后会在测试中考虑时添加它〜
要弄清楚这些参数,让我们看一下V100 / P100 / P40的比较表:
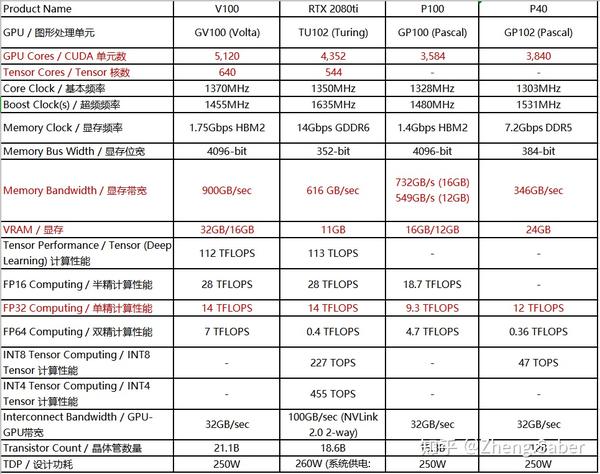
一目了然吗?最后,让我们简要地总结一下:
在训练时间短且需要快速完成训练的情况下,即在很大程度上考虑GPU低精度计算速度的情况下:
V100> 2080ti> P100> = P40(P40不支持半精度计算,但单精度优于P100,P40带宽低但内存高)
2.并不急于训练结果,但是数据集特别大,例如图像和视频流处理项目:
V100> P40> P100> 2080ti(需要较高的视频内存和带宽)
3.当数据集是NLP或时间序列数据并且预算不足时,即数据量不大:
2080ti> P40> P100> V100(V100有点贵)
4.我不仅想将其用于深度学习,还希望将其用作数据中心:
V100(数据中心的并行计算和同时运行GPU和CPU服务器的深度学习大型模型计算示例)
P100(数据中心同时运行GPU和CPU服务器并进行一般规模的深度学习)
P40(简化数据中心级模型训练和超科学计算的推理)
2080ti(大型深度学习计算和大型游戏?)
写在最后
我还是硬件的白人,经过最近的不幸之潮,我已经在这里记录了它。每个人的交流也很方便。如果有任何错误或不满意的话,请纠正我。谢谢〜
最后宣传我之前写的有关深度学习的文章:
1.【深度学习的系统回顾】
2. [LSTM中对M(内存)的重新思考]
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shenmilingyu/article-313325-1.html
-

-
辛迪克劳馥
怎么下载啊
-
-
刘丽丽
期待演员杨洋给我们展现他的潜力和作品
-
安保伟
怎么回应国内的喷子呢
![如何拆卸联想y480?如何拆卸联想y480 [图形步骤]](http://www.pc-fly.com/uploads/allimg/20210110/1610230704163_lit.png) 如何拆卸联想y480?如何拆卸联想y480 [图形步骤]
如何拆卸联想y480?如何拆卸联想y480 [图形步骤] 200元的GTX750Ti二手显卡与1050Ti相比值得购买吗?老玩家告诉你答案
200元的GTX750Ti二手显卡与1050Ti相比值得购买吗?老玩家告诉你答案 面向对象设计原则之里氏代换原则
面向对象设计原则之里氏代换原则![直观:模糊计算机监视器[图形]的原因和解决方案](http://pic3.zhimg.com/80/v2-63437b3330a89effd2b702b66c5e98c2_720w.jpg) 直观:模糊计算机监视器[图形]的原因和解决方案
直观:模糊计算机监视器[图形]的原因和解决方案
不就是个死吗