简化特斯拉K10和K20的复杂性并详细介绍其技术规格
电脑杂谈 发布时间:2020-08-20 21:02:58 来源:网络整理
在GTC 2012大会上,NVIDIA首席执行官黄仁勋宣布了新一代Tesla卡的详细信息,但是这次发布的Tesla显卡是双胞胎,其中一个是基于双核GK104架构Tesla K10,并且其他则使用真正的新架构,基于GK110内核的Tesla K20.

K10和K20的特性不同,关键点也不同.
让我们首先看一下K10. 它的物理外观与GTX 690显卡相同. 但是,NVIDIA宣布了几个有趣的参数. 单精度浮点功能为4.58TFLOPS,带宽为320GB / s. 相比之下,GTX 680单核的精确计算能力为3.09TFLOPS,带宽为192GB / s,而GTX 690也具有5.62TFLOPS,带宽为384GB / s,上一代Fermi核心浮点计算能力为1.58TFLOPS,带宽为192GB /

从参数的角度来看,K10达到了NVIDIA声称的Fermi系列单精度浮点功能的三倍,但仅比GTX 680高50%,带宽仅约67高出%,这显然不及GTX. 690图形卡.
由于采用相同的架构,Tesla K10显然损害了内核和内存频率. 由于GK104架构具有很高的能效比,因此HPC领域对功耗和热量产生不是很敏感. 我不知道为什么NVIDIA采用K10. 规格设置为低于GTX 690.
现场图片并未公布K10的视频存储容量和TDP信息,但GeForce GRID页面上的K520显卡规格与K10一致,视频存储容量为8GB,TDP为250W,两者均实际上是双核GK104显卡,所以Tesla K10也是8GB显存,250W TDP. (此功耗低于GTX 690的300W,这也许是降低规格的唯一可能的解释)
Tesla K10现在可以发货,但这不是重点. 我个人认为,它只是扮演消防员角色的过渡产品,因为GK104本质上较弱的双精度计算功能注定会在HPC市场上出现. 成绩斐然,NVIDIA之所以将GTX 690投入战斗,是因为GK110架构的推出晚于预期.

GK110是NVIDIA为高性能GPU计算市场开发的体系结构. 有传言称它将在今年8月发布,但NVIDIA给出的日期是今年的第四季度. 无论是28nm的生产能力还是芯片本身,这个长达半年的空白期总是需要有人先将其放在首位. 这是K10的任务.
Tesla K20和GK110架构
NVIDIA对K20的描述是“三倍双精度浮点性能”,并得到了各种并行计算技术(例如Hyper-Q和动态并行)的支持,而现有GK104架构中没有这些并行计算技术.


NVIDIA的PDF文档介绍了GK110的SMX架构,它也是192个CUDA内核
必须承认,先前泄漏的有关GK110体系结构的信息是错误的. GK110的SMX体系结构实际上与GK104相同,具有192个CUDA内核,32套SFU单元和32个LD / ST单元.
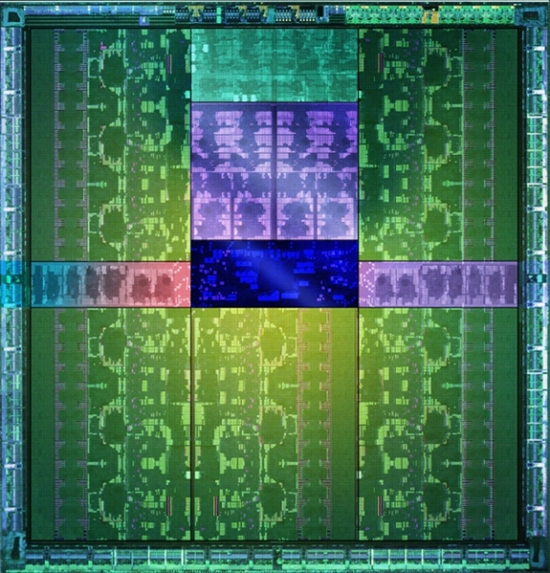
GK110体系

除其他功能单元外,GK110内核总共具有15套SMX单元和2880个CUDA内核,但是Heise声称并非所有单元都启用. 实际上,可能只有13-14套SMX单元. 实际的CUDA核心为2496或2688.
视频内存的位宽为384bit,这已由黄仁勋和NVIDIA CTO确认. 由于CUDA内核的数量比以前的报告要少,因此视频内存的位宽自然降至384bit. 如果保持GK104的6Gbps视频存储速率,那么GK110的带宽将达到288GB / s,最终将超过AMD GCN架构的260GB / s.
将NVIDIA提供的3倍双精度浮点性能与GF110显卡或具有GF110内核的Tesla加速卡进行了比较. GF110的单精度浮点功能为1.58TFLOPS,而显卡中的双精度为单精度. 其中的1/4为0.4TFLOPS,但是GF110核心Tesla卡的双精度功能可以达到单精度1/2,约为0.8TFLOPS.
这样,如果基于图形卡,GK110的双精度浮点性能约为1.2TFLOPS或更高,如果是特斯拉卡的3倍,则为2.4TFLOPS或更高. 如果后者已经超过了以前传闻的2TFLOPS功能,则GK110的双精度浮点功能应为1.2TFLOPS或更高.

Tesla K20配备6pin + 8pin电源接口
未知核心区域和TDP,但K20配备6针和8针电源端口,最大TDP不会超过300W. 晶体管的数量也有70亿,准确地说是71亿.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shenmilingyu/article-303242-1.html
-

-
杨玉珍
但是你能得到钱还是10万*1
-
张家源
想出名也不能介样吧
 华硕GPUTweak超频教程S档为省电模式保驾护航
华硕GPUTweak超频教程S档为省电模式保驾护航 官方数据:台式机显卡性能排名:显卡梯形图2019年8月至9月最新排名
官方数据:台式机显卡性能排名:显卡梯形图2019年8月至9月最新排名 流处理器和频率直接影响处理能力
流处理器和频率直接影响处理能力 如果图形卡不支持Directx11,该怎么办
如果图形卡不支持Directx11,该怎么办
门槛在门里的不都这样么