像Quadro这样的图形显卡真的比GTX这样的通用图形显卡有用吗?
电脑杂谈 发布时间:2020-08-02 06:02:50 来源:网络整理

Quadro和Geforce之间最明显的区别是驱动程序对OpenGL的支持以及视频内存的大小,最明显的价格因素除外.
视频内存的大小可以从图形卡参数中看到. 我不会详细说明. 影响实际上与CPU的内存相同: 更多的东西是无用的,更少的卡死. 但是多少就足够了? Geforce面临的应用程序主要是游戏. 在一定时期内,大多数游戏使用几个特定的游戏引擎. 面对流行的显示分辨率,常用的纹理大小和模型复杂度,只要它们可以,就足以满足这些游戏引擎的需求. Quadro面临的应用并非如此. 它可能只是具有数十万个多边形的一般复杂性的零件,或者是由数亿个多边形组成的精密零件模型,例如航空发动机模型和车身模型. 复杂性通常由实际需求决定,在某些情况下,视频内存不够用-当然,显卡制造商无法提供无限的视频内存容量,始终要考虑成本问题和GPU的处理能力本身也很有限. 另外,我需要指出的是,GPU计算在当今越来越普遍. 许多计算应用程序对视频内存的需求也因不同的计算内容而大大不同. 大量的应用程序用于处理某些特定的操作. 当数量较少时,具有相同内核的Quadro的性能将比Geforce差(Quadro的频率通常低于Geforce),但是在数据量超过一定阈值后,Quadro的性能将比Geforce显着提高.
驱动程序对OpenGL的支持,许多语句均已完成. 我自己从未做过OpenGL开发,而且我不是图形卡从业人员. 在看到来自可靠来源的文章的论点和解释之前,我个人保留意见. 但是,显而易见的和可验证的是几种常见的基于OpenGL的CAD软件的性能差距[1]:
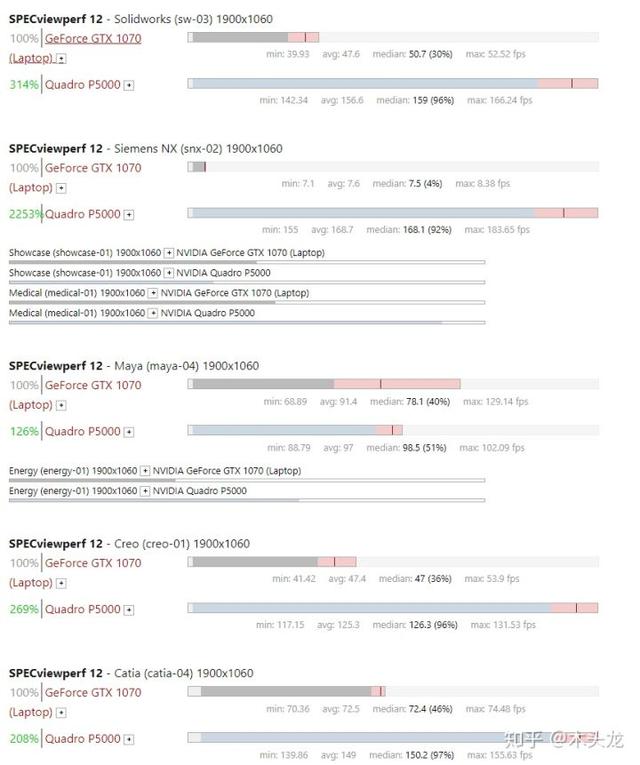

从比较数据中可以看出,Geforce 1070(移动版)和Quadro P5000(也基于GP104芯片,2048个CUDA单元)位于Solidwords,Creo和CATIA子项目中. 在SPECviewperf测试中,Quadro的性能分别提高了314%,269%,208%,在Siemens NX项目中,它已经达到了2253%的夸大差距. 相比之下,在使用Direct3D的Maya子项目中,平均得分为P5000的性能提高仅为126%. 如果您查看最高分数,则仅为79%,不及Geforce.
造成这种性能差异的原因,正如我所看到的一些文章中所解释的那样,许多CAD软件都使用OpenGL中的固定功能管线接口. 此接口主要用于早期顶点单位/像素单位. 独立的图形卡. 在显卡制造商提出了统一的渲染架构之后,OpenGL放弃了3.0版中的相关API,并被分类为Legacy OpenGL [2],但是大多数CAD软件仍使用相关接口,而Geforce不再提供对Legacy OpenGL的支持. 该声明类似于其他答案中提到的Geforce对OpenGL的不完全支持,但是我所见的文章均未提供可靠的源证书,因此可以作为参考.
除了这两个明显的区别外,Quadro专注于稳定性和正确性,Geforce专注于性能. 在稳定性方面,通常,Quadro的工作频率较低,具有原始质量,并使用ECC内存来避免可能的内存数据错误. 在驱动程序方面,所有主要的CAD软件供应商都已认证驱动程序,也就是说,该版本的驱动程序已经过严格测试. 话虽如此,稳定是一件非常虚构的事情. 这些措施不能保证100%的问题. 没有这些措施的Geforce通常不会出现问题. 只能说概率不同.
就正确性而言,由于GPU是并行处理的,因此实际上并非所有操作都可以完全并行. 总会有一些线程的计算会影响其他线程的结果. 但是,由于它是并行处理,因此很难保证受影响的线程必须首先完成计算. 例如,一个场景上有一朵花,上面有一只蜜蜂. 我们所看到的应该是蜜蜂覆盖后面的花朵,但是如果渲染蜜蜂的线程先完成工作,然后完成花朵的渲染,则可能会在屏幕上看到蜜蜂躲在花朵后面. Quadro的驱动程序在检查此类情况时非常严格,并将保证不会发生此类情况. 为了游戏性能,Geforce忽略此类错误的可能性很小. 像稳定性一样,正确性也是概率问题.
图形卡比较头2头,应注意,笔记本检查单个附件的得分是通过使用该附件的多个笔记本型号的平均测试结果得出的. 不同的笔记本电脑使用不同的CPU,不同的散热能力可能会导致某些问题. 性能存在很大差异. 您可以单击图形卡型号以查看特定型号的分数.


差异在于图形卡支持的不同驱动程序显示功能. 游戏卡根据DirectX标准进行渲染和显示. 卡是基于OpenGL标准支持和优化渲染和显示的驱动程序. 该游戏卡还支持OpenGL标准,但是没有优化,据说缺少一些功能支持,这是不完整的.
主要区别在于所使用软件界面的实时显示模式. 像某些的3D工程制作软件一样,它支持OpenGL模式以进行实时渲染和显示. 因此,这些软件中的卡模型显示可以轻松浏览和显示. 当在工程方向上在3D软件中使用时,游戏卡不能优化和支持此显示标准. 一旦模型具有大量面孔,就会出现挫折感和显示准确性的问题(当然,几年前非工程CG生产软件已开始优化对游戏卡的支持. Autodesk的Maya和3ds max都支持DX驱动程序实时显示界面,因此美术卡在CG方向软件中的优势消失了补充: 不清楚D是否优化了对游戏卡的支持,因为D显示在openGL中,而D软件在显示屏上,当模型表面达到100万时,GTX980游戏卡将非常卡住. )在像Octane Render这样的GPU渲染器出现之前,卡的作用是3D软件操作界面中显示优化的优势. 没什么特别的.
除了在驾驶显示方式上的差异外,最明显的差异是显卡的显存通常大于同级别和核心架构的游戏卡,尤其是高端显卡. 虽然游戏卡的11GB显存仍感觉优越,但卡已用于16GB或24GB或更高的32GB显存段.
在2010年左右以Octane Render为代表的GPU渲染器出现之后.

大容量视频存储器对于3D渲染制作非常有帮助,使创建复杂场景变得更加容易,尤其是在显示GPU渲染时,数据将在视频存储器中读取. 视频内存容量低会影响渲染速度,有时会特别卡住,有时会出现渲染失败或错误消息. 当然,游戏卡的优势在于主频率高,因此,当视频内存和架构核心处于同一级别时,在执行GPU渲染时,游戏卡将比卡更快. 经过比较,游戏卡通常比具有相同核心架构的卡高20-25%. 但是卡在存储容量和稳定性方面都有优势(废话,低频当然是稳定的).
(此外,GPU渲染着眼于单精度浮点计算,因此,卡的双精度浮点计算优势毫无用处)
因此,这取决于您对显卡的处理方式. 例如,如果它是3D软件的工程应用程序
SolidWorks,CATIA和其他工程应用程序,那么使用显卡就很有意义.
如果使用GPU进行渲染,则显卡在高端版本中仅具有一定的内存容量和ECC纠错优势,但是与价格相比,它并不是很高,除非您特别注意时间成本(因为新一代顶级游戏卡将超越1-1.5年内顶级卡的性能),否则无需使用高端图形卡进行GPU计算. 当然,卡的视频存储优势可以创建更复杂的场景,而游戏卡不能暂时超越这些场景. 这只能通过优化场景的技术来实现.

据估计,今年发布的新一代12nm工艺1180或所谓的2080游戏卡应能满足大多数GPU渲染需求(即使单精度浮点计算能力类似于1080ti, GDDR6技术在内存上的带宽优势和容量优势,渲染速度和渲染运行得分会更高. ),只要它不是电影级的超大型场景,就没有问题. 也许明年的新一代7nm工艺图形卡将达到22或24GB?这取决于老黄的刀.


视频编码.
Geforce系列NVENC最多只能同时运行2个会话,而Quadro和Tesla没有任何限制.
以Pascal架构为例. 单个NVENC单元的性能可以达到600fps. 如果用于电影压缩,则可以在1秒内压缩600帧,可以在3分钟内压缩1小时的视频,这比软编辑快得多. 但是,如果将其用于实时编码(例如现场直播应用程序),则一般帧速率为30fps,但是可能有必要同时对多个流进行编码. 如果是Geforce系列,无论是1030还是1080Ti,则只能同时编码两个通道. 最多只能使用60fps的性能,而其余的则被浪费了. 但是Quadro,Tesla系列没有此限制,最大性能仅取决于GPU和GDDR的频率.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shenmilingyu/article-290053-1.html
-

-
王威华
股市
-
刘晏
小生产线永不停
 svchost.exe查杀_svchost.exe占网速_klwtblfs.exe是什么进程
svchost.exe查杀_svchost.exe占网速_klwtblfs.exe是什么进程 台式机安装显卡的步骤是什么?什么是显卡?
台式机安装显卡的步骤是什么?什么是显卡? NVIDIA控制面板
NVIDIA控制面板 显卡温度测试软件哪个好?鲁大师温度监控独立版下载
显卡温度测试软件哪个好?鲁大师温度监控独立版下载
美日下一个打的就是