汉王pdf ocr8.1简体中文破解版下载
电脑杂谈 发布时间:2020-04-05 17:18:00 来源:网络整理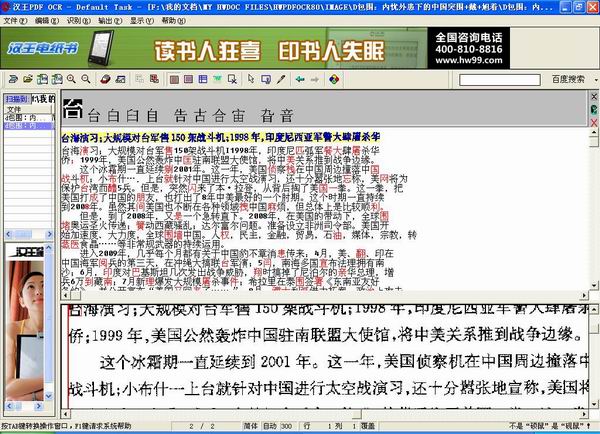
汉王pdf ocr 8.1破解版是一种文本和图片识别工具,可以快速识别图片的内容,无论是手写的还是打印的,只要图像质量清晰,就可以快速而准确地识别出来. 将图片中的文本转换为可编辑的Word文档,txt文件,并执行简单的自动排版. 对于图书出版商和小说写作用户来说,汉王pdf ocr软件提供了极大的帮助和便利.

1. 该软件集成了破解补丁,打开HWPDFOCR80.exe即可使用,非常方便

1. 图像输入,图像预处理,预识别.
2. 图像输入

对于不同的图像格式,有不同的存储格式和不同的压缩方法. 当前,有开源项目汉王 pdf ocr破解版,例如OpenCV和CxImage.
3. 预处理
主要包括二值化,噪声消除和倾斜校正.
4. 二值化
相机拍摄的大多数照片都是彩像. 彩像包含大量信息. 图片的内容可以简单地分为前景和背景. 我们需要先处理彩像,以便图片仅包含前景信息和背景信息. 我们可以简单地将前景信息定义为黑色,将背景信息定义为白色.
5. 噪音消除
对于不同的文档,噪声的定义可以不同. 根据噪声的特征进行干燥称为噪声去除.
6. 倾斜校正
由于普通用户在拍照时比较随意,所拍摄的照片不可避免地会倾斜,这需要文本识别软件来校正.
7. 布局分析
将文档图像分为段落和分支的过程称为布局分析. 由于实际文档的多样性和复杂性,目前还没有固定和最佳的裁切模型.
8. 人物剪裁

由于拍摄条件的限制,人物经常会粘住笔并折断笔,这极大地限制了识别系统的性能.
9. 字符识别
这项研究已经很早了. 模板匹配相对较早. 后来,特征提取是主要原因. 由于文本的位移,笔划的粗细,笔划的断裂,附着力,旋转等因素,极大地影响了特征提取的难度.
10. 布局恢复
人们希望识别出的文本仍然像原始文档图片一样排列,具有相同的段落和位置,并以相同的顺序输出到Word文档汉王 pdf ocr破解版,PDF文档等. 此过程称为布局恢复.
11. 后处理,校对

根据特定语言上下文的关系,纠正识别结果是后处理. 1.识别字符
简体字符集: GB2312-80的一年级和二年级有6800多个汉字.
纯英文字符集.
简体中文和繁体中文字符: 除了简体中文字符,您还可以混合使用5400多个繁体中文字符以及繁体中文和GBK汉字.
2. 识别字体类型
它可以识别超过100种字体,例如Song,Important Song,Kai,Hei,Wei Bei,Li Shu,Yuan Ting,Xing Kai等,并且支持多种字体.
3. 确定字体大小
第一个数字,第六个小字体.
4. 表单识别
可以自动判断,拆分,识别和恢复各种常规打印形式
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/ruanjian/article-164972-1.html
 淘宝不能买虚拟 经验:宝妈妮子宝贝教你刷单赚钱平台是真的吗
淘宝不能买虚拟 经验:宝妈妮子宝贝教你刷单赚钱平台是真的吗 手机怎样才能获得root权限手机的电池咋提高容量?手机评测的
手机怎样才能获得root权限手机的电池咋提高容量?手机评测的 QQ飞车手游内测版正式版下载
QQ飞车手游内测版正式版下载 事实:当笔记本电脑崩溃时如何强行关闭笔记本电脑
事实:当笔记本电脑崩溃时如何强行关闭笔记本电脑
支持