汉王PDF OCR v8.1.4.16绿色中文破解版下载(附上使用方法)
电脑杂谈 发布时间:2020-04-05 17:16:28 来源:网络整理
汉王PDF OCR是中国市场上最的ocr文本识别软件. 该软件使用成熟的OCR识别技术,并支持JPG,BMP,PNG,MP3,MAV,TIF和其他格式. 图片识别是TXT,可有效识别各种类型. 复杂的字体和声音. 对于图形内容软件,您可以一键阅读文档,恢复文档的逻辑结构和格式,而无需重新输入和布局. 该软件具有针对具有混合图形和文本的文档的自动分析功能,并且在划分文本区域后会自动识别. 这里的编辑器提供了汉王PDF OCR8.1绿色中文破解版,它不仅具有较高的识别率和快速的识别速度,而且最重要的是它对于个人用户是完全免费的. 它可以快速打开和使用,而无需安装和破解,没有任何功能限制. 快来和您最喜欢的朋友一起尝试吧!
1. 删除了令人反感的图片广告内容,使界面更整洁,更易于使用!
2. 文件版本已更新为最新版本! 1.识别字符
简体字符集: GB2312-80的一年级和二年级有6800多个汉字.
纯英文字符集.
简体中文和繁体中文字符: 除了简体中文字符,您还可以混合使用5400多个繁体中文字符以及繁体中文和GBK汉字.

2. 识别字体类型
它可以识别超过100种字体,例如Song,Important Song,Kai,Hei汉王 pdf ocr破解版,Wei Bei,Li Shu,Yuan Ting,Xing Kai等,并且支持多种字体.
3. 确定字体大小
初始编号,第六种小字体等
4. 表单识别
它可以自动判断,拆分,识别和恢复各种常规打印形式. 1.在桌面或开始菜单上打开OCR软件
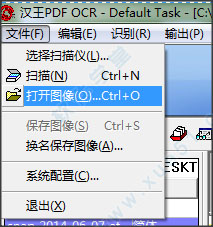
2. 单击[文件]-[打开图像文件],然后选择包含文本的图片
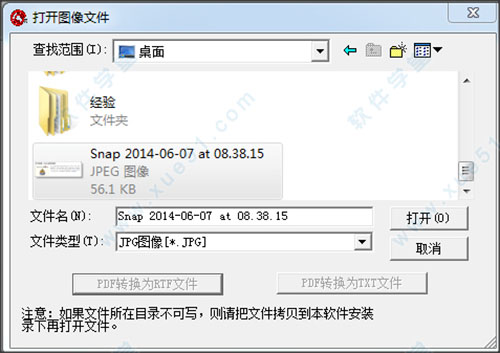
3. 点击[识别]-[开始识别]
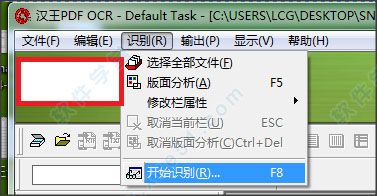
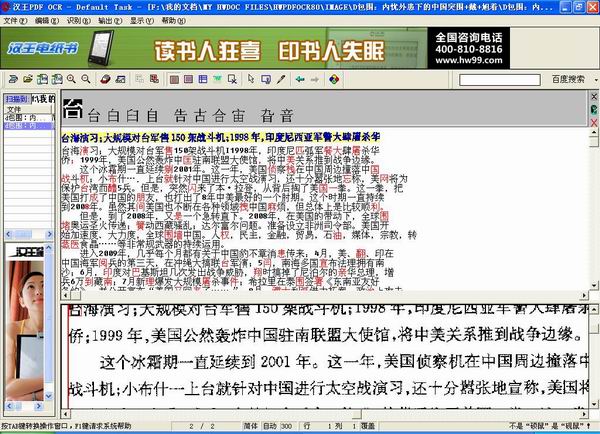
4. 该软件将识别图片上的文字,并可以修改一些错误识别的单词
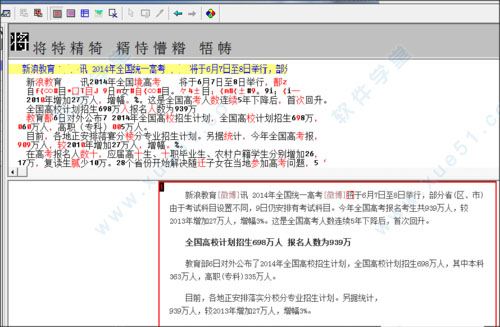
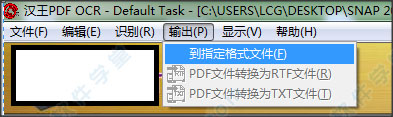
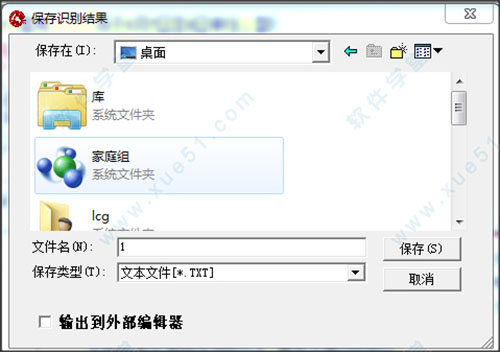
5. 修改完成后汉王 pdf ocr破解版,单击[导出]-[以指定格式]保存识别的文本
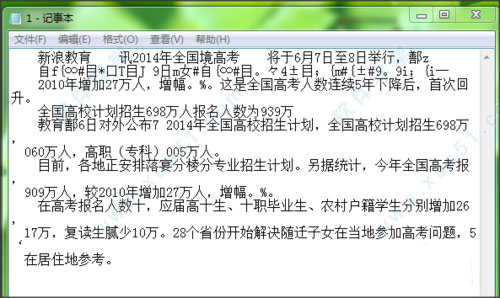
6. 您可以打开保存的文本,将文本复制到Word和其他软件进行二次编辑
1. 识别精度高,识别速度快,批处理功能;
2. 支持处理BMP,TIF,JPG和PDF格式的灰色,彩色和黑白图像文件;

3. 它可以识别简体,繁体和英文;
4. 简单易用的表单识别功能;
5. 它具有TXT,RTF,HTM和XLS的多种输出格式,并具有所见即所得的布局恢复功能. 扫描文件: 按“ Ctrl + N”调出扫描程序并扫描图像文件.
打开文件: 按“ Ctrl + O”打开图像文件并添加图像文件.
保存图像: 按“ Ctrl + S”保存图像.
图像突出显示: 按“ Ctrl + I”突出显示图像.
自动倾斜校正: 按“ Ctrl + D”以执行自动倾斜校正.
手动倾斜校正: 按“ Ctrl + M”执行手动倾斜校正.
布局分析: 按“ F5”键对所选文件执行布局分析.
取消布局分析: 按“ Ctrl + Del”键可取消当前页面的布局分析.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/ruanjian/article-164966-1.html
-

-
王磊
我也是
-
斋贺观月
难道我做出的产品会把不合格的送去质检局检测
-
-
何欣源
有这回事吗
 公关快捷键大全+干货+收藏夹
公关快捷键大全+干货+收藏夹 反思网络上的暴风雨视频和音频
反思网络上的暴风雨视频和音频 Le 1 32GB
Le 1 32GB 如果无法安装win10系统声卡驱动程序,该怎么办?无法安装win10声卡的解决方案
如果无法安装win10系统声卡驱动程序,该怎么办?无法安装win10声卡的解决方案
兄弟