如何定义链表结点的数据结构?
电脑杂谈 发布时间:2019-05-06 18:32:15 来源:网络整理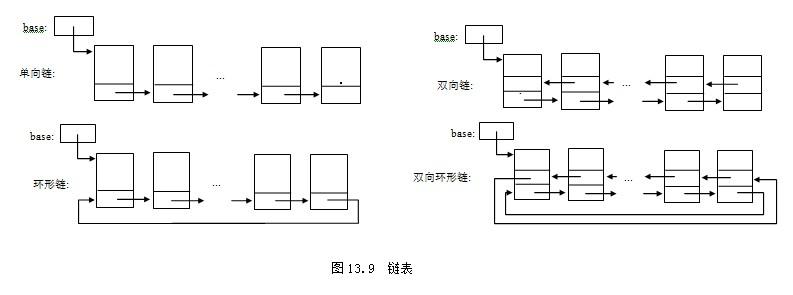
1.1.1 数据与p_next分离
由于链表只关心p_next指针,因此完全没有必要在链表结点中定义数据域,那么只保留p_next指针就好了。链表结点的数据结构(slist.h)定义如下:
1 typedef struct _slist_node{
2 struct _slist_node *p_next; // 指向下一个结点的指针
3 }slist_node_t;
由于结点中没有任何数据,因此节省了内存空间,其详见图3.10。

图3.10 链表
当用户需要使用链表管理数据时,仅需关联数据和链表结点,最简单的方式是将数据和链表结点打包在一起。以int类型数据为例,首先将链表结点作为它的一个成员,再添加与用户相关的int类型数据,该结构体定义如下:
1 typedef struct _slist_int{
2 slist_node_t node; // 包含链表结点
3 int data; // int类型数据
4 }slist_int_t;
由此可见,无论是什么数据,链表结点只是用户数据记录的一个成员。当调用链表接口时,仅需将node的地址作为链表接口参数即可。在定义链表结点的数据结构时,由于仅删除了data成员,因此还是可以直接使用原来的slist_add_tail()函数,管理int型数据的范例程序详见程序清单3.14。
程序清单3.14 管理int型数据的范例程序
1 #include
2 typedef struct _slist_int{
3 slist_node_t node;
4 int data;
5 }slist_int_t;
6
7 int main (void)
8 {
9 slist_node_t head = {NULL};
10 slist_int_t node1, node2, node3;
11 slist_node_t *p_tmp;
12
13 node1.data = 1;
14 slist_add_tail(head, node1.node);
15 node2.data = 2;
16 slist_add_tail(head, node2.node);
17 node3.data = 3;
18 slist_add_tail(head, node3.node);
19 p_tmp = head.p_next;
20 while (p_tmp != NULL){
21 printf(%d , ((slist_int_t *)p_tmp)->data);
22 p_tmp = p_tmp->p_next;

23 }
24 return 0;
25 }
由于用户需要初始化head为NULL,且遍历时需要操作各个结点的p_next指针。链表的数据结构而将数据和p_next分离的目的就是使各自的功能职责分离,链表只需要关心p_next的处理,用户只关心数据的处理。因此,对于用户来说,链表结点的定义就是一个“黑盒子”,只能通过链表提供的接口访问链表,不应该访问链表结点的具体成员。
在main函数中,先定义一个头结点指针head,然后调用create函数创建链表,并将链表的头结点。最近看了《剑指offer》这本书,遇到了一个问题:反转链表 题目:定义一个函数,输入一个链表的头结点,反转该链表并输出反转后的链表的头结点。问题描述 定义一个函数,输入一个链表的头结点,反转该链表并输出反转后的链表的头结点。
int slist_init (slist_node_t *p_head);
由于头结点的类型与其它普通结点的类型一样,因此很容易让用户误以为,这是初始化所有结点的函数。实际上,头结点与普通结点的含义是不一样的,由于只要获取头结点就可以遍历整个链表,因此头结点往往是被链表的拥有者持有,而普通结点仅仅代表单一的一个结点。为了避免用户将头结点和其它结点混淆,需要再定义一个头结点类型(slist.h):
typedef slist_node_t slist_head_t;
基于此,将链表初始化函数原型(slist.h)修改为:
int slist_init (slist_head_t *p_head);
其中,p_head指向待初始化的链表头结点,slist_init()函数的实现详见程序清单3.15。
程序清单3.15 链表初始化函数
1 int slist_init (slist_head_t *p_head)
2 {
3 if (p_head == NULL){
4 return -1;
5 }
6 p_head -> p_next = NULL;
7 return 0;
8 }
在向链表添加结点前,需要初始化头结点。即:
slist_node_t head;
slist_init(head);
由于重新定义了头结点的类型,因此添加结点的函数原型也应该进行相应的修改。即:
int slist_add_tail (slist_head_t *p_head, slist_node_t *p_node);
其中,p_head指向链表头结点,p_node为新增的结点,slist_add_tail()函数的实现详见程序清单3.16。链表的数据结构
程序清单3.16 新增结点范例程序
1 int slist_add_tail (slist_head_t *p_head, slist_node_t *p_node)
2 {
3 slist_node_t *p_tmp;
4
5 if ((p_head == NULL) || (p_node == NULL)){
6 return -1;
7 }
8 p_tmp = p_head;
9 while (p_tmp -> p_next != NULL){
10 p_tmp = p_tmp -> p_next;
11 }

12 p_tmp -> p_next = p_node;
13 p_node -> p_next = NULL;
14 return 0;
15 }
同理,当前链表的遍历采用的还是直接访问结点成员的方式,其核心代码如下:
1 slist_node_t *p_tmp = head.p_next;
2 while (p_tmp != NULL){
3 printf(%d , ((slist_int_t *)p_tmp)->data);
4 p_tmp = p_tmp->p_next;
5 }
这里主要对链表作了三个操作:(1)得到第一个用户结点;(2)得到当前结点的下一个结点;(3)判断链表是否结束,与结束标记(NULL)比较。
基于此,将分别提供三个对应的接口来实现这些功能,避免用户直接访问结点成员。它们的函数原型为(slist.h):
slist_node_t *slist_begin_get (slist_head_t *p_head); // 获取开始位置,第一个用户结点
slist_node_t *slist_next_get (slist_head_t *p_head, slist_node_t *p_pos);// 获取某一结点的后一结点
= null) { // 建立一个while循环,结束条件是到达尾结点。 // p1指前面的结点(原链表),刚开始赋null是为了让第一个结点(也就是倒置后的尾结点)的地址区间清空。把尾结点和头结点的关系给干掉,展成一条链,回到头结点,往下移动,在往下移动前,先游历这个结点,在判断能不能往下。
其实现代码详见程序清单3.17。
程序清单3.17 遍历相关函数实现
1 1 1 1 1 1 3 1 1 2 2 2 3 2 1 2 2 1 2 1 2 2 3 1 1 1 1 1 1 1 5 1 1 1 1 1 1 1 1 1 3 1 1。0 0 3 1 1 1 1 3 1 1 2 0 1 2 1 1 3 2 2 1 1 1 1 2 1 1 1 1 1 1 0 0 1 1 1 3 0 1 1。2 2 3 1 1 1 1 3 1 1 1 1 2 2 1 1 1 1 1 0 1 1 1 2 1 3 2 3 1 1 1 3 1 2 3 1 2 1 1 1 1 1 1。
关键词: 链表结点 数据结构
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-96742-1.html
-

-
郭鹏飞
海洋公约的缔约国当然可以说12海里是入侵
-
柳凤霞
-
-
危昂霄
发挥了正能量
![一宝店: 在Windows 7中,该程序不能[锁定到任务栏]或[附加到开始菜单]?](http://www.win7zhijia.cn/upload/2020/07/23/1347/159548327110786999289.png) 一宝店: 在Windows 7中,该程序不能[锁定到任务栏]或[附加到开始菜单]?
一宝店: 在Windows 7中,该程序不能[锁定到任务栏]或[附加到开始菜单]? if函数的嵌套计算公式的使用
if函数的嵌套计算公式的使用 在中国有多少人感染了埃博拉病毒,如何预防感染
在中国有多少人感染了埃博拉病毒,如何预防感染 用前端设计图进行编码,西安交通大学表示,复杂的界面也可以逐步完成
用前端设计图进行编码,西安交通大学表示,复杂的界面也可以逐步完成
吓死宝宝了