哈夫曼编码(Huffman Coding),又称霍夫曼编码,
电脑杂谈 发布时间:2019-04-29 23:25:40 来源:网络整理
求哈夫曼编码,实质上就是在已建立的哈夫曼树中,从叶结点开始,沿结点的双亲链域回退到根结点,每回退一步,就走过了哈夫曼树的一个分支,从而得到一位哈夫曼码值,由于一个字符的哈夫曼编码是从根结点到相应叶结点所经过的路径上各分支所组成的0,1 序列,因此先得到的分支代码为所求编码的低位码,后得到的分支代码为所求编码的高位码。,构造一棵哈夫曼编码树,规定哈夫曼编码树的左分支代表0,右分支代表1,则从根结点到每个叶子结点所经过的路径组成的0-1序列便是该叶子结点对应字符的编码,称为哈夫曼编码。哈夫曼编码是上个世纪五十年代由哈夫曼教授研制开发的,它借助了数据结构当中的树型结构,在哈夫曼算法的支持下构造出一棵最优二叉树,我们把这类树命名为哈夫曼树.因此,准确地说,哈夫曼编码是在哈夫曼树的基础之上构造出来的一种编码形式,它的本身有着非常广泛的应用.那么,哈夫曼编码是如何来实现数据的压缩和解压缩的呢。
1952年,David A. Huffman在麻省理工攻读博士时发表了《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)一文,它一般就叫做Huffman编码。[1]
Huffman在1952年根据香农(Shannon)在1948年和范若(Fano)在1949年阐述的这种编码思想提出了一种不定长编码的方法,也称霍夫曼(Huffman)编码。霍夫曼编码的基本方法是先对图像数据扫描一遍,计算出各种像素出现的概率,按概率的大小指定不同长度的唯一码字,由此得到一张该图像的霍夫曼码表。哈夫曼树的编码c编码后的图像数据记录的是每个像素的码字,而码字与实际像素值的对应关系记录在码表中。
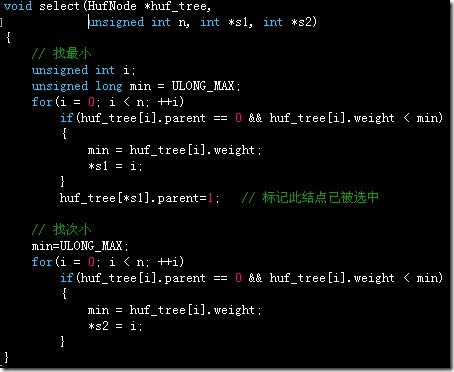
哈夫曼编码是一种可变长的编码,它依据字符出现的概率来决定字符编码的长度,使得出现概率大的字符编码长度短,出现概率小的字符的编码长度长,于是可以减少整体的编码的长度。 其中 rnlrnlog'2、 香农第一定理(可变长无失真信源编码定理) 信息论与编码基础 香农三大定理 简介 说明: 1) 通过对扩展信源进行可变长编码, 可以使平均码长无限趋近 于极限熵值, 但这是以编码复杂性为代价的。利用字符出现的频率决定编码这一思想是huffman编码的基础,huffman编码是所有无前缀编码中最优的一种编码策略。
原理
设某信源产生有五种符号u1、u2、u3、u4和u5,对应概率P1=0.4,P2=0.1,P3=P4=0.2,P5=0.1。首先,将符号按照概率由大到小排队,如图所示。编码时,从最小概率的两个符号开始,可选其中一个支路为0,另一支路为1。这里,我们选上支路为0,下支路为1。再将已编码的两支路的概率合并,并重新排队。多次重复使用上述方法直至合并概率归一时为止。从图(a)和(b)可以看出,两者虽平均码长相等,但同一符号可以有不同的码长,即编码方法并不唯一,其原因是两支路概率合并后重新排队时,可能出现几个支路概率相等,造成排队方法不唯一。一般,若将新合并后的支路排到等概率的最上支路,将有利于缩短码长方差,且编出的码更接近于等长码。这里图(a)的编码比(b)好。

赫夫曼码的码字(各符号的代码)是异前置码字,即任一码字不会是另一码字的前面部分,这使各码字可以连在一起传送,中间不需另加隔离符号,只要传送时不出错,收端仍可分离各个码字,不致混淆。
实际应用中,除采用定时清洗以消除误差扩散和采用缓冲存储以解决速率匹配以外,主要问题是解决小符号集合的统计匹配,例如黑(1)、白(0)传真信源的统计匹配,采用0和1不同长度游程组成扩大的符号集合信源。除采用定时清洗以消除误差扩散和采用缓冲存储以解决速率匹配以外。采用0和1不同长度游程组成扩大的符号集合信源。
[1]徐佳迪.霍夫曼编码及其效率的研究[D].江苏:南京林业大学电子信息工程学院,2012

[2]静态哈夫曼编码的原理及应用.知网[引用日期2016-11-19]
[3]动态哈夫曼编码的数据压缩方法.知网[引用日期2016-11-20]
[4]《信息论与编码》清华大学出版社 曹雪虹编著 第二版

[5]简单快速的哈夫曼编码.VC知识库文章.2007-01-21[引用日期2013-07-23]
[6]张丽英,王世祥.信息论与编码基础教程.清华大学出版社,2010年04月
[7]严蔚敏,吴伟民.数据结构(C语言版).清华大学出版社,1997年4月第一版:147-148
[8]吴记群,李双科.Matlab下实现huffman编码[J].中国科技信息,2006,19
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-95076-1.html
-

-
刘禹
-
王双凤
期待
-
曹圆
重要的事说三遍
-
 笔记本换硬盘后如何装系统?
笔记本换硬盘后如何装系统? 【jy135】台式机使用usb无线网卡网速慢解决方法
【jy135】台式机使用usb无线网卡网速慢解决方法 月底结转会计分录!
月底结转会计分录! 日程安排软件
日程安排软件
直接撞沉美帝看它下次还来不来