分布式存储环境 Kubernetes节点扩容规模至2500的历程
电脑杂谈 发布时间:2018-02-19 16:01:32 来源:网络整理
原标题:Kubernetes节点扩容规模至2500的历程

我们使用Kubernetes做深度学习的研究已经超过两年。尽管我们最大的工作量直接管理裸云VM,但是Kubernetes提供了快速的迭代周期、具有合理的扩展性以及不含样板代码(a lack of boilerplate),所以在Kubernetes上进行的实验大多都达到了我们预期。我们现在运行着几个Kubernetes集群(一些在云上,一些在物理机机上),其中最大的已经超过2500节点。这些集群运行在Azure提供的D15v2和NC24 组合虚拟机上。
达到现在这个节点规模,我们也经历过很多问题。比如许多系统组件引起的问题:包括etcd、Kubernetes的master节点、Docker镜像获取问题、Network问题、KubeDNS,甚至是我们机器上的ARP缓存。我认为分享这些我们遇到的具体问题,以及我们是怎么解决这些问题是很有意义的。
etcd
在我们集群到500个节点之后,我们的researchers开始从kubectl命令行工具得到定时超时的警告。 我们尝试添加更多Kubernetes master(运行kube-apiserver的VM)。 这似乎暂时解决了这个问题,但是一连经历10次后,我们意识到这只是在处理症状,而没发现真正的原因(相比之下,GKE使用32位单核虚拟机支撑500个节点)。
这让我们非常怀疑是提供Kube master中央状态存储区的etcd集群出了问题。 从Datadog看来,尽管每台机器都使用能够达到5,000 IOPS的P30 SSD,但是在运行我们的etcd副本的DS15v2机器上,我们看到写入有几百毫秒的延迟。
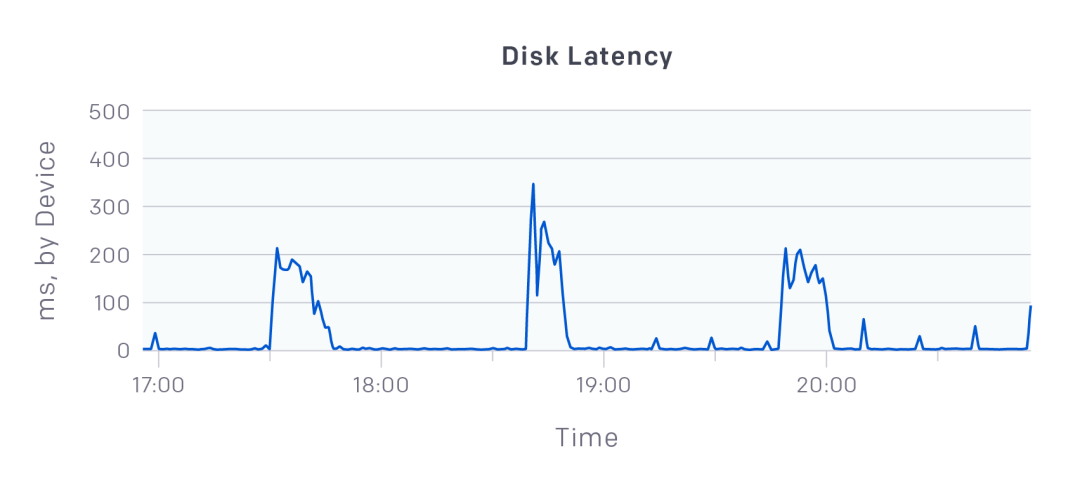
这些延迟峰值阻塞了整个集群!
在fio[1]的基准测试中,我们发现etcd只能使用大约10%的IOPS,因为写延迟是2ms,etcd是连续的I/O,因此引起一连串的延迟。
然后,我们将每个节点的etcd目录移动到本地临时磁盘,这是一个直接连接到实例的SSD,而不是网络连接。分布式存储环境切换到本地磁盘带后写延迟达到200us,etcd恢复正常!
直到我们达到大约1,000个节点以前,我们的集群运行良好。在1,000这一点上,我们再次看到了etcd的提交高延迟。这一次,我们注意到kube-apiservers从etcd上读取了超过500MB/s。我们设置了Prometheus来监视apiservers,还设置了--audit-log-path和--audit-log-maxbackup标志,以便在apiserver上启用更多的日志记录。这就出现了一些缓慢的查询和对事件列表API的过度调用。
根本原因:Fluentd和Datadog监控进程的默认设置是从集群中的每个节点查询apiservers(例如,现在已解决的问题[2])。 我们只是简单地改变了这些调用的过程,使apiservers的负载变得稳定。

etcd出口从500MB / s 下降到几乎为0(上图中的负值表示出口)
另一个有用的调整是将Kubernetes事件存储在一个单独的etcd集群中,以便事件创建中的峰值不会影响主要etcd实例的性能。 要做到这一点,我们只需将--etcd-servers-overrides标志设置为如下所示:
-etcd-servers-overrides= /events#https://0.example.com:2381;https://1.example.com:2381;https:// 2.example.com: 2381
另一个超过1,000后节点故障是超过了etcd的硬盘存储限制(默认2GB),导致硬盘拒绝写入。 这引发了一个级联失败:所有的Kube节点都健康检查失败,我们的autoscaler决定它需要终止所有的任务。 我们用--quota-backend-bytes标志增加了max etc的大小,现在autoscaler有了一个智能的检查,如果它终止超过50%的集群,不会采取行动。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-85241-1.html
-

-
陶立娜
一直很好
对美国不要抱任何幻想