实时计算服务平台 redis应用场景及实例(8)
电脑杂谈 发布时间:2018-02-10 01:00:10 来源:网络整理KISS原则,这对于开发是非常友好的,我只需要建立一套连接池,不用担心数据一致性的维护,不用维护异步队列。

Cache穿透风险,如果后端使用DB,肯定不会提供很高的吞吐能力,cache宕机如果没有妥善处理,那就悲剧了。
大多数的起始存储需求,容量较小。
2.Reverse cache(反向cache)
面对微博常常出现的热点,如最近出现了较为火爆的短链,短时间有数以万计的人点击、跳转,而这里会常常涌现一些需求,比如我们向快速在跳转时判定用户等级,是否有一些账号绑定,性别爱好什么的,已给其展示不同的内容或者信息。
普通采用memcache+Mysql的解决方案,当调用id合法的情况下,可支撑较大的吞吐。但当调用id不可控,有较多垃圾用户调用时,由于memcache未有命中,会大量的穿透至Mysql服务器,瞬间造成连接数疯长,整体吞吐量降低,响应时间变慢。
这里我们可以用redis记录全量的用户判定信息,如string key:uid int:type,做一次反向的cache,当用户在redis快速获取自己等级等信息后,再去Mc+Mysql层去获取全量信息。如图:
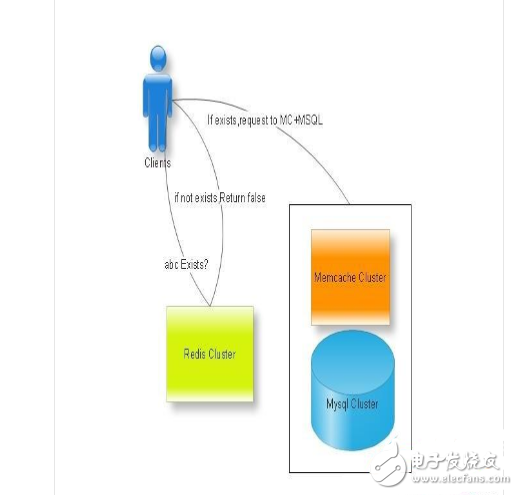
当然这也不是最优化的场景,如用Redis做bloomfilter,可能更加省用内存。
3.Top 10 list
产品运营总会让你展示最近、最热、点击率最高、活跃度最高等等条件的top list。很多更新较频繁的列表如果使用MC+MySQL维护的话缓存失效的可能性会比较大,鉴于占用内存较小的情况,使用Redis做存储也是相当不错的。
4.Last Index
用户最近访问记录也是redis list的很好应用场景,lpush lpop自动过期老的登陆记录,对于开发来说还是非常友好的。
5.Relation List/Message Queue
这里把两个功能放在最后,因为这两个功能在现实问题当中遇到了一些困难,但在一定阶段也确实解决了我们很多的问题,故在这里只做说明。
Message Queue就是通过list的lpop及lpush接口进行队列的写入和消费,由于本身性能较好也能解决大部分问题。
6.Fast transaction with Lua
Redis 的Lua的功能扩展实际给Redis带来了更多的应用场景,你可以编写若干command组合作为一个小型的非阻塞事务或者更新逻辑,如:在收到 message推送时,同时1.给自己的增加一个未读的对话 2.给自己的私信增加一个未读消息 3.最后给发送人回执一个完成推送消息,这一层逻辑完全可以在Redis Server端实现。
但是,需要注意的是Redis会将lua script的全部内容记录在aof和传送给slave,这也将是对磁盘,网卡一个不小的开销。
7.Instead of Memcache
很多测试和应用均已证明,
在性能方面Redis并没有落后memcache多少,而单线程的模型给Redis反而带来了很强的扩展性。
在很多场景下,Redis对同一份数据的内存开销是小于memcache的slab分配的。
Redis提供的数据同步功能,其实是对cache的一个强有力功能扩展。
Redis使用的重要点
1.rdb/aof Backup!
我们线上的Redis 95%以上是承担后端存储功能的,我们不仅用作cache,而更为一种k-v存储,他完全替代了后端的存储服务(MySQL),故其数据是非常重要的,如果出现数据污染和丢失,误操作等情况,将是难以恢复的。所以备份是非常必要的!为此,我们有共享的hdfs资源作为我们的备份池,希望能随时可以还原业务所需数据。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-69513-8.html
-

-
玖兰枢
否则美国实在受不了这个刺激会发疯的
-
-
安定王
先打
 win8/8.1万能网卡驱动功能特点及特点介绍(组图)
win8/8.1万能网卡驱动功能特点及特点介绍(组图) 为什么样如今的PC不带蓝牙功能?主板带的光纤输出相比USB输出
为什么样如今的PC不带蓝牙功能?主板带的光纤输出相比USB输出 管理信息系统操作
管理信息系统操作 unicode编码转换器download_unicode编码转换器v1.0免费版
unicode编码转换器download_unicode编码转换器v1.0免费版
关键是远程的数量