什么是关系 【交易技术前沿】从数据到智慧:证券行业知识图谱应用实践 /(2)
电脑杂谈 发布时间:2018-02-08 16:46:32 来源:网络整理常用的实体关系抽取方法,有基于专家知识库的方法,和基于机器学习的方法等等。基于专家知识库的方法需要专家构筑的领域知识库,这需要大量专家劳动。机器学习算法需要构造特征向量形式的训练数据。然后使用各种机器学习算法,如支持向量机等作为学习机构造分类器。这种方法被称作基于特征向量的学习算法。
构造领域知识图谱,通常来说,会从大量特定类型的文本(尤其是高质量,模板化的资料)中来提取实体关系。这类文本,或者是半结构化,或者是模块格式相对明确固定的,例如上市公司公告的XBRL格式数据。这类规范化数据源,降低了信息提取的难度,大大提高了知识提取的准确度和效率。对于非结构化文本,实体识别和关系抽取需要基于NLP算法,以及深度学习算法(例如,用词向量的方式寻找近义词,提高实体模糊识别的准确度),是一个反复迭代不断精进的过程。其中,关系抽取,可以划分为确定类型的关系抽取,和不确定类型的关系抽取。确定类型的关系抽取,例如“is-a”关系,可使用语法模式抽取固定模式,使用迭代方法扩展“is-a”关系,并对生成的“is-a”进行清洗。不确定类型的关系抽取,常基于NLP将目标实体间的谓词提取出来作为候选关系,再进行下一步的筛选鉴别。
基于知识图谱的推理
基于领域知识图谱的推理,与业务场景息息相关。基于通用知识图谱的推理沿边的传递性并不强,例如精准搜索常常只用到一步到二步的推理,再往下传递时,其可信程度将会大大降低。而金融知识图谱,在充分与领域知识相结合的前提下,是可以实现长链推理的。下面列举几个推理案例:
(1)关联关系推理。基于知识图谱中公司、人之间的股东、任职等关系,可以基于聚类算法发现利益相关团体。此时,当其中若干节点发生变动或大的事件时,则可以通过沿知识图谱路径查询或子图发现等方法来计算并绘制发生变动的实体间的关联情况,帮助监管层发掘潜在的关联或违规行为,大大提高关联发现的效率。
(2)产业链关系推理。基于产业链知识图谱,可模拟经济学的涟漪效应:某产业链下游销量大涨,对整个产业链中游、上游的拉动,是非常显著的,且可以沿图谱用量化的方式建模并形成自动化推理传导模型。同样的,上游原材料成本的上涨,对于产业链中下游也可能形成链状的传导效应。这将帮助判断事件的重要程度,并即时给出事件的影响范围和程度,为各类投资决策做数据支持。
领域知识图谱选型
构建领域知识图谱底层,有相当多的选择。从传统的关系型,到NoSQL,到图;或是专一的采用一种,还是多种相结合,这些都是开始研发领域知识图谱前需要反复斟酌考虑的问题。这个问题,并没有统一的答案。的选型,需要充分考虑领域数据自身的特点(以结构化数据为主,还是非结构化数据为主),以及如何使用这些数据(比如,是否经常需要沿图谱进行推理,推理路径长短等等)。通常来说,Neo4j等图擅长长链推理,但对单位基础数据的日常维护较弱;MongoDB、HBase等NoSQL擅长处理文本类非结构化数据,对于传统数值型数据的很多处理则需要额外写代码维护;MySQL等传统,擅长处理和维护结构化数据,在面对沿图谱进行推理等应用则需要比图更多的代码量。
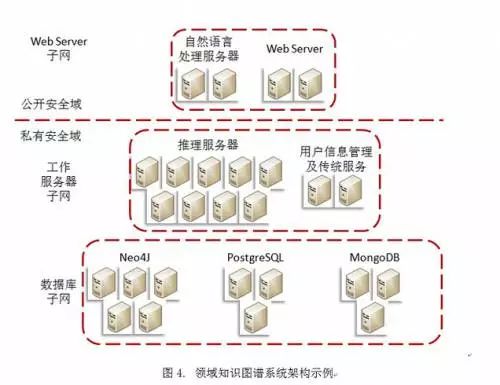
最后,从工程实现上来谈,图使用频率和相关人才储备远低于关系型,如果选用图作为主要的底层,研发团队可能经常需要面临无人可招和遇到问题搜遍网络都无帖可解的窘境,即,整个系统工期规划会难以预估。
构筑金融领域的知识图谱,是一个即有着大量结构化数据,又需要整合非结构化文本数据讯息,同时需要沿图谱进行推理的综合性项目。传统的金融数据供应商长期积累了大量结构化数据,例如价格、营收、利润、销量等数据,均为长时期时间序列格式。这与通用型知识图谱相比,呈现出很大的不同。因此,在具体的选型时,需要充分考虑未来的应用将以何种方式何种频率使用各类数据,从而打造出因地制宜的高效底层。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-67261-2.html
 js 二维数组_字符二维数组_C++二维数组new几种应用方法点评
js 二维数组_字符二维数组_C++二维数组new几种应用方法点评 在win7系统上无法全屏播放CF的问题的解决方案
在win7系统上无法全屏播放CF的问题的解决方案 Win7字体安装,教您如何在win7中安装字体
Win7字体安装,教您如何在win7中安装字体 dns被篡改?dns被篡改是什么意思?路由器dns被篡改?小心DNS地址被篡改!中国电信发布DNS安全警告
dns被篡改?dns被篡改是什么意思?路由器dns被篡改?小心DNS地址被篡改!中国电信发布DNS安全警告
时刻准备着