forkjoinpool_forkjoinpool源码分析_forkjoinpool 例子(4)
电脑杂谈 发布时间:2017-04-10 14:31:07 来源:网络整理那么到最后,所有的任务加起来会有大概2000000个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
比如,我们需要统计一个double数组中小于0.5的元素的个数,那么可以使用ForkJoinPool进行实现如下:
以上的关键是fork()和join()方法。在ForkJoinPool使用的线程中,会使用一个内部队列来对需要执行的任务以及子任务进行操作来保证它们的执行顺序。
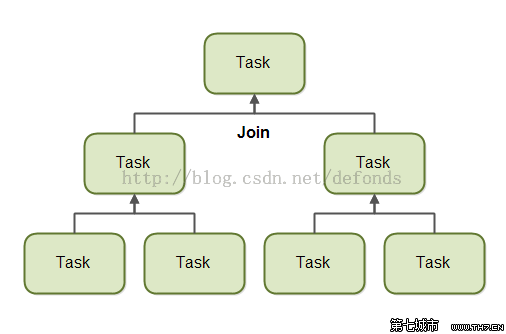
那么使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
当然,在上面的例子中,也可以不使用分治法,因为任务之间的独立性,可以将整个数组划分为几个区域,然后使用ThreadPoolExecutor来解决,这种办法不会创建数量庞大的子任务。代码如下:
在分别使用ForkJoinPool和ThreadPoolExecutor时,它们处理这个问题的时间如下:
线程数ForkJoinPoolThreadPoolExecutor
对执行过程中的GC同样也进行了监控,发现在使用ForkJoinPool时,总的GC时间花去了1.2s,而ThreadPoolExecutor并没有触发任何的GC操作。这是因为在ForkJoinPool的运行过程中,会创建大量的子任务。而当他们执行完毕之后,会被垃圾回收。反之,ThreadPoolExecutor则不会创建任何的子任务,因此不会导致任何的GC操作。
ForkJoinPool的另外一个特性是它能够实现工作窃取(Work Stealing),在该线程池的每个线程中会维护一个队列来存放需要被执行的任务。当线程自身队列中的任务都执行完毕后,它会从别的线程中拿到未被执行的任务并帮助它执行。
可以通过以下的代码来测试ForkJoinPool的Work Stealing特性:
因为里层的循环次数(j)是依赖于外层的i的的,所以这段代码的执行时间依赖于i的。当i = 0时,执行时间最长,而i = last时执行时间最短。也就意味着任务的工作量是不一样的,当i的较小时,任务的工作量大,随着i逐渐增加,任务的工作量变小。因此这是一个典型的任务负载不均衡的场景。
这时,选择ThreadPoolExecutor就不合适了,因为它其中的线程并不会关注每个任务之间任务量的差异。当执行任务量最小的任务的线程执行完毕后,它就会处于空闲的状态(Idle),等待任务量最大的任务执行完毕。
而ForkJoinPool的情况就不同了,即使任务的工作量有差别,当某个线程在执行工作量大的任务时,其他的空闲线程会帮助它完成剩下的任务。因此,提高了线程的利用率,从而提高了整体性能。
这两种线程池对于任务工作量不均衡时的执行时间:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-40527-4.html
-

-
李敬则
支持你
-
-
王涛
400w
 高端旗舰应具备什么样的系统体验?这些要点是必不可少的
高端旗舰应具备什么样的系统体验?这些要点是必不可少的 开机风扇声音大的原因及解决的方法有哪些?
开机风扇声音大的原因及解决的方法有哪些? 番茄花园Win XP旗舰版
番茄花园Win XP旗舰版 千元5G大爆炸,华为享受20 Pro首次亮相5G,流畅的屏幕和高灵敏度的夜景
千元5G大爆炸,华为享受20 Pro首次亮相5G,流畅的屏幕和高灵敏度的夜景
果断要找一个会踢球的老公呀~