一致性哈希算法232取_redis一致性哈希算法_一致性哈希算法(3)
电脑杂谈 发布时间:2017-02-06 13:16:36 来源:网络整理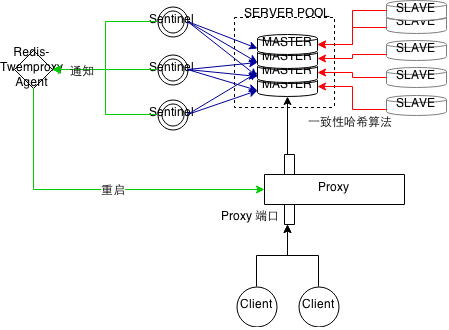
4.2.4 故障转移耗时评估
每个 Sentinel 以每秒钟发送一次PING,配置down-after-milliseconds=2s,则主观下线耗时3s
由主观下线升:数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断1s
Sentinel当选故障转移主持节点:1s
选出一个Slave节点,并将它升级为Master节点,向被选中的从服务器发送 SLEOF NO ONE 命令,让它转变为Master节点:0.5s
通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新:1s
总计耗时:6.5s
4.3 Redis Cluster
4.3.1 故障检测
节点状态的维护:
节点的拓扑结构是一张完全图:对于N个节点的Cluster,每个节点都持有N-1个输入TCP连接和N-1个输出TCP连接。
节点信息的维护:每秒随机选择节点发送PING包(无论Cluster规模,PING包规模是常量);每个节点保证在NODE_TIMEOUT/2 时间内,对于每个节点都至少发送一个PING包或者收到一个PONG包.
在节点间相互交换的PING/PONG包中有两个字段用来发现故障节点:PFAIL(Possible Fail)和FAIL。
PFAIL状态:
当一个节点发现某一节点在长达NODE_TIMEOUT的时间内都无法访问时,将其标记为PFAIL状态。
任意节点都可以将其他节点标记为PFAIL状态,无论它是Master节点还是Slave节点。
FAIL状态:
当一个节点发现另一节点被自己标记为PFAIL状态,并且在(NODE_TIMEOUT * FAIL_REPORT_VALIDITY_MULT)的时间范围内,与其他节点交换的PING/PONG包中,大部分Master节点都把该节点标记为PFAIL或者FAIL状态,则把该节点标记为FAIL状态,并且进行广播。
4.3.2 故障转移
4.3.2.1 Slave选举的时机
当某一Slave节点发现它的Master节点处于FAIL状态时,可以发起一次Slave选举,试图将自己晋升为Master。一个Master节点的所有Slave节点都可以发起选举,但最终只有一个Slave节点会赢得选举。Slave发起选举的条件:
Slave的Master处于FAIL状态
该MASTER节点存储的Key数量>0
Slave与Master节点失去连接的时间小于阀值,以保证参与选举的Slave节点的数据的新鲜度
4.3.2.2 Cluster逻辑时钟
Config epoch:
每个Master节点启动时都会为自己创建并维护configEpoch字段,设置初始值为0。Master会在自己的PING/PONG包中广播自己的configEpoch字段。Redis Cluster尽力保持各个Master节点的configEpoch字段取值都不同。算法:
每当一个Master节点发现有别的Master节点的configEpoch字段与自己相同时
并且自己的Node ID比对方小(字母顺序)
则把自己的currentEpoch+1
Slave的PING/PONG包中也包含configEpoch字段,Slave的configEpoch字段取值是它的Master的configEpoch字段取值,由最后一次与Master交换PING/PONG包时取得。
Cluster epoch:
每一个节点启动的时候都会创建currentEpoch字段,无论是Master节点还是Slave节点,并设置初始值为0。每当一个节点收到来自其他节点的PING/PONG包时,若其他节点的currentEpoch字段大于当前节点的currentEpoch字段,则当前节点把自己的currentEpoch字段设置为该到的currentEpoch值。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-30886-3.html
-

-
李景伯
在伊拉克却说你没有和交朋友得自由
 JSP基本语法(1)
JSP基本语法(1) 现代林业与生态林业 【加急写淄博可行性报告代写报告范文】
现代林业与生态林业 【加急写淄博可行性报告代写报告范文】 字符串函数---strstr()、memchr()、strchr()详解及实现
字符串函数---strstr()、memchr()、strchr()详解及实现 智能云下载4.0.1_北京云圣智能_乐视云视频智能
智能云下载4.0.1_北京云圣智能_乐视云视频智能
这就对了哟