redis一致性hash_redis双主集群部署_spring redis cache
电脑杂谈 发布时间:2017-01-25 20:04:29 来源:网络整理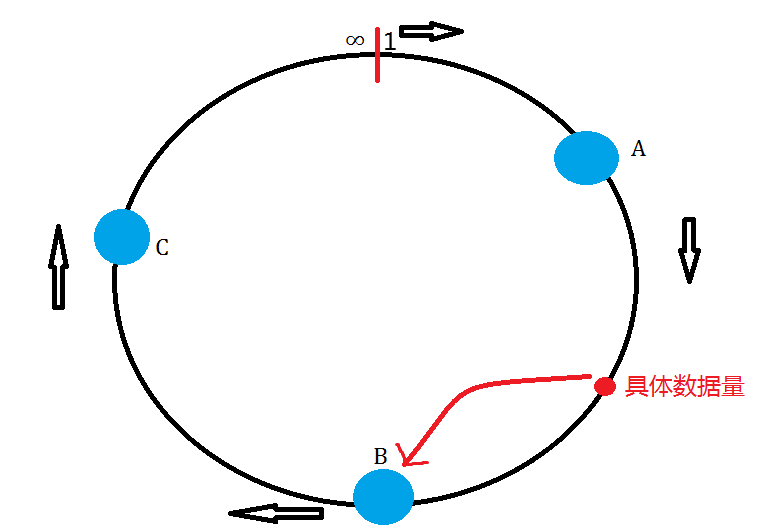
Redis 一致性hash1. 一致性hash的相关理论知识.
* http://.cnblogs.com/haippy/archive/2011/12/10/2282943.html
* http://blog.csdn.net/cywosp/article/details/23397179/
* 平衡性(Balance).平衡性是指哈希的结果能尽可能的分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
* 单调性(Monotonicity).单调性是指如果已经有一些内容通过哈希分派到相应的缓冲中,又有新的缓冲加入到系统中,哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
* 分散性(Spread).在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲中时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的算法应该尽量避免不一致的情况发生,也就是尽量降低分散性。
* 分散性(Load).负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
* 平滑性(Smoothness).平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
`
public class ConsistentHash {
private SortedMap<Long,String> ketamaNodes=new TreeMap<Long,String>();
private int numberOfReplicas=1024;
private HashFunction hashFunction= Hashing.md5(); //guava
private List<String> nodes;
private volatile boolean init=false; //标志是否初始化完成
public ConsistentHash(int numberOfReplicas,List<String> nodes){
this.numberOfReplicas=numberOfReplicas;
this.nodes=nodes;
init();
}
public String getNodeByKey(String key){
if(!init)throw new RuntimeException("init uncomplete...");
byte[] digest=hashFunction.hashString(key, Charset.forName("UTF-8")).asBytes();
long hash=hash(digest,0);
//如果找到这个节点,直接取节点,返回
if(!ketamaNodes.containsKey(hash)){
//得到大于当前key的那个子Map,然后从中取出第一个key,就是大于且离它最近的那个key
SortedMap<Long,String> tailMap=ketamaNodes.tailMap(hash);
if(tailMap.isEmpty()){
hash=ketamaNodes.firstKey();
}else{
hash=tailMap.firstKey();
}
}
return ketamaNodes.get(hash);
}
public synchronized void addNode(String node){
init=false;
nodes.add(node);
init();
}
private void init(){
//对所有节点,生成numberOfReplicas个虚拟节点
for(String node:nodes){
//每四个虚拟节点为1组
for(int i=0;i<numberOfReplicas/4;i){
//为这组虚拟结点得到惟一名称
byte[] digest=hashFunction.hashString(nodei, Charset.forName("UTF-8")).asBytes();
//Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因
for(int h=0;h<4;h){
Long k = hash(digest,h);
ketamaNodes.put(k,node);
}
}
}
init=true;
}
public void printNodes(){
for(Long key:ketamaNodes.keySet()){
System.out.println(ketamaNodes.get(key));
}
}
public static long hash(byte[] digest, int nTime)
{
long rv = ((long)(digest[3 nTime * 4] & 0xFF) << 24)
| ((long)(digest[2 nTime * 4] & 0xFF) << 16)
| ((long)(digest[1 nTime * 4] & 0xFF) << 8)
| ((long)digest[0 nTime * 4] & 0xFF);
return rv;
}
}
`
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-28693-1.html
相关阅读
发表评论 请自觉遵守互联网相关的政策法规,严禁发布、暴力、反动的言论
每日福利
 光标阅读机驱动程序的原理最常见的是网络传输
光标阅读机驱动程序的原理最常见的是网络传输 内连接+自然连接有问题,上知乎。知乎是中文互联网知名知识分享
内连接+自然连接有问题,上知乎。知乎是中文互联网知名知识分享 乐小宝故事光机_乐小宝怎么看电视_乐小宝1s和1区别
乐小宝故事光机_乐小宝怎么看电视_乐小宝1s和1区别 解决办法:win7在桌面上创建宽带连接快捷方式的方法
解决办法:win7在桌面上创建宽带连接快捷方式的方法热点图片
你先合着找一个