mapreduce的工作原理_mapreduce实例_mapreduce和hadoop区别
电脑杂谈 发布时间:2017-01-25 11:51:48 来源:网络整理前言:
MapReduce是一种编程模型,用于数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键对映射成一组新的键对,指定并发的Reduce(归约)函数,用来保证所有映射的键对中的每一个共享相同的键组。
呵呵,下面我们进入正题,这篇文章主要分析以下两点内容:
目录:
1.MapReduce作业运行流程
2.Map、Reduce任务中Shuffle和排序的过程
正文:
1.MapReduce作业运行流程
下面贴出我用visio2010画出的流程:
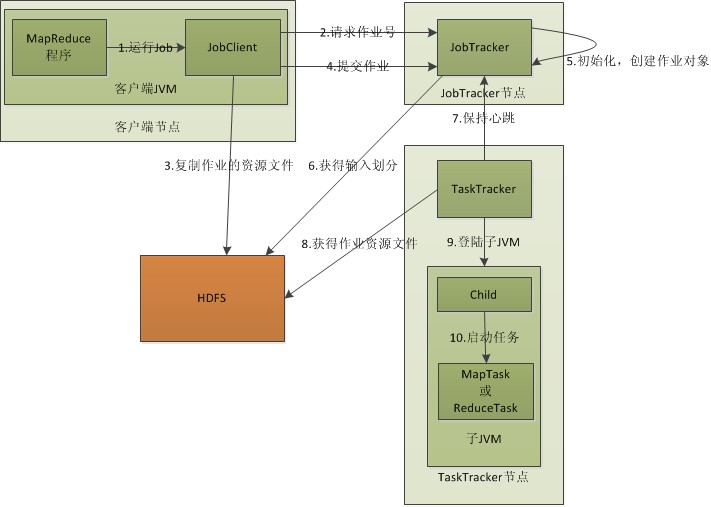
流程分析:
1.在客户端启动一个作业。
2.向JobTracker请求一个Job ID。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢,呵呵),当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
5.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
2.Map、Reduce任务中Shuffle和排序的过程
同样贴出我在visio中画出的流程:
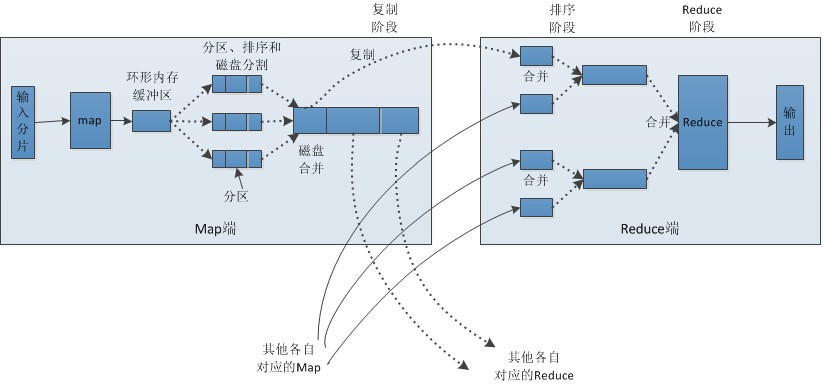
流程分析:
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-28657-1.html
-

-
颜仁郁
不一样的感觉
-
魏祎
降息不会对股市产生任何作用
 苹果电脑能不能安装Windows10系统?答案在这里
苹果电脑能不能安装Windows10系统?答案在这里 面向对象的程序设计和面向过程的程序设计之间的区别
面向对象的程序设计和面向过程的程序设计之间的区别 被忽略的移动闪存性能UFS和eMMC有什么区别?
被忽略的移动闪存性能UFS和eMMC有什么区别? 2016新编Mysql存储过程中临时表的构建及游标遍历.doc
2016新编Mysql存储过程中临时表的构建及游标遍历.doc
你统计过双方伤亡数字吗