Hadoop内部技术: 阅读MapReduce架构设计和实现原理的深入分析(2)
电脑杂谈 发布时间:2020-07-15 16:29:42 来源:网络整理(1)客户
用户编写的MapReduce程序通过客户端提交给JobTracker;同时,用户可以通过客户端提供的某些界面查看作业的运行状态. 在Hadoop中,“作业”用于表示MapReduce程序. 一个MapReduce程序可以对应多个作业,每个作业将分解为多个Map / Reduce任务(任务).
(2)JobTracker
JobTracker主要负责资源监视和作业调度. JobTracker监视所有TaskTracker和作业的运行状况. 一旦发现故障,它将把相应的任务转移到其他节点. 同时,JobTracker将跟踪任务执行的进度,资源使用情况和其他信息,并将此信息通知任务调度. 调度程序将选择适当的任务以在资源空闲时使用这些资源. 在Hadoop中,任务计划程序是一个可插入模块,用户可以根据自己的需求设计相应的计划程序. (3)TaskTracker
TaskTracker会通过Heartbeat定期向JobTracker报告节点上资源的使用情况和任务的进度,同时接收JobTracker发送的命令并执行相应的操作(如启动新任务,终止任务等). TaskTracker使用“插槽”来划分此节点上的资源量. “插槽”代表计算资源(CPU,内存等). 任务获得插槽后才有机会运行,并且Hadoop调度程序的作用是将每个TaskTracker上的空闲插槽分配给该任务以供使用. 插槽分为两种类型: 映射插槽和缩小插槽,分别由“映射任务”和“缩小任务”使用. TaskTracker通过插槽数(可配置参数)限制Task的并发性.
(4)任务
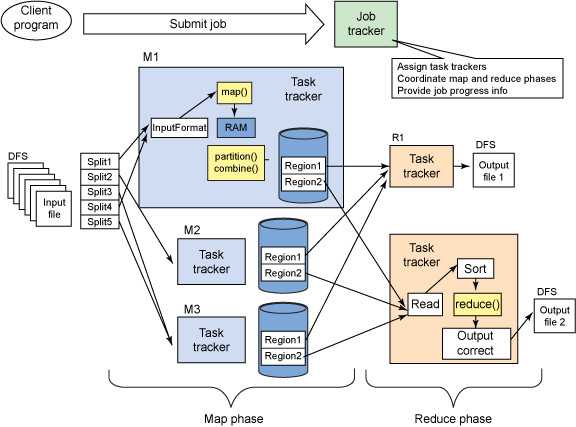
任务分为两种类型: 映射任务和归约任务,均由TaskTracker启动. 从上一节我们知道,HDFS使用固定大小的块作为存储数据的基本单位,而对于MapReduce,则拆分处理单位. 拆分和块之间的对应关系如图2-6所示. 拆分是一个逻辑概念. 它仅包含一些元数据信息,例如数据的起始位置,数据的长度以及数据所在的节点. 其划分方法完全由用户决定. 但应注意,拆分的数量决定了Map Task的数量,因为每个拆分将由Map Task处理.
图2-6拆分和块之间的对应关系
“映射任务”执行过程如图2-7所示. 从图中可以看出,Map Task首先迭代地将相应的拆分解析为键/值对,然后调用用户定义的map()函数进行处理,最后将临时结果存储在本地磁盘上,临时数据分为几个分区,每个分区都将由Reduce任务处理.
图2-7映射任务执行过程Reduce任务执行过程如图2-8所示. 该过程分为三个阶段: ①从远程节点读取Map Task的中间任务(称为“ Shuffle阶段”); ②根据键对键/值对进行排序(称为“排序阶段”); ③依次读取<键,值列表>,调用用户定义的reduce()函数进行处理,并将最终结果存储在HDFS(称为“还原阶段”)上.
图2-8Reduce任务执行流程2.5 Hadoop MapReduce作业生命周期
因为本书使用“作业生命周期”作为分析Hadoop MapReduce架构设计和实现原理的线索,所以在深入研究每个MapReduce实现的细节之前了解作业的整个生命周期非常重要. 为此,本节主要说明Hadoop MapReduce作业的生命周期,即从提交到操作结束的整个工作过程. 本节仅简要介绍MapReduce作业的生命周期,可以将其视为后续各章内容的指南. 在后续章节中将对工作生命周期中的特定阶段进行深入分析.
假设用户已经编写了MapReduce程序并将其打包到xxx.jar文件中,然后使用以下命令提交作业:
$ HADOOP_HOME / bin / hadoop jar xxx.jar \
-D mapred.job.name =“ xxx” \
-D mapred.map.tasks = 3 \
-D mapred.reduce.tasks = 2 \
-D输入= /测试/输入\
-D输出= /测试/输出
此作业的操作过程如图2-9所示.
图2-9 Hadoop MapReduce作业生命周期
此过程分为以下5个步骤:
第1步作业提交和初始化. 用户提交作业后,JobClient实例首先将与作业相关的信息(例如程序jar包,作业配置文件和碎片元信息文件等)上载到分布式文件系统(通常为HDFS),碎片元信息文件记录每个输入切片的逻辑位置信息. 然后JobClient通过RPC通知JobTracker. JobTracker收到新的作业提交请求后,作业调度模块将初始化作业: 为作业创建JobInProgress对象以跟踪作业的运行状态,JobInProgress为每个Task创建TaskInProgress对象以跟踪每个任务的运行状态TaskInProgress可能需要管理多个“任务运行尝试”(称为“任务尝试”). 具体分析请参见第5章.
第2步任务计划和监视. 如前所述,作业调度和监视功能全部由JobTracker完成. TaskTracker会通过心跳定期向JobTracker报告此节点的资源使用情况. 一旦出现空闲资源,JobTracker将根据特定策略选择合适的任务来使用空闲资源. 这是由任务计划程序完成的. 任务计划程序是可插拔的独立模块,具有两层体系结构,即首先选择一个作业,然后再从该作业中选择一个任务. 其中,选择任务时需要考虑数据局部性. 此外hadoop运行mapreduce作业的工作原理,JobTracker跟踪作业的整个运行过程,并为作业的成功运行提供全面的保证. 首先,当TaskTracker或Task失败时,将传输计算任务;其次,当一个任务的执行进度远远落后于同一作业的其他任务时,为其启动相同的任务,然后选择快速计算的任务结果作为最终结果. 具体分析请参见第6章.
第3步任务操作环境准备. 操作环境的准备包括JVM启动和资源隔离,所有这些都由TaskTracker实施. TaskTracker为每个任务启动一个独立的JVM,以防止不同的任务在运行期间相互影响. 同时,TaskTracker使用操作系统进程来实现资源隔离,以防止Task滥用资源. 具体分析请参见第7章.
第4步任务执行. TaskTracker为Task准备好运行环境后,它将启动Task. 在操作过程中,每个任务的最新进度首先由任务通过RPC报告给TaskTracker,然后由TaskTracker报告给JobTracker. 具体分析请参见第8章.
第5步完成. 完成所有任务后,整个作业将成功执行.
2.6总结Hadoop MapReduce直接诞生于搜索领域,以易于编程,良好的可伸缩性和较高的容错性为设计目标.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-281369-2.html
-

-
林雪梅
-
刘学智
 Win10技巧利用无线路由组建无线局域网【图文攻略】
Win10技巧利用无线路由组建无线局域网【图文攻略】 windows线程同步_同步结束线程mfc_windowsthread睡眠
windows线程同步_同步结束线程mfc_windowsthread睡眠 风林火山xp纯净版最新免费下载安装教程(组图)
风林火山xp纯净版最新免费下载安装教程(组图) 小白系统64位win7安装版本系统下载
小白系统64位win7安装版本系统下载
还可以合伙用你老婆