数据结构研究notes_tree(二进制搜索树,B树,B +树,B *树)
电脑杂谈 发布时间:2020-07-10 21:19:23 来源:网络整理
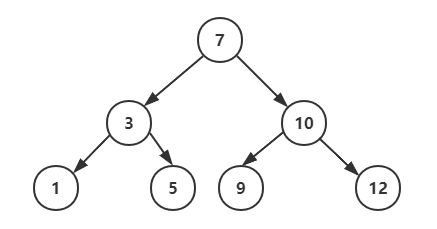
1. 发现二叉树的性质
1). 所有非叶节点最多有两个儿子(左和右);
2). 所有节点都存储一个关键字;
3). 非叶节点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
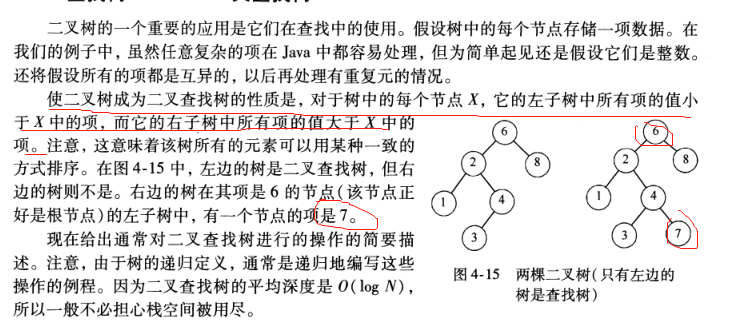
2. 包含方法
如果树T包含节点X,则返回true,如果该节点不存在,则返回false(并在左侧或右侧子树中递归调用);
3.findMin和findMax方法
finMin是从根节点到左子节点执行的,递归调用,终点是最小的元素;
findMax是从根节点到右子执行的,递归调用,终点是最大元素;
3.insert方法
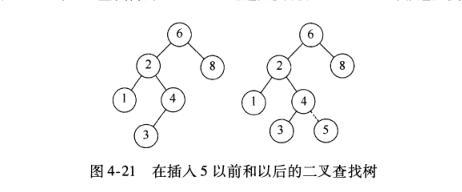
例如,要将5插入左上方的树,只需找到4,然后继续向右,但是右边没有子树,因此5的插入位置在这里
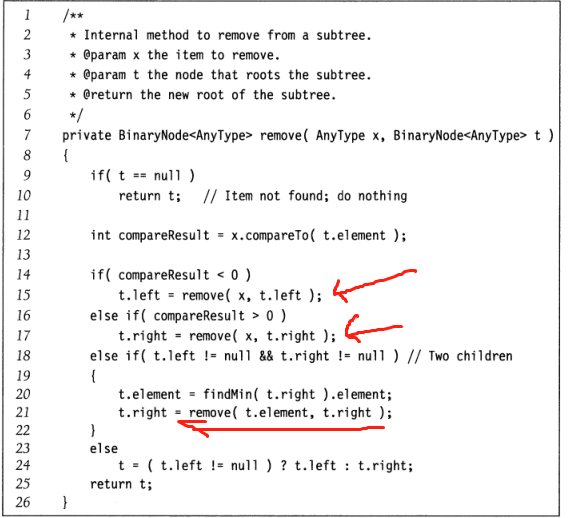
4. 找到要删除的二叉树(最困难)
1. 该节点是叶子(无子),并且立即删除;
2. 该节点只有一个子节点,并且绕过子节点后删除了父节点,如下面的左图所示;
3. 该节点有两个儿子. 一般的删除策略是用其右侧子树的最小数据替换节点的数据(参见下图,从右侧子树5中找到最小数字3而不是2),然后递归删除该节点(例如,交换后的节点2). 因为右子树的最小节点不能有左子;

删除步骤如下:
5. 平均深度
一棵树上所有节点的深度称为内部路径长度,

6. 优缺点
如果二叉查找树的所有非叶节点的左右子树的数量保持相同(平衡),则B树的搜索性能接近二叉查找;
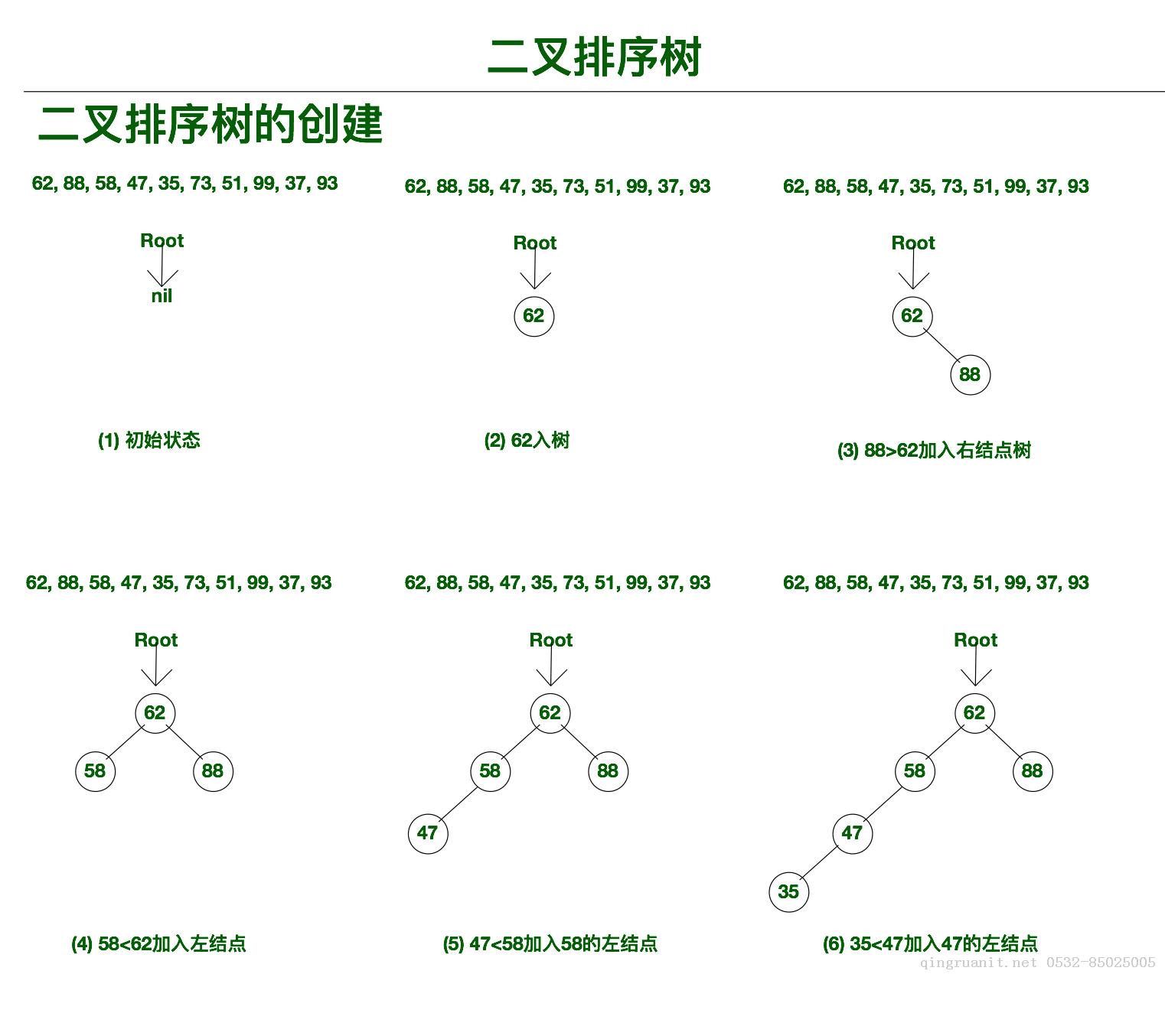
但是在连续的存储空间中,它比二进制搜索的优势在于,更改二进制搜索树的结构(插入和删除节点)不需要移动很大一部分内存数据,甚至不需要固定开销;
二进制搜索树的多次插入和删除后,可能会导致结构不同: 如下所示
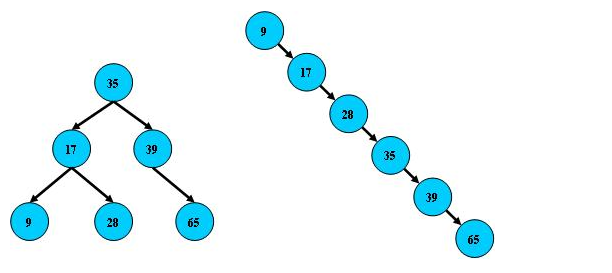
查找具有平衡条件的二叉树. 一个AVL树,每个节点的左右子树最多相差1(空树的节点为-1).
实际使用的二进制搜索树基于原始的二进制搜索树加上平衡算法,即“平衡的二进制树”;
如何保持B树节点的平衡分布是平衡二叉树的关键;平衡算法是一种在二叉搜索树中插入和删除节点的策略;
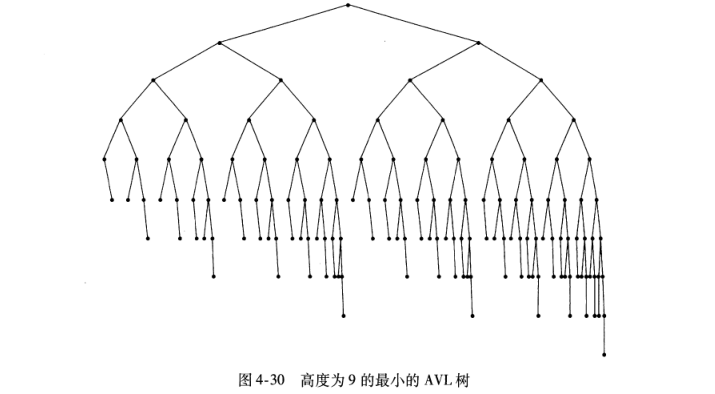
常用算法包括红色和黑色树,AVL,Treap,拉伸树等. 在平衡二叉树中,我们可以看到其高度通常保持在O(log2n),大大降低了操作的时间复杂度.
调整平衡的基本思路:
在二进制分类树中插入节点时,首先检查余额是否由于插入而损坏. 如果损坏,则在其中找到最小的不平衡二叉树,并在保持二进制分类树特征的同时对其进行调整. 最小不平衡子树中的节点之间的关系将达到新的平衡.
所谓的最小不平衡子树是指最接近插入节点并以平衡因子的绝对值大于1的节点为根的子树.
首先插入指定的节点,并记录当前节点LH,EH或RH的信息.
1. 如果左子树为高LH,请检查左子树的根节点信息. 如果是LH,它将向右转一次;如果是RH,它将向左转一次+向右转一次
2. 如果右子树的RH高,请检查右子树的根节点信息. 如果是RH,请向左转一次;如果是LH,请向右转一次,然后向左转一次
3. 调整更改后的节点信息
追求绝对的高度平衡,随着树的高度增加,动态插入和删除的成本也增加了
三棵B树(B树)
B树是B树,B是平衡的,这意味着平衡. 因为B树的原始英文名称是B树,而且中国很喜欢将B树翻译为B树,所以实际上这是一个很不好的直译,很容易引起误解.
例如,人们可能会认为B树是一种树,而B树是另一种树. 实际上,B树是指B树. 特此说明.
B树是一种自平衡树,可以使数据保持有序. 通过这种数据结构,可以在对数时间内查找数据,顺序访问,插入数据和删除所有数据.
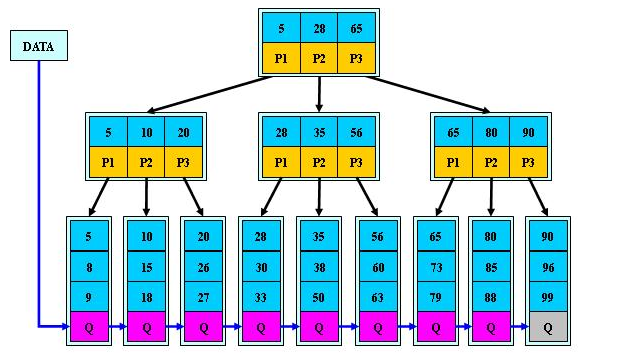
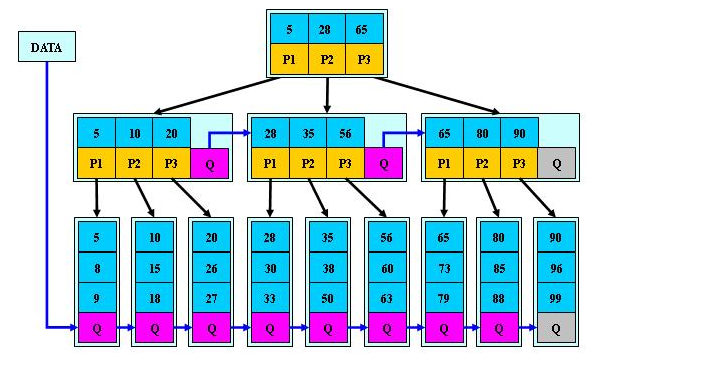
1. B树是多路径搜索树(不是二叉树,下面是M阶的B树):
1). 定义任何非叶节点最多具有M个子;和M> 2;
2). 根节点的子节点数为[2,M];
3). 根节点以外的非叶节点的子节点数为[M / 2,M];
4). 每个节点至少存储M / 2-1(取整),最多存储M-1个关键字. (至少2个关键字)

5). 非叶子节点关键字的数量=指向子-1的指针的数量; (此处关键字用数字表示,指针用P表示)
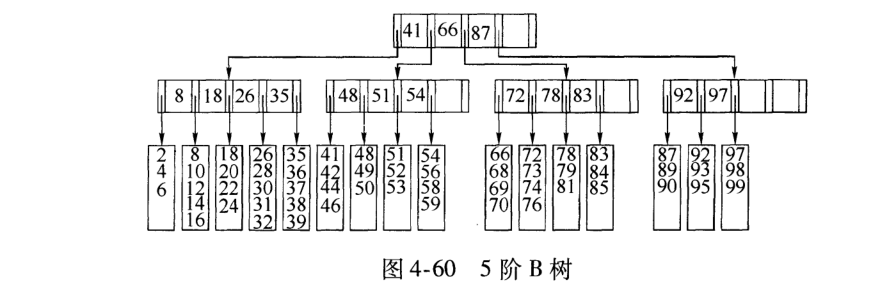
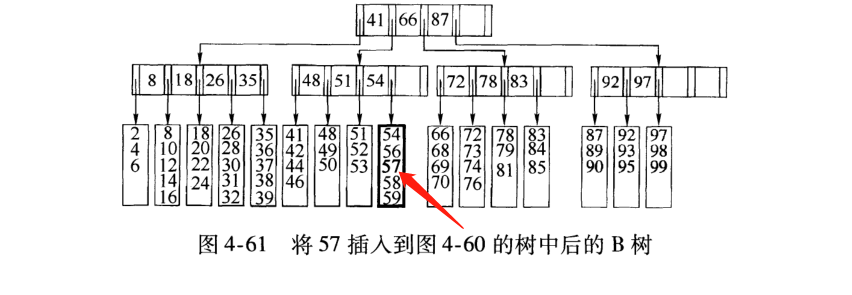
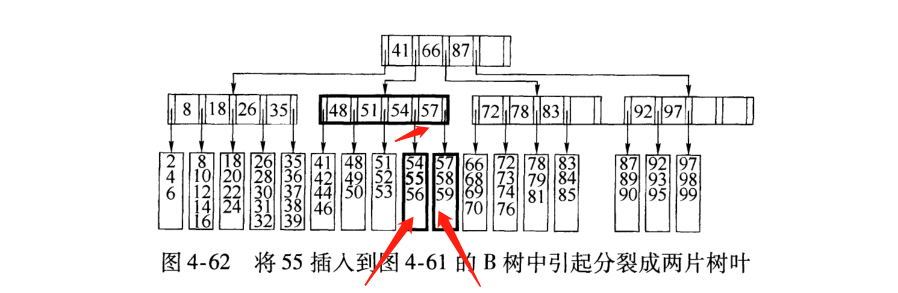
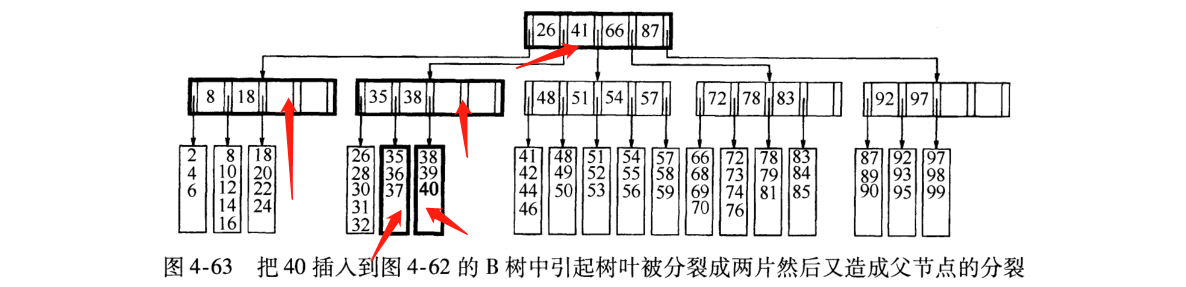
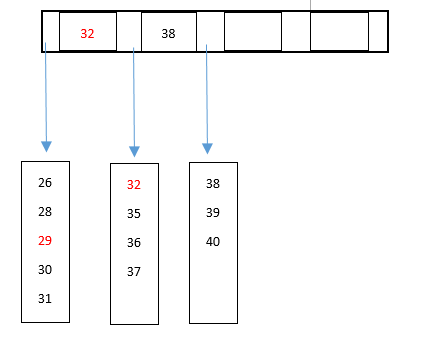
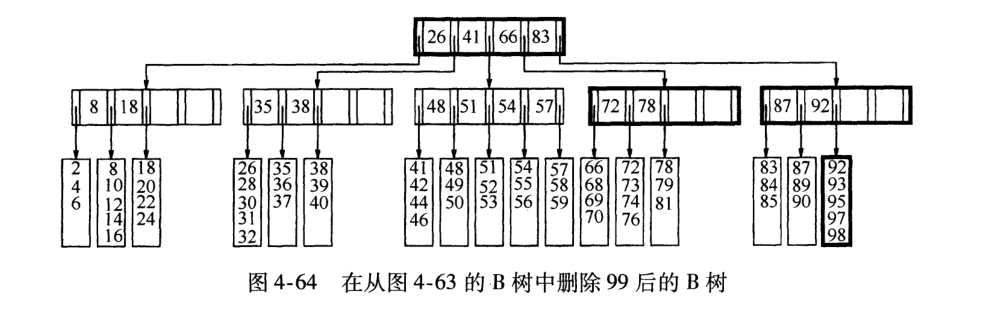
6). 非叶节点的关键字: K [1],K [2],…,K [M-1];并且K [i] 7). 指向非叶子节点的指针: P [1],P [2],…,P [M];其中P [1]指向键小于K [1]的子树,P [M]指向键大于K [M-1]的子树,其他P [i]指向其键的子树键属于(K [i-1],K [i]); (例如,根节点P1指向的左子树小于K [1] = 17〜) 8). 所有叶节点都在同一层上;例如: (M = 3) 2. B树搜索 从根节点开始,对节点内的关键字(有序)序列进行二进制搜索,如果命中,则结束,否则输入查询关键字所属范围的子节点;重复直到相应的子指针为空,或者已经是叶节点; 3. B树的特征 1). 关键字集分布在整个树中; 2). 任何一个关键字仅出现在一个节点中; 3). 搜索可能会在非叶子节点结束; 4). 其搜索性能相当于在完整的关键字集中进行二进制搜索; 5). 自动电平控制; 4. 搜索效果 由于限制了除根节点以外的非叶子节点,因此至少包括M / 2个子节点,这确保了该节点的最低利用率,并且其底部搜索性能为: 其中M是非叶子节点的最大数量,N是关键字的总数; 因此,B树的性能始终等同于二叉搜索(与M值无关),因此,B树平衡没有问题; 由于M / 2的限制,在插入一个节点时,如果该节点已满,则需要将该节点拆分为两个分别占据M / 2的节点. 删除节点时,两个少于M / 2个兄弟节点合并; 四棵B +树 1. B +树是B树和多路径搜索树的变体: 1). 其定义与B树基本相同,除了: 2). 非叶子节点的子树指针的数量与关键字的数量相同; 3). 非叶节点子树指针P [i],它指向其键值属于[K [i],K [i + 1])的子树(B树是一个开放区间,B +是Left open right close) ; 5). 向所有叶节点添加一个链指针; 6). 所有关键字都出现在叶节点上;例如: (M = 3) 2. B +搜索和查询 它与B树基本相同. 区别在于B +树仅击中叶节点(B树可击中非叶节点),其性能等同于在完整的关键字集中进行二进制搜索; 3. B + 的特征 1). 所有关键字都出现在叶节点的链接列表(密集索引)中,而链接列表中的关键字恰好是按顺序排列的; 2). 不可能击中非叶子节点; 3). 非叶节点相当于叶节点的索引(稀疏索引),叶节点相当于存储(关键字)数据的数据层; 4). 更适合文件索引系统; NTFS,ReiserFS,NSS,XFS二叉排序树+数据结构,JFS,ReFS和BFS之类的文件系统都使用B +树作为元数据索引. B +树的特点是可以保持数据稳定有序,其插入和修改具有相对稳定的对数时间复杂度. B +树元素从下至上插入. 4. 插入B + 1)将上面图4-60的5阶B树插入57. 观察到54指向的叶子只有4个数据未填充状态,可以直接添加. (叶子底部填充插件) 2)继续插入55,(也门插入) 以上叶子可以看到有5个已满,无法继续插入. 解决方法是再次拆分父节点,然后拆分由54 + 1新插入的数据55指向的5个叶子. 此处的IO操作至少具有原始叶数据更新,新叶数据更新和新父节点57更新. 3)继续插入40(Yeman和Manman插入) 在上图中,有5个由35指向的叶子,并且父节点(full)无法拆分,此处采用的方法是继续到拆分节点的上一层. 如果将根拆分,则不能再将根拆分为两个根,可以创建一个新的根,作为根的两个儿子,这是增加B树的高度的唯一方法. 4)继续插入29(邻居收养了太多儿子) 如果在左侧放置35片叶子,则将有6片叶子,那么您可以为右侧的叶子分配一个数据以采用(右侧的3个数据) 5)删除99(领养父亲) 如果删除99,则由92和97,98指向的叶子将合并为一个叶子,从而导致父节点的子节点低于最小值. (97个父节点被杀死) 解决方法是: 从邻居的父节点中选取一个,将平均72-78-83-92分成两个父节点,这当然会调整上一级父节点〜 五棵B *树 它是B +树的变体. 在B +树的非根和非叶节点上添加指向Brother的指针; B *树定义非叶子节点关键字的数量至少为(2/3)* M,即,该块的最小使用率为2/3(而不是B +的1/2)树); B +树拆分: 当一个节点已满时,分配一个新节点,并将原始节点数据的1/2复制到新节点,最后将新节点添加到父节点Pointer; B +树的拆分只会影响原始节点和父节点,而不会影响同级节点,因此它不需要指向同级节点的指针; B *树拆分: 当一个节点已满时,如果它的下一个同级节点未满,则将部分数据移至同级节点,在原始节点中插入关键字,最后修改父节点. 点中兄弟节点的位置(因为兄弟节点的关键字范围已更改);如果兄弟节点也已满,则在原始节点和兄弟节点之间添加一个新节点,并将数据的1/3复制到新节点,最后将新节点的指针添加到父节点;
因此,B *树分配新节点的可能性低于B +树,并且空间利用率更高; 六. 摘要 二叉搜索树: 二叉树,每个节点仅存储一个关键词,等于命中数,小于左节点,大于右节点; B(B-)树: 多向搜索树,每个节点存储M / 2至M个关键字,非叶节点存储指向关键字范围的子节点;所有关键字都在整个树中只出现一次,非叶子节点可以被击中; B +树: 在B树的基础上,向叶节点添加一个列表指针,所有关键字均出现在叶节点中,并且非叶节点用作叶节点的索引; B +树总是到达叶节点击中该点; B *树: 在B +树的基础上,还为非叶节点添加了列表指针,该节点的最低利用率从1/2增加到2/3; VII. 问题 1. 为什么B +树比B树更适合实际应用中操作系统的文件索引和索引? B +树磁盘的读写成本较低 B +树的内部节点没有指向关键字特定信息的指针. 因此,其内部节点小于B树. 如果同一内部节点的所有关键字都存储在同一磁盘块中,则该磁盘块可以容纳的关键字更多. 需要立即搜索到内存中的更多关键字. 相对而言,减少了IO的读写次数. 例如,假设磁盘中的磁盘块容纳16个字节,关键字2个字节,关键字特定信息指针2个字节. 一个9层的B树(每个节点最多8个关键字)需要2个磁盘. 但是,B +树的内部节点只需要1个磁盘即可. 当需要将内部节点读入内存时,B树的磁盘块搜索时间比B +树的磁盘块搜索时间多(在磁盘中,这是磁盘旋转的时间). B +树查询效率更稳定 因为非终结点不是最终指向文件内容的节点二叉排序树+数据结构,而是仅叶子节点中关键字的索引. 因此,任何关键字搜索都必须采用从根节点到叶节点的路径. 所有关键字查询的路径长度都相同,因此每个数据的查询效率相同.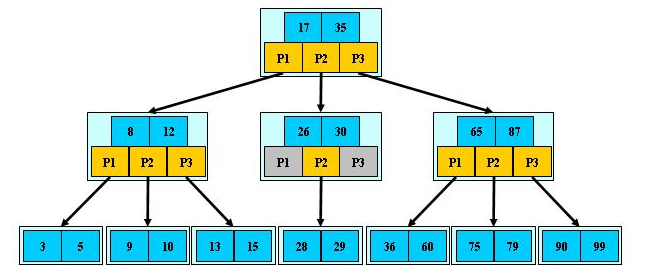
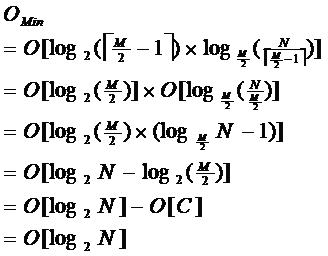

本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-275738-1.html
-

-
越王
所以盲目乐观要倒霉
-
文丙
超期待
 如何打开win7笔记本电脑相机?调用笔记本电脑相机的方法有两种:
如何打开win7笔记本电脑相机?调用笔记本电脑相机的方法有两种: 陶飞
陶飞 HTML注释
HTML注释 操作方法:为什么在安装和启动ASUS软件时会弹出Windows安全警报?
操作方法:为什么在安装和启动ASUS软件时会弹出Windows安全警报?
甚至一天半的