搜索引擎的工作原理(爬虫索引查询显示技术)| SEO优化的事物
电脑杂谈 发布时间:2020-07-03 18:19:56 来源:网络整理
昨天的文章“对全球化的误解,本地化的机会”在评论中说,有人说搜索引擎技术似乎不需要本地化. 这是不了解该领域的人所说的. 当然,老实说,如果有人说google在中文本地化方面做得很好,我可以部分同意同意的百分比可能少于google工程师. 但是我相信Google工程师还会告诉您,搜索引擎需要本地化.
今天写一篇热门文章,谈谈搜索引擎的技术机制和市场竞争的一些特征. 当然,作为从事交通运营或对交通运营感兴趣的朋友,您可以使用另一种观点来理解本文.
搜索引擎的核心技术架构通常包括以下三个部分. 首先是蜘蛛/爬行动物技术;第二是索引技术;第三是查询显示技术;当然,我不是搜索引擎架构师,只能使用相对浅薄的方法进行结构细分.

1. 蜘蛛(又称爬行动物)是一种用于捕获和存储Internet信息的技术实现.
搜索引擎的信息收集,很不清楚,所以很会产生很多误会,认为它是付费收录的,或者是其他任何特殊的提交技巧. 实际上,并不是搜索引擎通过Internet上一些著名的网站来爬网内容. ,然后分析链接,然后有选择地获取链接的内容,然后分析链接,依此类推,通过有限的入口,基于彼此的链接,形成强大的信息爬网能力.
某些搜索引擎也具有链接提交门户,但基本上,它不是主要的入口门户. 但是,作为企业家,建议检查相关信息. 百度和谷歌都有网站管理员平台和管理背景. 这里需要很多内容. 非常非常认真地对待它.
相反,根据此原则,只有与其他网站链接的网站才能被搜索引擎抓取. 如果此网站没有外部链接,或者在搜索引擎中外部链接被视为垃圾邮件或无效链接,则搜索引擎可能无法抓取其页面.
分析并确定是否只能通过服务器上的访问日志来查询搜索引擎是否已对您的页面进行爬网,或何时对您的页面进行爬网,如果这是麻烦的话. 但是基于网站嵌入代码的方式(无论是cnzz,百度统计信息还是Google Analytics(分析)),都不可能获得Spider抓取的信息,因为该信息不会触发这些代码的执行.
推荐的日志分析软件是awstats.
十多年前,分析百度蜘蛛的爬行轨迹和更新策略是许多基层网站管理员必须做的. 例如,当年一家知名的80年代后上市公司的价值数十亿美元. 长期论坛基于准确的分析和判断,在长期存在的圈子中已成为一代偶像.
但是基于链接爬网,蜘蛛的主题不是那么简单,让我们对其进行扩展
首先,网站所有者可以选择是否允许蜘蛛抓取,其中有一个robots.txt文件来控制.
一个经典案例是
您会看到,淘宝网中仍然有一些关键目录,这些目录对百度蜘蛛不开放,但对谷歌开放.
另一个经典案例是
您看到了什么?您可能看不到任何东西,我提醒您,百度实质上禁止了360蜘蛛爬行.
但是,该协议只是一个约定,实际上并没有约束力,所以请猜猜360符合百度的蜘蛛爬行禁令吗?
第二,最早的爬网基于站点之间的链接,但实际上,例如,不确定是否可能存在其他爬网入口,
客户端插件或浏览器,免费网站统计系统的嵌入式代码.
它将成为蜘蛛爬行的入口吗?我只能说有可能.
因此,我告诉许多企业家,如果中国有一个网站,百度统计,海外网站和Google Analytics(分析),它会增加搜索引擎对您网站的覆盖吗?我只能说有可能.
第三,无法抓取的信息
某些网站的内容链接具有一些特殊的javascript效果,例如浮动菜单等. 搜索引擎蜘蛛程序可能无法识别此连接. 当然,我只是说有可能. 现在,搜索引擎比以前更强大. 聪明,很多特殊效果链接都在十多年前被人们认可,现在会更好.
需要登录和注册才能由蜘蛛访问的页面无法访问,也就是说,不能包含这些页面.
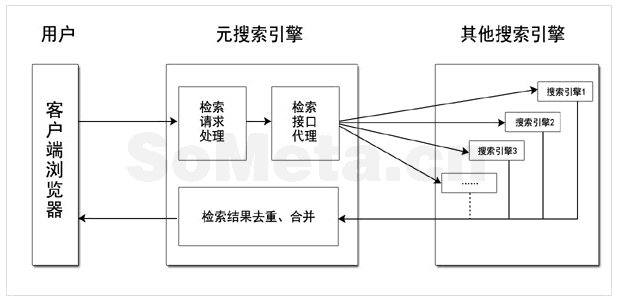
某些网站会搜索特殊页面,即蜘蛛可以看到内容(蜘蛛访问将具有特殊的客户端标签,服务器标识和处理并不复杂),人们需要登录才能看到,但是要这样做实际上,它违反了包含协议(要求人们和蜘蛛看到相同的内容,这是大多数搜索引擎的包含协议),并且可能会受到搜索引擎的惩罚.
因此,如果社区希望通过搜索引擎吸引免费用户,则访问者必须能够看到内容,甚至是其中的一部分.
具有许多复杂参数的内容链接URL可能被蜘蛛视为重复页面,并拒绝包含.
许多动态页面反映在带有参数的脚本程序中,但是蜘蛛程序会在同一脚本中找到包含大量参数的网页. 有时会给网页的价值评估带来麻烦. 蜘蛛可能会认为此网页是重复页面. 并拒绝被列入. 再次,随着技术的发展,蜘蛛在识别动态脚本的参数方面取得了长足的进步,现在基本上可以忽略这个问题了.
但是,这催生了一种称为伪静态化的技术. 通过配置Web服务器以允许用户访问页面,URL格式看起来像是静态页面. 实际上,它之后是常规比赛. 实际执行是动态脚本.
许多社区论坛为了追求免费搜索而进行了伪静态处理. 十多年前,这几乎是草根网站管理员的一项基本技能.
搜寻器技术暂时存在,但这里要强调的是存在外部链接,这并不意味着搜索蜘蛛将开始搜寻. 如果搜索蜘蛛爬行,并不意味着将包括搜索引擎;如果包含搜索引擎,并不意味着用户可以搜索;
网站语法是用于检查网站条目数的最基本的搜索语法. 我开始认为这是abc常识. 直到在新加坡接受了一些创业培训后,我才发现大多数刚进入这个行业或对进入这个行业感兴趣的人都不了解.
例如,百度搜索网站: yangfenzi.com
2. 索引系统
蜘蛛正在抓取网页的内容,因此,如果希望用户通过关键字快速搜索网页,则必须为网页关键字建立索引以提高查询效率. 简而言之,根据网页中这些关键词的出现频率,位置,特殊标签和其他因素,提取关键词并赋予它们不同的权重,然后将其存储在索引库中.

然后问题来了,关键字是什么.
用英语,例如这是一本书,用中文,这是一本书.
英语自然是四个词,空格是自然分词. 那中文呢?您不能将句子用作关键字(如果您将句子用作关键字,那么当您搜索某些信息时,就无法为点击量编制索引. 例如,如果您搜索书籍,则可以找不到它,这显然与搜索引擎要求不符). 因此,我们需要对单词进行细分.
一开始,最简单的想法是每个单词都被切掉. 这曾经被称为单词索引. 每个单词都被编入索引并标有位置. 如果用户搜索关键字,则该关键字也会拆分为单词. 搜索然后合并结果,但这就是问题所在.
例如,当搜索关键字“ seafood”时,将显示结果“ Shanghai Flowers”,这显然不是应该的搜索结果.
例如,当搜索关键字“和服”时,将显示结果,开关和服务器.
这些是Google无法在野外生存的问题.
直到有茎,别笑,这些是流血的茎,在半夜打电话给我,并说网站管理员通过搜索发现您社区中存在淫秽内容,并且必须删除,否则您将关闭您的网站,在夜间醒来并认真调查,一百个令人难以置信,我恳求提供信息线索,最后发现有人发送了一个小广告,“购买二十四次交流”. 另外,由于怀疑是政治敏感人物,最终找到了“提供三台独立服务器”,您能在其中看到敏感的字眼吗?你说没错. 这两个故事可能并不正确搜索引擎原理和技术系统,因为它们都是在网上看到的,但是我想说的是,存在着这样的事情,并不是所有事情都是没有根据的.
因此,分词是许多亚洲语言需要额外处理的东西,但西方语言没有问题.
但是分词不是那么简单地谈论,例如几点,1: 如何识别一个人的名字? 2.如何在互联网上识别新单词?例如,“无意识”. 3.中英文坑,例如QQ表达式.
最后构建一个分词系统并不难,但是在技术上进行自动学习,与时俱进并成为高效而灵活的分词引擎仍然非常困难. 当然,我在这方面不是专家,所以我不敢轻描淡写.
现在已经开发了机器学习技术,尤其是Google在深度学习领域具有领先优势. 过去,许多手动校准和分类任务都可以移交给算法. 从某种意义上说,可以完成本地化. 将来,深度学习技术也许可以自己学习和掌握本地化技能. 但是我想说两件事. 首先,从搜索引擎的历史角度来看,当深度学习技术还不成熟时,本地化工作非常重要,它也是决定竞争成败的重要因素. 其次,尽管深度学习现在非常强大,但是基于本地语言的手动参与,校准,测试和反馈仍然对深度学习的效率和有效性具有不可替代的影响.
除了分词之外,索引系统还具有一些重要点,例如实时索引,这是因为索引库的更新很重要. 一般的网站运营商都知道,他们的网站内容更新后,他们需要等待索引库的下一次更新才能看到效果,并且对于具有不同权重的网站内容,索引库将以不同的权重进行更新. 但是,在某些高优先级信息网站和新闻搜索中,索引库可以实现近实时索引,因此在新闻搜索中,可以在几分钟前搜索信息.

我曾经吐口水. 我在百度空间上发表的文章首先被Google索引. 当时,他们的解释是,猜测是因为许通过Google阅读器订阅了我的博客,而Google阅读了. 该设备可能是Google快速索引的切入点. (当然,百度空间消失了,谷歌阅读器消失了. )
索引系统的加权系统是所有SEOER中最关注的问题. 他们通常通过不同的方式组合策略,观察搜索引擎的集合,排名和返回的方式,然后通过比较分析来整理相关策略. 您可以写一篇很长的文章,但是今天我不会提及.
但是我说一个事实,许多从事SEO的外部公司会错误地认为,百度的人们熟悉这里的门道和法律. 很去百度的搜索产品经理和技术工程师那里以高价进行SEO. 呵呵外面的那些基层企业家在这方面有些擅长,而且他们的确比百度人更清晰. 搜索权重与更新频率等之间的关系,例如上文提到的千亿企业家By.
基于结果的后推策略,比不了解整个情况的参与者更有趣的是找到系统的关键点.
3. 查询显示
用户在服务器端在浏览器或移动客户端上输入关键字,几个关键字甚至一个句子,这是在服务器端,获取应答程序后的处理步骤如下
第一步是检查是否有人最近一次搜索了相同的关键字. 如果有这样的缓存,最快的处理就是为您提供该缓存,这样查询效率最高,并且对后端负载的压力最低.
第二步是输入查询最近没有被搜索过,或者由于其他条件而必须更新结果,那么将对用户输入的单词进行分段,是的,如果有多个关键字,或者如果是一个句子,则应答程序将再次拆分单词,并将搜索查询拆分为几个不同的关键字.
第三步是将划分的关键字分发到查询系统. 查询系统将转到索引库进行查询. 索引库是一个庞大的分布式系统. 首先分析此关键字属于哪个服务器和哪个服务器. 索引是数据的有序组合. 我们可以用近似二分法来思考. 无论数据大小如何,都可以使用二分法查找结果. 查询频率为log2(N),可确保海量数据. ,查询关键字非常快非常快. 当然,实际情况将比二分法复杂得多,因此更容易理解. 如果比较复杂,我不会告诉所有人,或者我不太清楚.
第四步,查询不同关键字的结果(仅对最前面的结果按权重排序,绝对不是全部结果),根据权重的倒序,将它们汇总在一起,然后将共同的命中反馈. 然后进行最终的重量排序.
请记住,搜索引擎将永远不会返回所有结果. 百度和谷歌都没人能负担这笔费用,翻页有一定的限制.
请记住,如果多个关键字中有不同类别的多个热门关键字,则搜索引擎可能会丢弃其中一个热门关键字,因为汇总数据可能不包含共同的结果. 搜索技术不是神话,这种范例偶尔会出现.
这是三个主要部分. 再说一遍,实际上是第四部分.
用户点击行为收集和反馈部分
基于用户的翻页,点击分布,确定搜索结果的质量并调整权重,但是此早期搜索引擎不可用,只有稍后才可用,因此未列为必填项.
此外,一些针对搜索,各种单词的识别,同音异义的识别等优化的机器学习策略也基于用户行为反馈. 这是一个以后的故事,我将不在这里扩展.
关于第四部分,我之前说过一个词,单击以增加权利,我说这个词值得很多钱,我想很都不理解. 我不明白,否则我会被一些同事骂.
以上是单个搜索引擎的工作原理以及一些技术逻辑. 当然,这只是入门级的解释. 毕竟,我无法深入解释. 更多SEO解释:

但是搜索引擎的本地化不仅限于搜索技术的本地化.
百度的力量不只是搜索技术. 当然,有人会说百度没有搜索技术. 我不会以这种言论来争论. 我不会试图改变任何人的观点. 我只列出一些事实.
百度的力量还来自两个主要方面,第一是内容护城河,第二是入口控制.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-267255-1.html
我必犯人”