spring disruptor_disruptor_disruptor sequence
电脑杂谈 发布时间:2017-01-16 07:09:34 来源:网络整理disruptor是LMAX的一个并发框架,在很难再继续压榨CPU的今天,disruptor显然又挑战了极限。LMAX可以达到单线程每秒6百万订单,用1微秒的延迟获得吞吐量为100K。真是让人惊叹不已。
那么,disruptor到底为什么这么强大呢,有很多文章都对其进行了描述(见参考)。
归结下来有这么几点:
1. 弃用锁机制转而使用CAS。
Disruptor论文中讲述了我们所做的一个实验。这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。当单线程无锁时,程序耗时300ms。如果增加一个锁(仍是单线程、没有竞争、仅仅增加锁),程序需要耗时10000ms,慢了两个数量级。disruptor更令人吃惊的是,如果增加一个线程(简单从逻辑上想,应该比单线程加锁快一倍),耗时224000ms。
所以锁的开销实际上已经被证实是非常的大了,如果减少锁的使用,降低锁的粒度,这是disruptor提供给我们的另外一种思路。
2. 为了解决伪共享而引入缓存行填充。
伪共享讲的是多个CPU时的123级缓存的问题,通常,缓存是以缓存行的方式读取数据,如图,当两个CPU同样都把X,Y load到自己的一级缓存时,实际上CPU为了争用X,Y还是会在写入时发生竞争,这样同样会导致锁,效率下降这些问题。
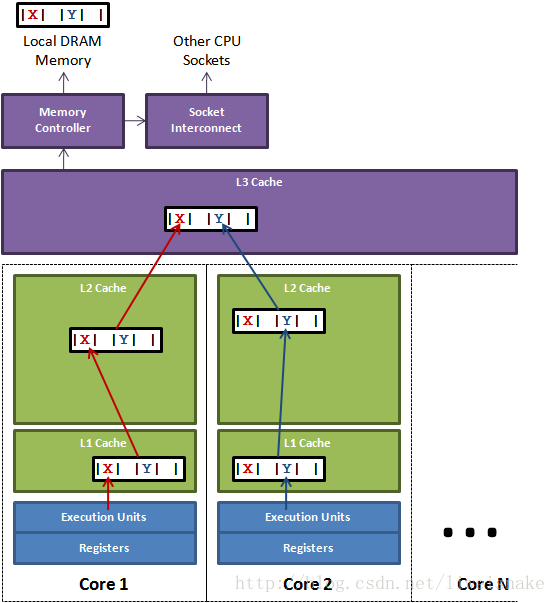
如何解决这个问题呢?实际上使用的是与内存对齐一样的方法,就是每次把数据对齐到跟缓存行(通常是64B)一样大小。disruptor其实内存对齐和解决伪共享的缓存行对齐其实是同一种思路。所以在disruptor源码中可以看到这样一个内部类,它为什么写成这样,其实就是为了缓存行对齐。
private static class Padding
{
/** Set to -1 as sequence starting point */
public long nextValue = Sequence.INITIAL_VALUE, cachedValue = Sequence.INITIAL_VALUE, p2, p3, p4, p5, p6, p7;
}
3. 使用一种独特的数据结构RingBuffer来代替Queue。这个数据结构的使用使得弃用锁转而用CAS成为了可能。
大家可以想象,如果要自己编写一段生产者消费者的程序,你会怎么做呢?
当然了,大多数人都会用一个队列来实现,说白了,就是把队列作为生产者和消费者之间的缓冲,从而间接的同步了他们的速度,使得异步编程成为可能。
说到异步编程,可能大家都再熟悉不过了,实际上java的图形界面就是一个典型的异步编程的例子,作为处理界面事件的消费者其实只有一个线程,而更新界面的生产者会是多个线程,由于采用了生产者消费者模型,生产者生产的界面事件会保存在一个队列里,由这个内置的线程统一去做更新,这样就保证了我们编程时不会人为破坏界面绘制的过程,从而提高代码质量,降低复杂度。顺带一提,.net的delegate也是同样的道理,如果用其他线程更新界面会出现很多怪异的问题,所以delegate通过一个事件队列,同样实现了消费者在一个单独的线程中。
扯远了。总之我们会使用一个队列来处理这种问题,这里存在几个问题,第一,如果生产者生产过快,一定时间后,队列会变得过度膨胀,占用内存空间;第二,看过队列的实现会发现,为了保证多个线程访问的正确性,在操作队列时是一定要加锁的,前面也说了,加锁以后时间会慢几个量级。
disruptor框架的设计带我们走出了这个思维定势。我们一定要用不断增长的队列吗?我们访问队列一定要加锁吗?答案都是否定的。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-26630-1.html
-

-
徐凯琳
~
-
李元膺
你是老百姓
-
欢快鼓舞