了解Tensorflow分布式原理
电脑杂谈 发布时间:2020-06-21 13:05:00 来源:网络整理
【IT168技术】1. Tensorflow原理
实施原则
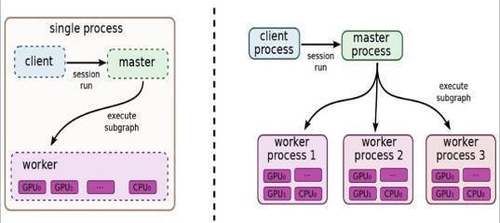
图1.1 TensorFlow独立版本和分布式版本的示例图
TensorFlow计算图的运行机制
客户
客户端基于TensorFlow编程接口构造一个计算图. 目前,TensorFlow尚未执行任何计算. 在建立会议会话并将会议用作桥接之前,将建立客户端与后端之间的通道,并将Protobuf格式的GraphDef发送到分布式主机. 也就是说,当客户评估OP结果时,将触发分布式母版计算图的执行过程. 如下图所示,Client构建了一个简单的计算图. 首先将w和x矩阵相乘,然后将截距b按位相加分布式计算原理是什么,最后更新为
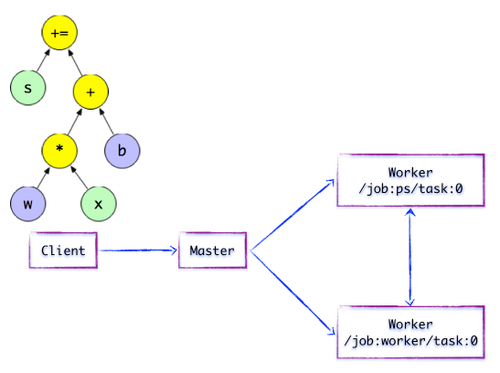
图1.2分布式Master的简单TensorFlow计算图

在分布式运行时环境中,Distributed Master根据Session.run的Fetching参数从计算图向后遍历,以找到它所依赖的最小子图. 然后,分布式主控器负责将子图像分成多个“子图像段”,以便在不同的进程和设备上运行这些“子图像段”. 最后,分布式母版将这些图片片段分配给工作服务. 然后,工作服务启动“本地子图片”的执行过程. 分布式主服务器将缓存“子图片片段”,以便后续执行过程可以重用这些“子图片片段”以避免重复计算.
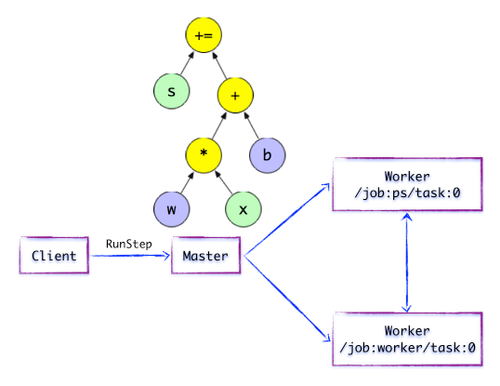
图1.3简单的TensorFlow计算图---开始执行执行图计算
如上图所示,Distributed Master开始执行计算子图. 在执行之前,Distributed Master会执行一系列优化技术,例如“通用表达式消除”,“恒定折叠”等. 随后,Distributed Master负责任务集的协调并执行优化的计算子图.
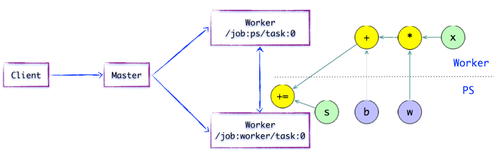
图1.4简单的TensorFlow计算图-图像子部分子图像部分
如上图所示,有一个合理的“子图片片段”划分算法. Distributed Master将与模型参数相关的OP分组,并将其置于PS任务上. 其他OP分成另一个组,放在任务上执行.
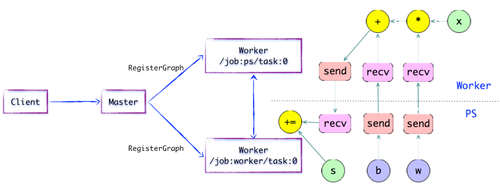
图1.5简单的TensorFlow计算图---如上图所示插入SEND / RECV节点,如果计算图的边缘被任务节点划分,则Distributed Master将负责拆分边缘,在两个分布式任务在它们之间插入SEND和RECV节点以实现数据传输.

然后,分布式主机将“子画面段”分配给相应的任务以执行,并且工作程序服务变为“本地子画面”,其负责在子画面上执行OP.
工人服务
对于每个任务,将有一个相应的工作人员服务,主要负责以下三个职责:
处理主的要求;
安排OP的内核实现以执行本地子图;
协作任务之间的数据通信.
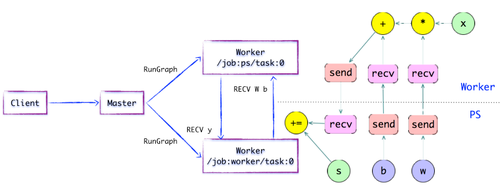
图1.6简单的TensorFlow计算图---执行本地子图
执行本地子图工作者服务以将OP调度到本地设备并执行特定于内核的操作. 它将尽可能利用多个CPU / GPU的处理能力来同时执行内核实现.
此外,TensorFlow根据设备类型专门研究设备之间的SEND / RECV节点:
使用cudaMemcpyAsync的API实现本地CPU和GPU设备之间的数据传输;

对于本地GPU,端到端DMA用于避免在主机CPU上进行昂贵的复制过程.
对于任务之间的数据传输,TensorFlow支持多种协议,主要包括:
基于TCP的gRPC
融合以太网上的RDMA
示例代码
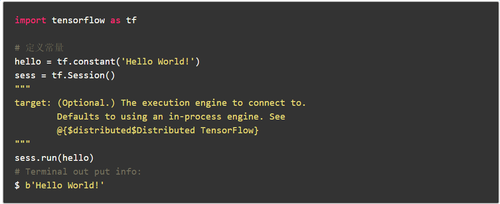
上面的短代码实际上已经应用于Tensorflow分布式结构,但是分布式客户端,主服务器和工作器都在同一台本地计算机上. 而且多台机器只需要指定相应的客户端即可实现分发. 主作业和工人作业可以分布在不同的机器上. 下面将详细介绍如何在多台机器上实现Tensorflow分发.
3. Tensorflow分布式图形复制(图片内复制)
GRPC
如上所述,Tensorflow的独立模式是将客户端,主服务器和工作器放置在同一台计算机上,而分布式模式是将三台计算机分发到多台计算机. 此时,有必要先考虑多台机器的通讯问题. Tensorflow发行版中常用的通信协议是gRPC协议. gRPC是Google开发的开源RPC(远程过程调用)协议. 该协议允许一台计算机上运行的程序调用另一台计算机的子程序,而程序员不必对此交互进行编程.
在图形内复制
Tensorflow训练模型通常需要一些训练参数. 有两种分配训练参数的方式: 在图形内复制和在图形间复制. 其中,图形复制模式下的数据分发位于一个节点上. 这具有简单配置的优点. 其他多机和多GPU计算节点仅需要启动连接操作并公开网络接口,然后等待在那里接受任务. 但是这样做的缺点是训练数据分布在一个节点上,并且训练数据必须分布在不同的机器上,这严重影响了并行训练的速度. 对于大数据训练,不建议使用此模式.

示例代码1自动节点分配策略-简单的贪婪策略成本模型估计
worker_01
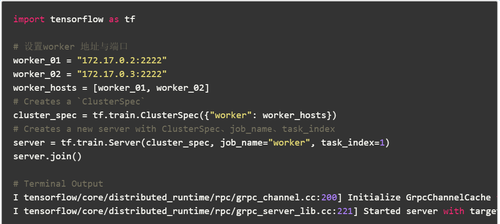
worker_02
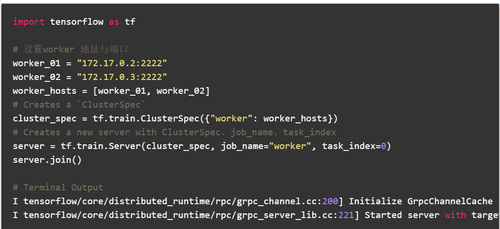
客户
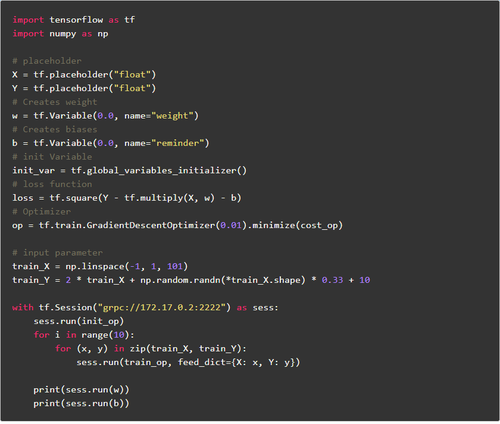
从上面的示例代码中我们可以看到: 这里使用三台机器进行培训,一名clin,两名工人可能在这里遇到一些问题: 问题1.主在哪里?问题2.如何分配每个节点的任务?对于问题1,在该图的复制模式下,最主要的实际上是使用tf.Session(“ grpc: //172.17.0.2: 2222”)作为sess: 这句话中指定的目标,也就是172.17 .0.2: 2222这台计算机是主计算机,运行时将在此计算机上打印以下日志: I tensorflow / core / distributed_runtime / master_session.cc: 1012]使用配置启动主计算机会话254ffd62801d1bee: 对于问题2,
计算已从单机多GPU扩展到多机多GPU. 只要在操作过程中指定了tf分布式计算原理是什么,这些计算节点公开的网络接口就可以像使用本地GPU一样使用. device(“ / job: worker / task: n”),您可以将操作分配给指定GPU的计算节点,类似于多GPU.
示例代码2用户受限节点分配策略
3. Tensorflow分布式图间副本(图间副本)
在图形间模式下,训练参数存储在参数服务器中,不需要分发数据. 数据碎片存储在每个计算节点中. 每个计算节点都计算自己的节点. 计算完成后,将要更新的参数告知参数服务器,参数服务器更新参数. 这种模式的优点是不需要分发训练数据,尤其是当数据量在TB级时,这样可以节省大量时间,因此仍然建议使用大数据深度学习使用图间关系模式.
参考
[1]: TensorFlow架构和设计: 概述和简单描述
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-253330-1.html
-

-
白石稔
甲午海战前
-
王运庆
知道为什么中共对所谓的岛内运动不屑一顾吗
-
 最新版:用于重新安装系统win10旗舰版的官方教程
最新版:用于重新安装系统win10旗舰版的官方教程 英国暑期课程“这里医疗设施先进,环境好,距离北京也近,儿女看
英国暑期课程“这里医疗设施先进,环境好,距离北京也近,儿女看 户籍个人信息大连MS尚美婚纱摄影,7MO婚嫁网会员商家。大连
户籍个人信息大连MS尚美婚纱摄影,7MO婚嫁网会员商家。大连 管理信息系统作业 舟山到北海13161947776.整车零担.直达
管理信息系统作业 舟山到北海13161947776.整车零担.直达
你是老百姓